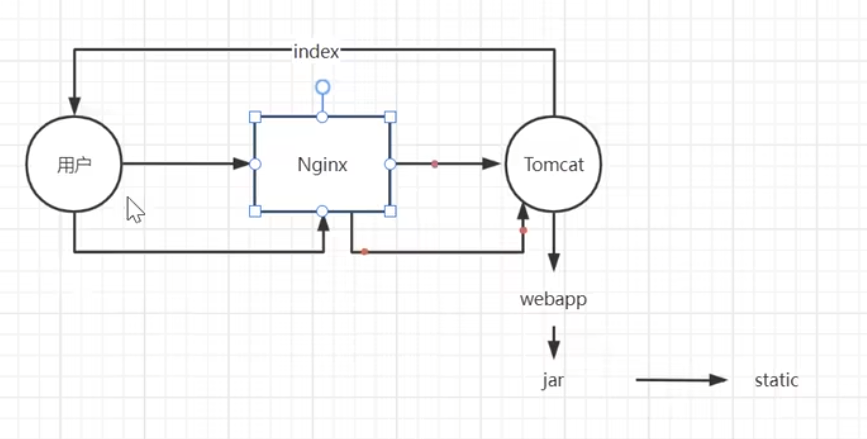
Nginx
Nginx简介
应用场景:在互联网项目中担任高性能服务器、负载均衡器,在大型系统架构担任高性能流量网关、应用网关、日志服务器、文件存储服务器等,支持模块化扩展和复杂功能的二次开发,通过简单调优就能高效提升系统性能
nginx是普通程序员进阶高程和架构师的捷径,nginx本身调优没啥用处,需要配合操作系统联动调优
nginx的官方文档:https://nginx.org/en/docs/,文档分为非常多的模块,官网中的很多配置,网上的文章都没有涉及,官方文档的解释有时候很模糊,很多时候表达都很模糊并且没有配备实际的场景
nginx官方中文文档:HttpGzip模块 | Nginx 中文官方文档 (gitbooks.io)
CentOS是linux发型版本中比较流行的版本,使用的redhat的linux内核,迷你版的linux系统非常干净,连网卡都没法用
使用命令
ip addr能够查看当前系统的ip环境,lo
Linux系统的Lo接口
在LINUX系统中,除了网络接口eth0,还可以有别的接口,比如lo(本地环路接口)。环回地址lo是主机用于向自身发送通信的一个特殊地址(也就是一个特殊的目的地址)。
本地回环地址指的是以127开头的地址(127.0.0.1 – 127.255.255.254),通常用127.0.0.1来表示。127.0.0.1,通常被称为本地回环地址(Loop back address),不属于任何一个有类别地址类。它代表设备的本地虚拟接口,所以默认被看作是永远不会宕掉的接口。
Lo接口的作用
通常在不安装网卡前就可以ping通这个本地回环地址。
一般都会用来检查本地网络协议、基本数据接口等是否正常的。测试本机的网络配置,能PING通127.0.0.1说明本机的网卡和IP协议安装都没有问题。
提供一个回环接口,很多需要网络的程序(比如mpd,xmms2),需要这个接口来通信。
Nginx的版本
Nginx常用的有四个发行版本,
Nginx开源版:http://nginx.org
最原始的版本,什么额外的功能都没有,主要功能就是成为网站服务器、代理服务器和负载均衡器,做二次开发难度大,需要集成很多的第三方组件,所以有很多公司对nginx在该版本的基础上做了加强
Nginx plus商业版:https://www.nginx.com
F5官方出品【F5是硬件厂商,专门做负载均衡器】,该版本对微服务和云原生的整合,对k8s的整合非常的好,但是收费
Openresty:http://openresty.org
免费开源,主要讲nginx和lua脚本进行了完美整合,Nginx Plus中的功能基本用户自己也可以进行开发,用lua脚本开发优雅高性能,代码难度小,也支持个性化定制,还有中文官网
Tengine:http://tengine.taobao.org
免费开源,没有二次开发的需求,只要求性能稳定,集群负载均衡、反向代理在原版基础上更安全、更稳定、性能更高可以使用tengine,这是淘宝开发出来的【相当于原版的增强】,以C语言的形式,模块化开发扩展原始nginx的功能
Nginx的安装
使用nginx1.20.2,安装包下载:http://nginx.org/en/download.html
安装步骤
基础部分学习使用最原始版本
将nginx的安装包
nginx-1.20.2.tar.gz上传到linux的/opt/nginx目录下使用命令
mkdir /usr/local/nginx创建/usr/local/nginx目录使用命令
tar -zxvf nginx-1.20.2.tar.gz解压文件到/opt/nginx目录进入解压目录,进入nginx解压文件,使用命令
./configure [--prefix=/usr/local/nginx]【--prefix是可选项,指定安装目录】尝试检查是否满足安装条件,期间会提示缺少的依赖,以下是需要依赖的安装成功安装的标志是没有报错
使用命令
yum install -y gcc安装c语言编译器gcc【-y是使用默认安装,不提示信息】使用命令
yum install -y pcre pcre-devel安装perl库【pcre是perl的库】使用命令
yum install -y zlib zlib-devel安装zlib库检查没有问题后执行命令
make进行编译执行
make install安装nginx
安装成功测试
使用命令
cd /usr/local/nginx进入nginx安装目录,查看是否有相应文件进入sbin目录,使用命令
./nginx启动nginx服务启动时会启动多个线程
使用命令
systemctl stop firewalld.service关闭防火墙服务虚拟机是内网上的机器,外网接不进来,关闭防火墙不一定意味着不安全,当然放行端口80更完美;学习过程不需要开启,生产的时候多数时候也不需要开启,除非机器有外网直接接入,或者公司比较大,要防外边和公司里的程序员,可能开启内部的监控和日志记录,一般中小型公司是不会开内网的防火墙的,因为有硬件防火墙或者云的安全组策略
使用请求地址
http://129.168.200.132:80访问nginxnginx的默认端口就是80端口,一定要关梯子进行访问,靠北
使用命令
./nginx -s stop快速停止nginx使用命令
./nginx -s quit在退出前完成已经接受的链接请求如用户下载文件,等用户下载完成后再停机,此时不会再接收任何新请求
使用命令
./nginx -s reload重新加载nginx配置可以让nginx更新配置立即生效而不需要重启整个nginx服务器,机制是执行过程中优雅停止nginx,保持链接,reload过程开启新的线程读取配置文件,原有线程处理完任务后就会被杀掉,加载完最新配置的线程继续杀掉线程的工作
此时启动nginx比较麻烦,需要使用nginx的可执行文件,意外重启的时候很麻烦,需要登录到控制台手动启动,将nginx安装成系统服务脚本启动就会非常简单
使用命令
vim /usr/lib/systemd/system/nginx.service创建服务脚本粘贴文本普通模式粘贴可能丢字符,插入状态粘贴就不会丢字符 WantedBy=multi-user.target 属于[install],shell脚本不能有注释,否则无法设置开机自启动
x[Unit]Description=nginx - web serverAfter=network.target remote-fs.target nss-lookup.target[Service]Type=forkingPIDFile=/usr/local/nginx/logs/nginx.pidExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.confExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.confExecReload=/usr/local/nginx/sbin/nginx -s reloadExecStop=/usr/local/nginx/sbin/nginx -s stopExecQuit=/usr/local/nginx/sbin/nginx -s quitPrivateTmp=true[Install]WantedBy=multi-user.target使用命令
systemctl daemon-reload重新加载系统服务并关闭nginx服务使用命令
systemctl start nginx.service用脚本启动nginx【启动前注意关闭nginx,避免发生冲突】使用命令
systemctl status nginx查看服务运行状态使用命令
systemctl enable nginx.service设置nginx开机启动nginx.service中的[Install]部分中的WantedBy=multi-user.target不能有注释,不能拼写错误,否则无法设置开机自启动
Nginx的基础用法
Nginx的目录结构
/usr/local/目录相当于windows的programfile目录,主要是为了方便管理
nginx的主要目录

其中以temp结尾的目录都是运行过程生成的临时文件
conf是核心配置文件的存放目录,里面放着nginx的主配置文件nginx.conf,该文件里面会引用其他的配置文件,
nginx中的一切几乎都可以配置,比如日志文件放在哪儿,日志记录的格式,日志文件的大小,包括pid以及存放位置都可以进行配置
html目录中放一些网页和静态资源,其中的index.html就是nginx正常启动访问80端口的欢迎页,这个目录在使用的过程中都会进行更改
logs目录用来记录日志,
acess.log是用户访问的日志【记录用户访问的时间、请求的文件、访问是否有附加的参数】,每个人的每次访问都会记录在其中,不能在让这个文件无限扩增,在配置文件中可以对文件大小和记录位置进行配置,不配置当记录到达磁盘大小时可能因为用户访问日志无法记录而出现各种莫名其妙的问题【磁盘满了内部无法记录日志而无限的报错】,此时配置可以限制日志文件大小并转移记录到其他文件当系统出现错误的时候会将用户访问错误信息和状态码记录到
error.log文件中niginx.pid是用于记录nginx运行的主进程id号,第二个数字1090就是nginx的主进程nginx: master的pid,这个进程号也可以配置

sbin目录只有nginx一个文件,作为nginx的主程序,用来启动nginx,也是nginx的主进程文件
编辑nginx欢迎页
使用xftp可以在线以记事本的形式编辑文本文件
将index.html编写成"hello world"

Nginx的运行原理
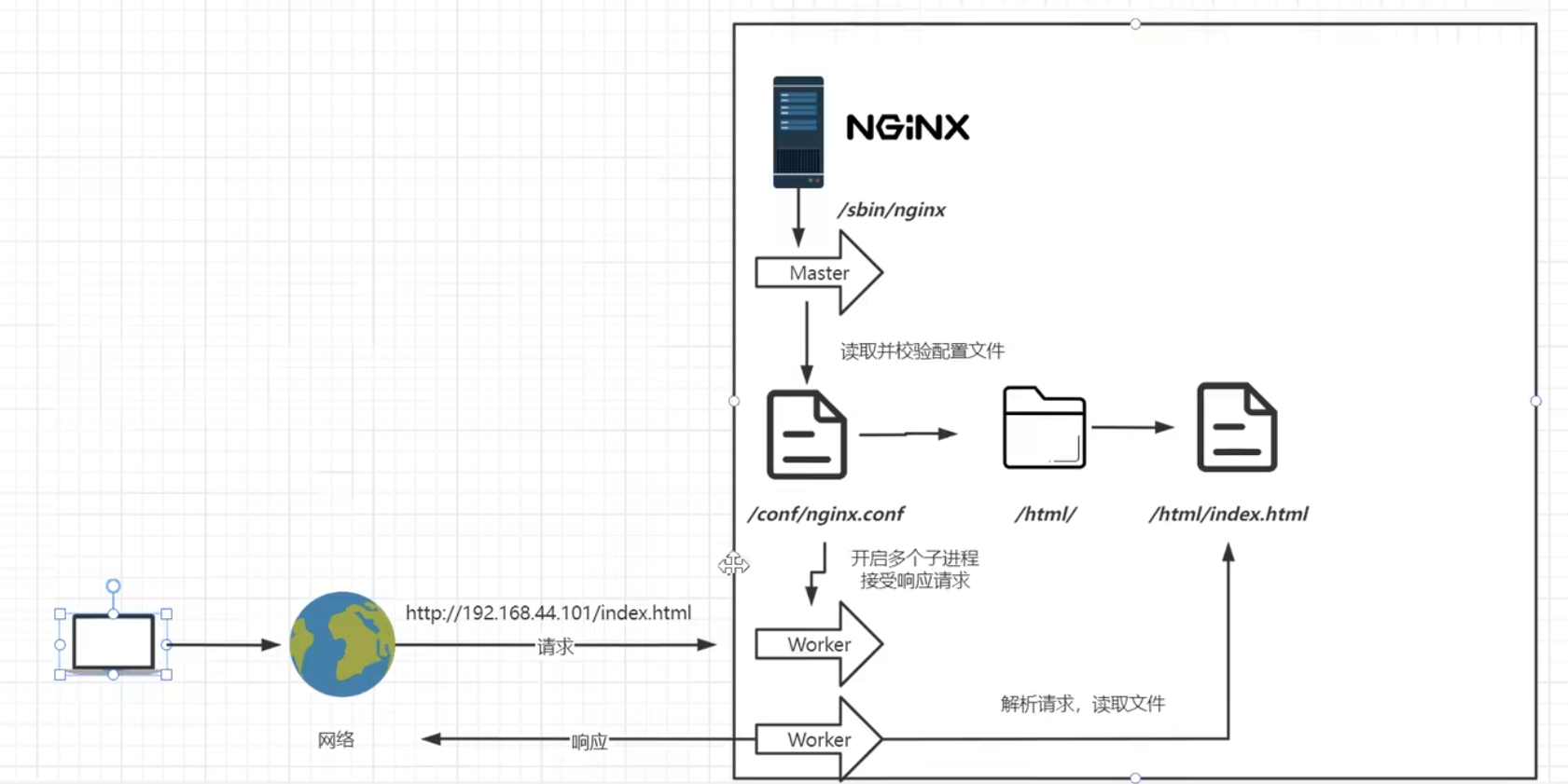
nginx的原理架构图
访问虚拟机也是通过网络请求由请求地址访问到的nginx
nginx的可执行文件运行后后开启一个master主进程,主进程会读取主配置文件,对配置文件做一次校验检查配置文件是否存在错误,没有错误会开启子进程worker;主进程不会处理业务,负责协调worker进程执行业务;【如配置文件更改后重新加载,会优雅的杀掉当前的worker进程,生产新的worker进程去读取新的配置文件接替旧的子进程的工作】
worker进程启动后会等待用户请求,worker通过解析配置文件判断用户请求是否能够处理,worker目录会去配置文件中查找当前存在哪些站点,并根据用户请求去获取对应的资源【即通过配置文件去html目录找到index.html这个资源】,并将资源响应给用户
Nginx的基础配置
核心配置文件
nginx.conf最小配置
#是注释,nginx.confg中不带#的部分,也是能满足nginx正常运行的最小化配置文件版本xxxxxxxxxx#配置nginx在启动的时候需要启动多少个worker子进程,这个参数基本会设成对应当前服务器对应的CPU内核数,如果虚拟机只有一个内核,此时分配10个子进程,没有意义,因为一个内核分成10个时间段去处理十个进程效率反而会变低;基本的配置逻辑就是一个Cpu内核对应一个子进程worker_processes 1;#events是事件驱动模块,worker_connections指的是每个worker进程最多可以创建多少个连接,默认就是1024,一般不需要动events {worker_connections 1024;}#http模块,http {#include命令可以将后面的配置文件引入到当前的配置文件中,后续会使用include引入其他配置文件,一个配置文件写的内容过多不便于后续配置的管理,且多个对象对同一个配置文件进行更改需要竞争锁,但是多个配置文件可以各自改各自的,这样设计效率更高;mime.types是所有http协议的头标注的文件类型,这个头中会包含服务器返回给客户端的文件类型,如文本文档、html文档,可执行程序或flash文件,这个头的信息有服务器发送给浏览器告诉浏览器这是一个什么文件,由服务器定义;服务器传递给浏览器的文件是0101类型的字节码,浏览器只看文件后缀是看不懂具体是什么文件,必须通过服务器在协议头中加上当前传输文件的文件类型、如图片就加img、jpg到协议头中;不同的类型效果也会不同,图片的.png会直接在浏览器展示出来,不会直接下载;如果是.exe会弹出下载框对文件进行下载;但实际展示还是下载的行为不是由后缀决定的,是由协议头中的mime.types决定的,该类型可以对应到文件的后缀名include mime.types;#mime.types不可能包含所有的类型,如果实在没有匹配的类型,就使用默认的类型以application/octet-stream;以数据流的方式传递给浏览器default_type application/octet-stream;#开启sendfile功能,数据直接读取到网络接口,不走nginx内存sendfile on;#不做详细介绍,理解成保持链接超时的时间,将反向代理再细讲这个问题keepalive_timeout 65;#http模块下的server模块,一个server表示一个主机,一个nginx可以同时运行多个主机,这种开启多个主机的方式称为虚拟主机,虚拟主机又称为VHost,server {#nginx当前服务器监听的端口号,可以通过端口号来区分不同的主机,比如可以设置下一个主机在8080端口运行,主机的端口号不能重复,nginx服务就启动不起来listen 80;#server_name指的是当前主机的主机名,可以写域名或者主机名。必须要能解析,localhost能解析是因为计算机的Hosts文件中定义了localhost的映射是127.0.0.1#server_name是指检测到别人访问到某个域名如blog.concurrecy.cn就会跳转到对应的server下server_name localhost;#location表示一个主机有一个独立的站点,相互之间互不干扰,暂时理解为域名后的根路径或者整体看做uri【专业就叫uri,就是请求路径端口号之后的部分】,location是用来完整或者模糊匹配uri的,一个主机下可以配置很多个location,可以配置到不同目录下相互之间还不影响location / {#root是配置用户请求进来之后从哪个目录下去找相应的网页,初始设置的就是html目录,即欢迎页所在目录,这个路径是一个相对路径,html是相对于nginx的主目录`/usr/local/nginx`目录下的html目录root html;#该index只对当前location生效,对应html目录下的index.html页面index index.html index.htm;}#error_page是发生服务端错误的时候,50x错误码,对于列举的500 502 503 504四个错误码会转向到当前站点的/50x.html地址,这个地址相当于替代整个uri部分,相当于跳转http://192.168.200.132:80/50x.htmlerror_page 500 502 503 504 /50x.html;#一旦用户请求的uri为/50x.html就会去以html为根目录去找html中的50x.htmllocation = /50x.html {root html;}}}mime.types
前一个是协议头中的mime.type类型,后一个是文件后缀名
可以设置自定义文件后缀指定现有mime.type实现浏览器以视频的方式直接播放自定义后缀mp5的文件的能力
xxxxxxxxxxtypes {#返回文件的后缀名为html,就在返回的HTTP头中加入该文件类型是text/html,告诉浏览器用text/html的方式来解析当前响应的文件text/html html htm shtml;text/css css;text/xml xml;image/gif gif;image/jpeg jpeg jpg;application/javascript js;application/atom+xml atom;application/rss+xml rss;text/mathml mml;text/plain txt;text/vnd.sun.j2me.app-descriptor jad;text/vnd.wap.wml wml;text/x-component htc;image/png png;image/svg+xml svg svgz;image/tiff tif tiff;image/vnd.wap.wbmp wbmp;image/webp webp;image/x-icon ico;image/x-jng jng;image/x-ms-bmp bmp;font/woff woff;font/woff2 woff2;application/java-archive jar war ear;application/json json;application/mac-binhex40 hqx;application/msword doc;application/pdf pdf;application/postscript ps eps ai;application/rtf rtf;application/vnd.apple.mpegurl m3u8;application/vnd.google-earth.kml+xml kml;application/vnd.google-earth.kmz kmz;application/vnd.ms-excel xls;application/vnd.ms-fontobject eot;application/vnd.ms-powerpoint ppt;application/vnd.oasis.opendocument.graphics odg;application/vnd.oasis.opendocument.presentation odp;application/vnd.oasis.opendocument.spreadsheet ods;application/vnd.oasis.opendocument.text odt;application/vnd.openxmlformats-officedocument.presentationml.presentationpptx;application/vnd.openxmlformats-officedocument.spreadsheetml.sheetxlsx;application/vnd.openxmlformats-officedocument.wordprocessingml.documentdocx;application/vnd.wap.wmlc wmlc;application/x-7z-compressed 7z;application/x-cocoa cco;application/x-java-archive-diff jardiff;application/x-java-jnlp-file jnlp;application/x-makeself run;application/x-perl pl pm;application/x-pilot prc pdb;application/x-rar-compressed rar;application/x-redhat-package-manager rpm;application/x-sea sea;application/x-shockwave-flash swf;application/x-stuffit sit;application/x-tcl tcl tk;application/x-x509-ca-cert der pem crt;application/x-xpinstall xpi;application/xhtml+xml xhtml;application/xspf+xml xspf;application/zip zip;#octet-stream以数据流的方式去加载并提示用户是否需要下载下来application/octet-stream bin exe dll;application/octet-stream deb;application/octet-stream dmg;application/octet-stream iso img;application/octet-stream msi msp msm;audio/midi mid midi kar;audio/mpeg mp3;audio/ogg ogg;audio/x-m4a m4a;audio/x-realaudio ra;video/3gpp 3gpp 3gp;video/mp2t ts;video/mp4 mp4;video/mpeg mpeg mpg;video/quicktime mov;video/webm webm;video/x-flv flv;video/x-m4v m4v;video/x-mng mng;video/x-ms-asf asx asf;video/x-ms-wmv wmv;video/x-msvideo avi;}数据传输过程
Nginx作为一款软件跑在linux系统上,请求从客户端通过ip找到linux服务器,由操作系统的网络接口将请求转发到nginx,在启动java网络程序的过程中会向操作系统注册一个端口,相当于告诉操作系统,有请求过来要通过请求对应端口转发给该程序
nginx拿到请求解析后通过配置文件找资源的目录,想要将该资源文件响应给用户,从找到该文件开始就开始决定是否开启sendfile的过程,sendfile开启和不开启的流程是不同的
不开启sendfile的情况下,分为read和write两个过程,read是nginx去读对应的文件,将完整文件加载到nginx应用程序的内存中,读完之后将当前的文件发送给计算机操作系统的网络接口【即网卡的驱动程序】,期间还会经历DMA的调度和网卡驱动程序以及内核缓存的一个过程,存在文件内容的二次复制,读取到nginx内存一次,复制给网络接口缓存一次【不同进程间如果不使用共享内存,内存不能相互访问,所以这里是必定多了一次拷贝的。】
【不开启sendfile下的流程】
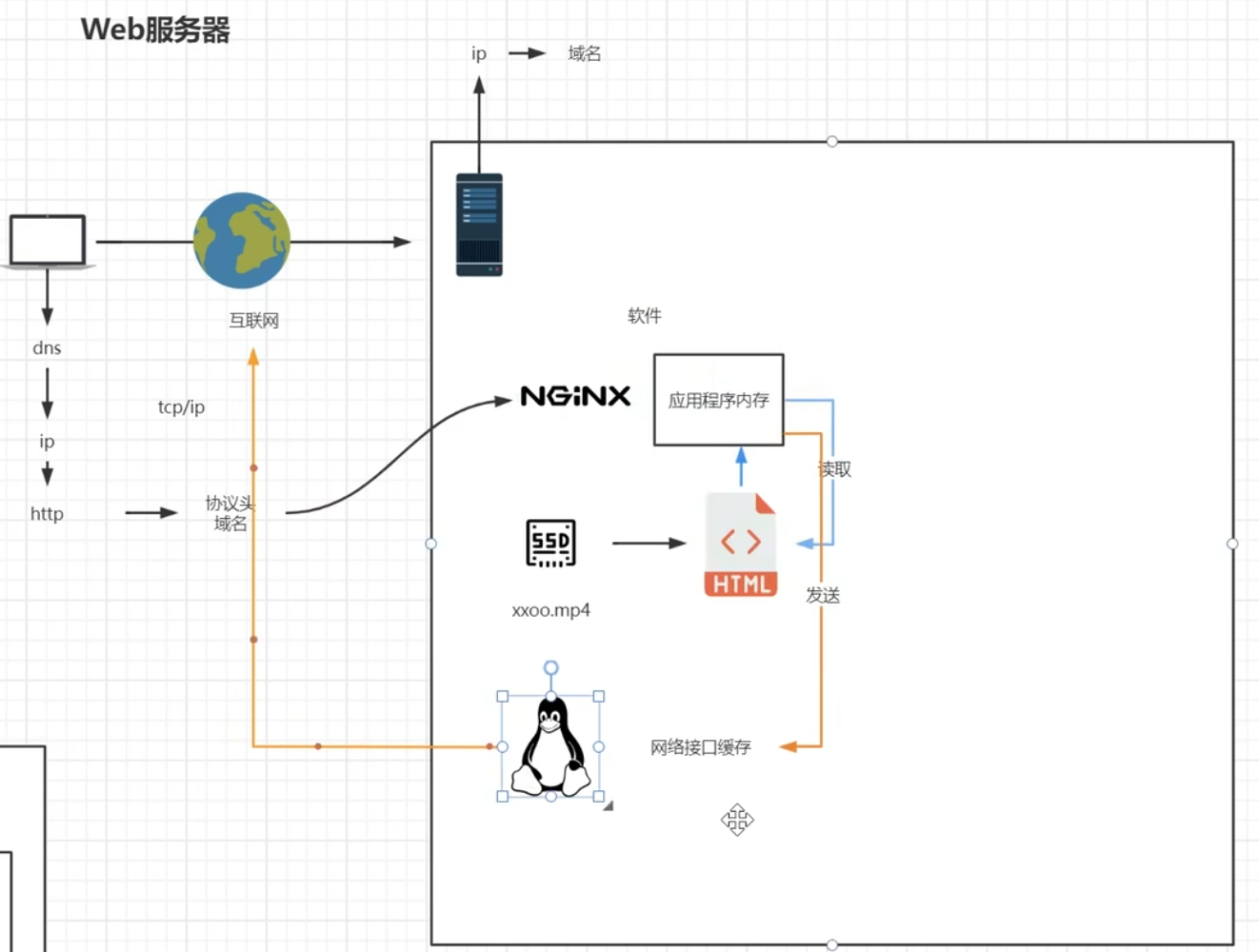
【开启sendfile下的流程】
开启sendfile的过程是不需要nginx复制到自身内存再复制给网络接口缓存的过程,nginx不去读取相应文件,而是通过nginx向操作系统内核发送一个信号【执行sendfile方法向网络接口传递socket和文件位置】,由网络接口来读取对应的文件直接将文件发送给客户端
先将数据写入到内核态的缓存中,然后直接写入到socket缓存,socket缓存再发送到网卡,网卡再执行转发,就是在内核状态,将数据直接读取给网卡,而不是用户态->内核态->数据->内核态->用户态->内核态->网卡;少了一次读到应用内存的次数,减少了应用内存的消耗【来自弹幕组合分析,再深入了解一下零拷贝的概念,操作系统和计算机原理的知识】
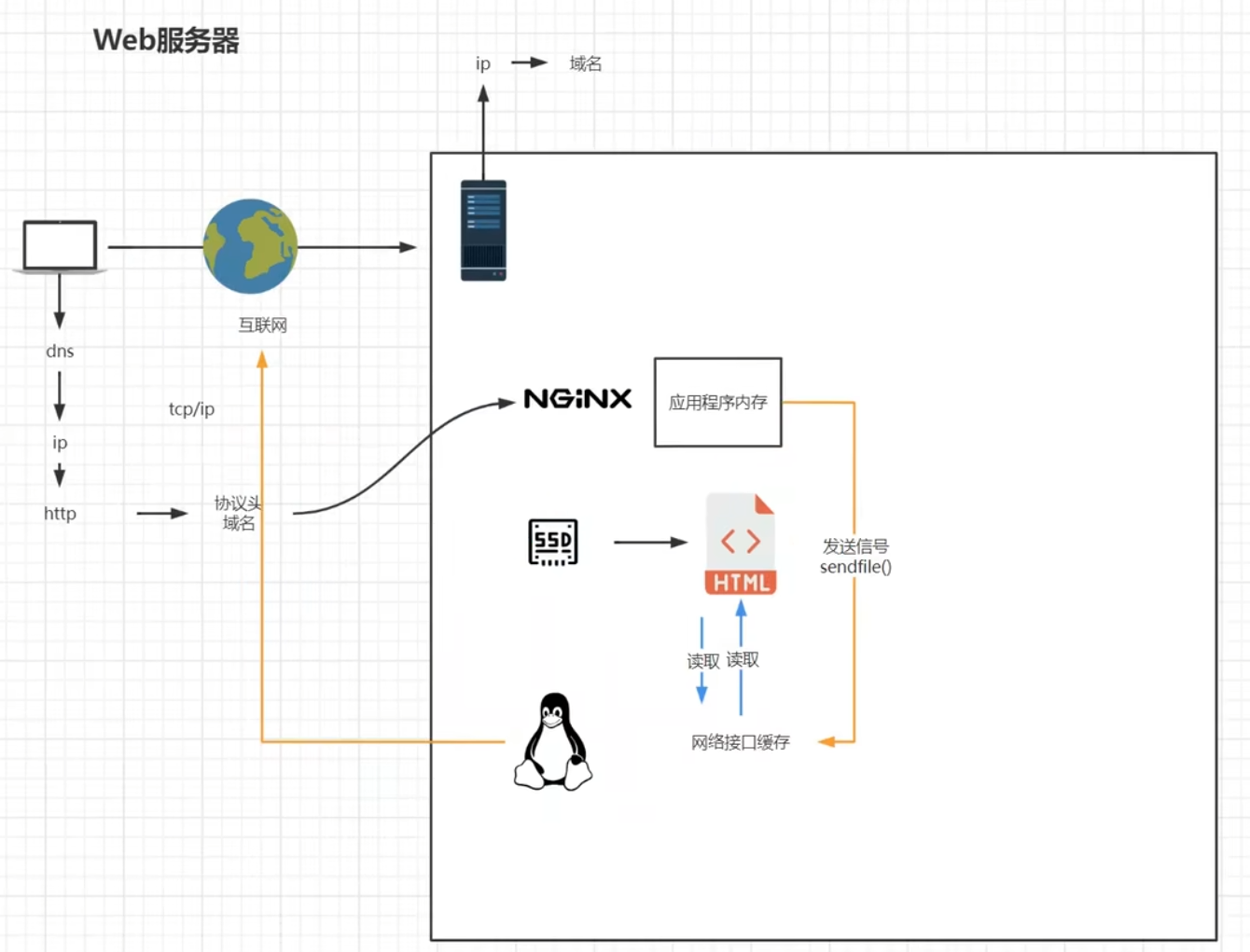
虚拟主机与域名解析
本地域名配置解析
这个比较假,只能内网用,公网是无法访问的
浏览器请求过程
电脑从DNS服务器拿到ip地址,会发起tcp/ip请求,
HTTP协议在tcp/ip协议之上,HTTP协议是高级的网络协议,tcp/ip协议叫做基础的网络协议,不能叫低级,基础的含义是能兼容一切上层的协议,HTTP的应用广泛,几乎所有上网的设备都支持HTTP协议,nginx和浏览器都实现了HTTP协议,
tcp/ip协议规定了网络只能传递二进制的数据,数据以数据流的形式发送给目标服务器,流的含义就像一段水流一样,tcp/ip协议中并没有对数据传递结束的约束和限制
HTTP协议中最重要的规定是通信双方数据传递结束的标准,类似与说一段话,话怎么开始,怎么结束,需要用协议规范;HTTP协议中请求数据的数据报文究竟有多长会直接写在HTTP协议中,HTTP协议是上层的高级应用协议,其中包含的约束比较多,约束了通信双方都要按照一定规则传递数据,
HTTPS协议在HTTP协议的基础上额外增加了一层数据安全的保障,路由器就是一层网关,需要通过路由器接入互联网,路由器也不是直接接入主干网,在接入主干网之前还要接入小区的网关,服务供应商的网关,区一级的网关,市一级的网关,再到全国的总的网关入口,才能接入到主干网,网关传递数据非常多,用HTTP协议能被网关劫持解析数据看见个人隐私数据,又比如转账消息,因此在原有HTTP协议的基础上考虑到安全又弄出了Https协议【后续详细讲】
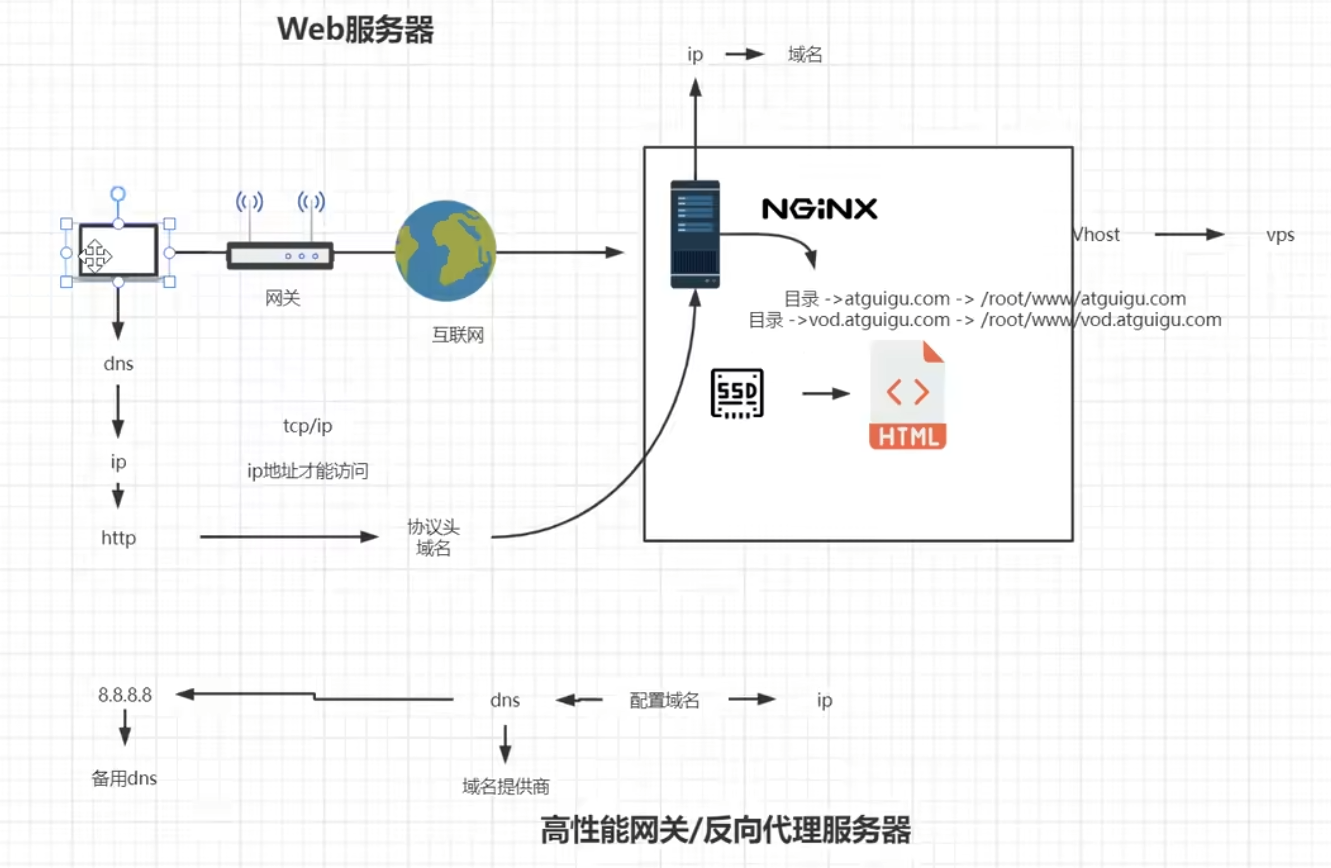
虚拟主机
一台主机上开一个站点,可能压根就没多少人访问,对资源是极大的浪费,
虚拟主机是将一台真实主机虚拟出来多台主机,一台虚拟主机对应一个域名【ip】,外部请求访问虚拟主机时让多个域名对应同一个真实的主机ip,由主机上的nginx来根据请求域名进行判断请求究竟要访问那个虚拟主机,nginx将请求对应指向不同站点的目录响应对应的资源即可
配置域名解析
因为买不到域名,相当于在自己的系统里玩,外网访问不到
域名解析配置在windows的hosts文件中
因为在hosts中已经配置了域名对应的ip,以后本机访问
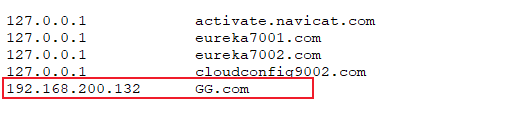
eureka7001.com就不会再去DNS服务器中进行查找,而直接从hosts文件中拿,这个就叫本地域名解析在hosts文件中设置虚拟机的ip:
192.168.200.132对应的域名为GG.com,在浏览器访问http://GG.com/就能直接访问虚拟机上启动的nginx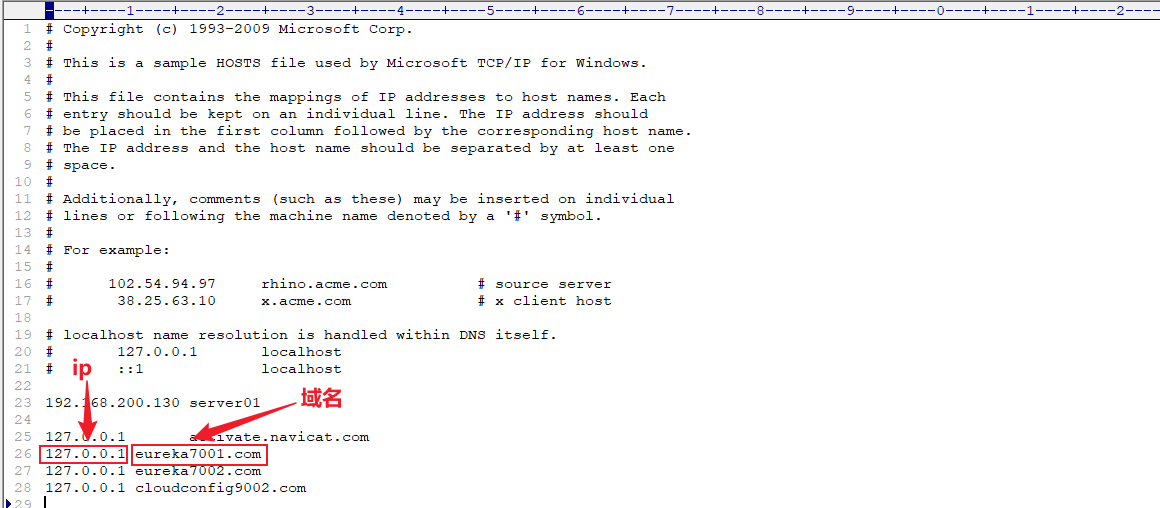
修改hosts域名解析
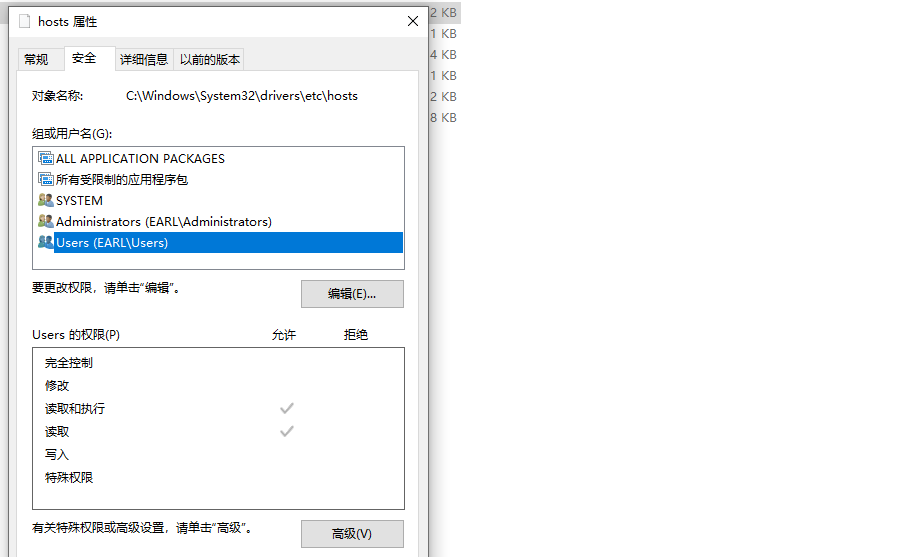
系统目录下文件更改需要的权限比较高,可以更改该文件的编辑权限,点击hosts,右键属性,在安全选项卡下,SYSTEM和Administrators都有修改的权限,但是users没有修改权限,只要添加用户组的修改权限用户就能更改该文件,选中users点击编辑勾选完全控制即可使用户获得系统文件的全部权限,改完系统文件最好再还原回来【只勾选读取以及读取和执行两个权限,这里实现不了,因为只有超级管理员才有更改权限的权限】,避免一些程序更改系统配置,比如正常的站点访问会自动被劫持到错误的ip上
还有个办法将host文件从系统文件夹中复制到有权限的文件夹,修改配置后粘贴替换原系统文件夹下的hosts文件
可以以管理员的身份启动editPlus,就能修改该文件
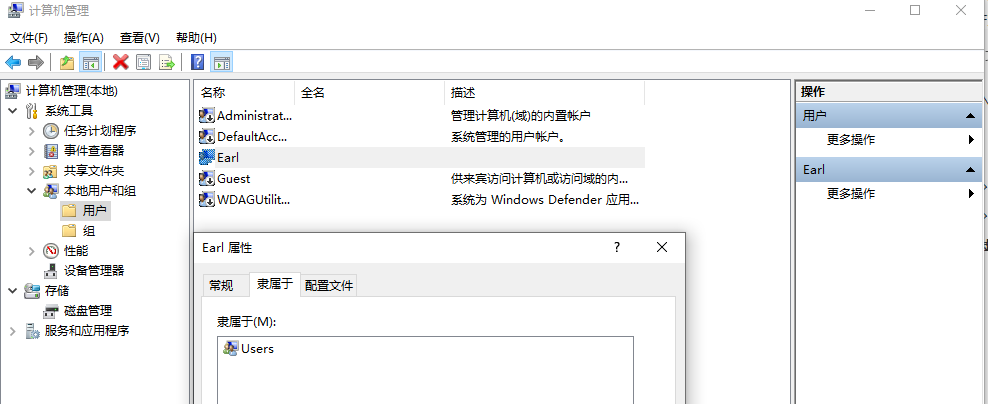
还可以将当前用户Earl添加到超级管理员组,这样当前用户就能获取超级管理员权限,但是这样不安全,除非把超级管理员的完全权限也禁用掉【以上办法都需要当前用户有超级管理员权限,如果把当前用户从超级管理员组中剔除,那么当前用户连更改权限都做不到,甚至想让超级管理员账户启用都做不到,此时只能
shift+重启,重启过程中一直按住shift进入高级选项,在高级选项中选择启动设置并以安全模式启动有点难找,但是确实找得到,选择超级管理员账户进入,将此前用户添加到超级管理员的分组中,让Earl用户拥有超级管理员权限】,现在的办法是给Earl超级管理员分组,取消超级管理员的写入功能,其他不要动,需要的时候再打开,避免出现超级管理员权限也丢失的情况而且注意hosts文件的编码格式必须为ANSI,不能为UTF-8,否则即使写对了也识别不了
【域名映射】
【还原用户权限】
【修改用户组】
【修改用户组效果】

测试域名解析生效
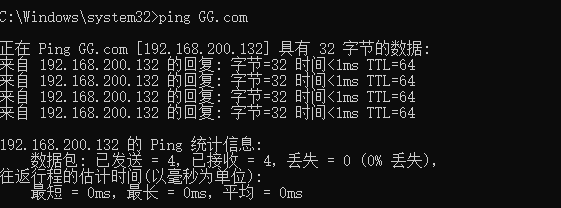
开启对应虚拟机,使用命令
ping GG.com观察是否ping通经过测试,域名不区分大小写
【浏览器使用域名访问虚拟机】
公网域名配置解析
域名的售卖商很多,最大的是万网,万网被阿里云收购了,小型域名商存在跑路的风险,我买的是腾讯云,用腾讯云做演示
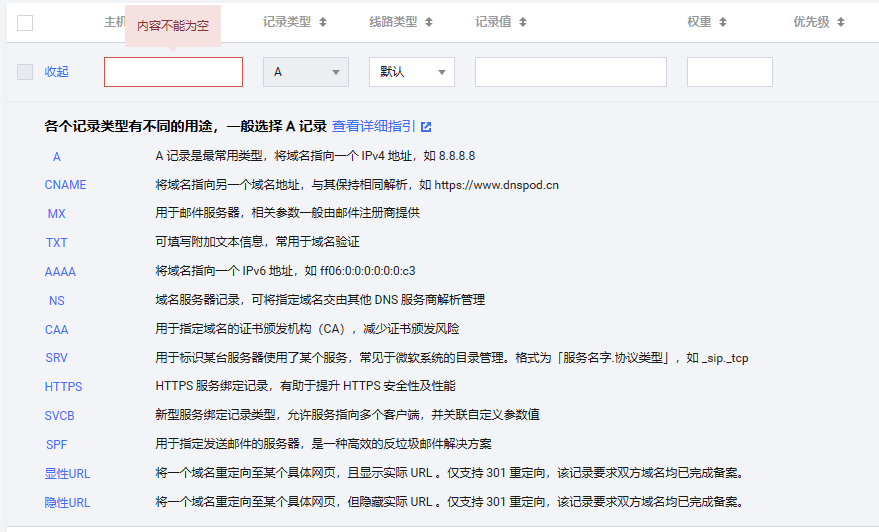
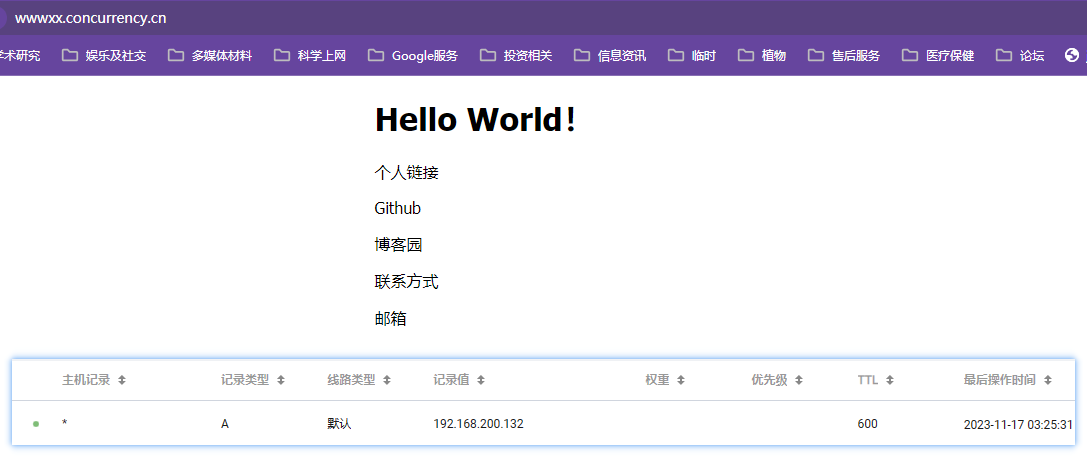
域名记录类型
除了列举的其他都不太常用,最常用的就是列举的几个记录,A是最最最普遍的
A是域名匹配一个独立的ip地址,直接将该域名转向到ip地址上,记录到服务器上,常用的就是A记录
CNAME是将该域名转向到另外一个已经解析好的域名上,有可能不知道域名的ip地址或者域名对应的ip地址会变,不需要管ip就能直接访问
AAAA是IPV6的地址,目前IPV6还没有普遍起来
NS是做DNS服务器的
MX是做邮件服务器的【申请企业邮局,会要求将SMPT、Pub3这种域名解析到相应的ip地址上】
填写说明
主机记录是域名的前缀
www如www.concurrency.cn,即二级域名,三级域名二级域名都可以如法添加,www前缀在浏览器不填前缀默认就是www,解析线路可以根据访问用户的通信运营商将用户对域名的访问指向到对应运营商如联通或电信访问速度较快的ip上,在DNS服务器上就能完成根据用户通讯运营商分配到访问速度较快的相应运营商ip上,还可以根据教育地址和搜索引擎分配不同的IP,把不同来源的流量分隔开,这就是智能的DNS服务器了;传统的DNS服务器只是k-v键值对的方式根据域名匹配ip地址,
记录值就是IP地址,就是虚拟机的那个地址
192.168.200.132TTL(Time to live),是指各地 DNS 服务器缓存解析记录的时长。
假设 TTL 设定为10分钟,当各地的 DNS 服务器接收到域名的解析请求时,会向权威服务器发出请求获取到解析记录,并在本地服务器保存10分钟,在10分钟内,解析请求将从本地缓存中读取,缓存失效后才会重新获取记录值。建议正常情况下设定10分钟即可,使用不同套餐版本的解析能设定的 TTL 最低值不同。
测试域名解析是否成功
cmd窗口ping www.concurrency.cn是否能ping通

浏览器访问 www.concurrency.cn能否访问到虚拟机的nginx欢迎页
此时也只能内网访问,公网无法访问
泛解析
对主机记录使用通配符
*,二级域名不论是什么都会解析到设置的ip地址上想要做二级域名系统,即多用户的域名系统【多个请求打到同一个ip真实主机,nginx再根据请求分配对应的站点】
Nginx虚拟主机配置
虚拟机中配置多个站点,端口号和主机名的并集不能完全相同,启动的时候会报错,不同虚拟主机的主机名和端口号其中一个可以不同或者都不同
配置虚拟主机站点目录
在linux系统下的根目录下创建www目录
在www目录下创建www目录作为主站点,创建video站点作为视频站点
在video目录下创建一个欢迎页index.html,编写文字
this is vod web site在www目录下创建一个欢迎页index.html,编写文字
this is www web site
更改nginx配置文件
nginx.confg创建文件用shell比较方便,编辑文件用xftp比较方便;不要怕改错了,
nginx.confg.default是该文件的一个默认备份xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#虚拟主机vhostserver {listen 80;#域名、主机名server_name localhost;location / {#设置该虚拟主机的主站点,绝对路径root /www/www;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}#虚拟主机vhostserver {listen 88;#域名、主机名server_name localhost;location / {#设置该虚拟主机的主站点,绝对路径root /www/video;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}改完以后使用命令
systemctl reload nginx重新加载nginx,使用命令systemctl status nginx查看nginx运行状态浏览器访问效果
实现了不需要区分域名只需要区分端口号就可以访问多个站点
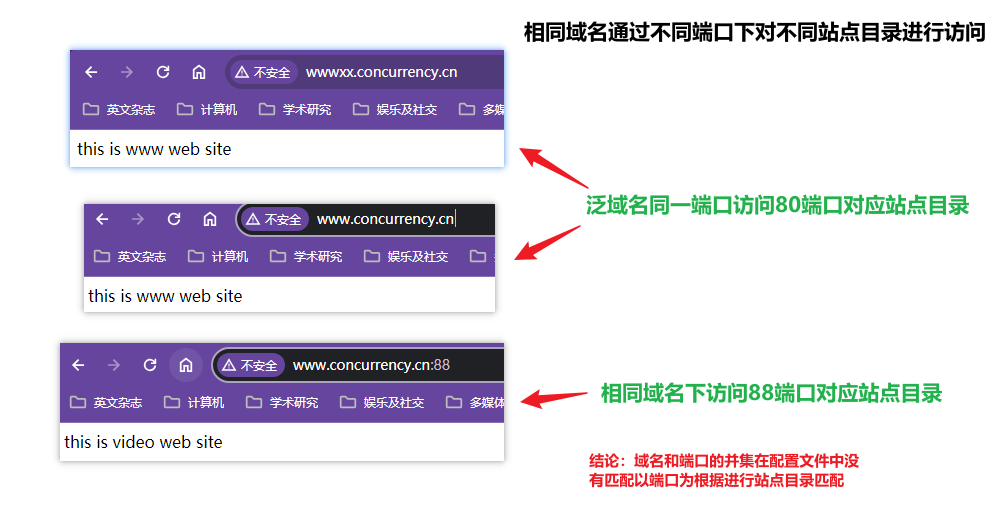
配置域名
配置相同端口不同二级域名,此时根据域名和端口的并集进行匹配
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#虚拟主机vhostserver {listen 80;#域名、主机名,让这个域名www.concurrency.cn进入到www这个站点目录server_name www.concurrency.cn;location / {#设置该虚拟主机的主站点,绝对路径root /www/www;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}#虚拟主机vhostserver {#同一个端口号下可以通过域名访问不同的站点目录,这种演示需要将端口改成相同的,否则会优先走端口listen 80;#域名、主机名,让域名vod.concurrency.cn进入到vedio这个站点目录server_name vod.concurrency.cn;location / {#设置该虚拟主机的主站点,绝对路径root /www/video;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}使用命令
systemctl reload nginx使配置生效,在浏览器输入不同的二级域名测试访问效果实现不区分端口只区分域名就能实现不同站点目录的访问
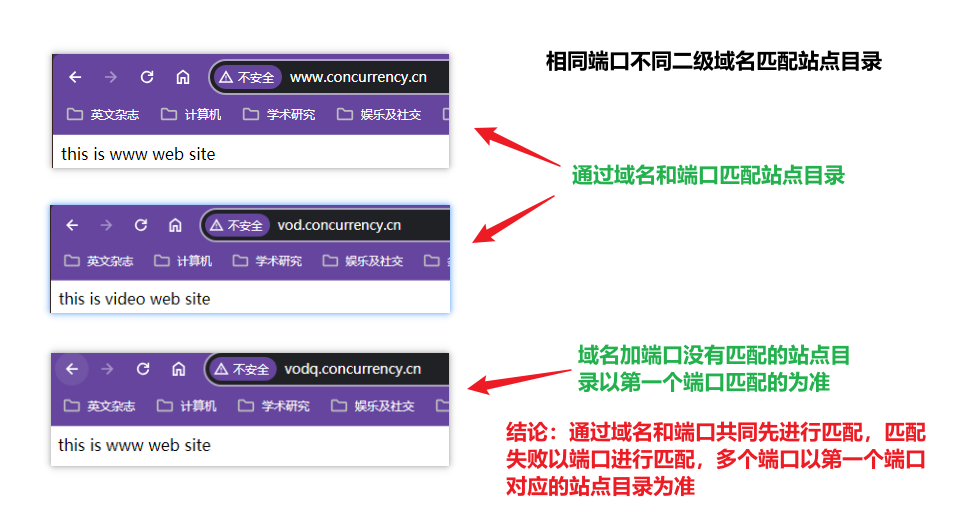
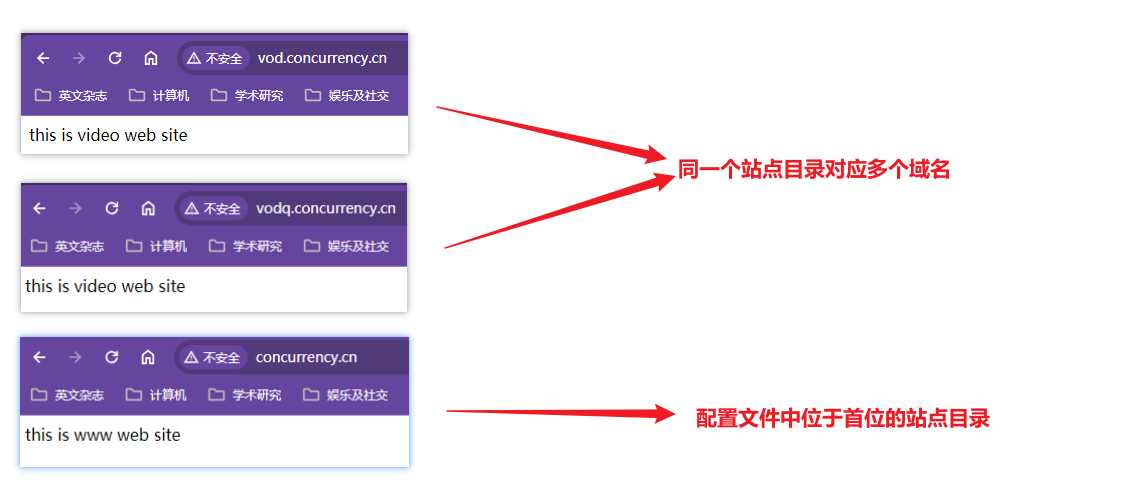
没有域名加端口的匹配站点目录的情况下默认访问第一个匹配端口的站点目录
证明:将vod站点配置在www前面,再次访问域名和ip没有匹配的请求地址
vodq.concurrency.cn,访问的站点目录就变成video目录了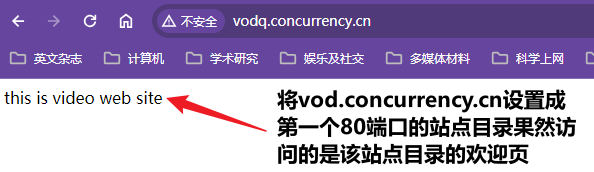
ServerName匹配规则
如果两个域名
vod.concurrency.cn和vodq.concurrency.cn都想解析到video目录下【不考虑将video站点目录作为首个80端口站点目录,用不能匹配的方式强制让vodq.concurrency.cn对应到video目录的情况下】,此时如果给两个域名都指定不同的虚拟主机server且都匹配到相同的站点目录,就显得很不优雅笨重server_name匹配是非常有用的技术,尤其是配置虚拟主机的时候,把所有的请求都接入到一个server中,server通过反向代理的方式把请求转到后端业务逻辑处理的服务器上,再根据用户请求做不同的处理响应不同的结果
可以在一个server的server_name中配置多个域名
第一个80端口站点目录是www,如果
vodq.concurrency.cn没有匹配上会优先跳转www目录
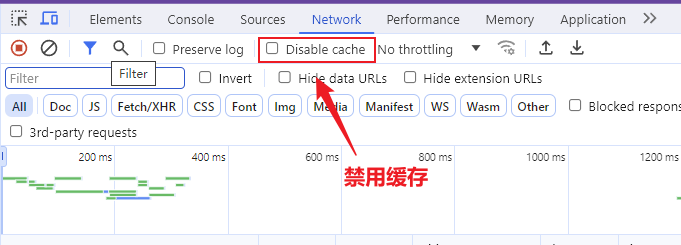
【浏览器禁用缓存设置】
即使点了也不一定好使,
也可以使用
ctrl+F5强制刷新缓存,也可以在请求链接后面加
vodq.concurrency.cn?xxx进行访问,浏览器缓存找不到对应请求路径,就会直接去请求服务器
【测试效果】
通配符匹配二级域名前缀
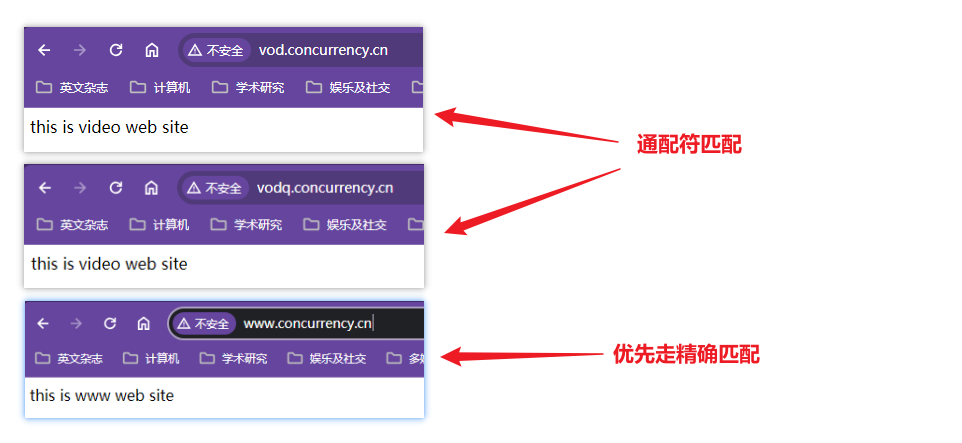
注意通配符匹配二级域名前缀
*.concurrency.cn不能识别一级域名concurrency.cn,直接通过concurrency.cn是访问不到虚拟主机的用
*匹配二级域名到video站点目录,将www站点目录放在通配符的后面,观察www.concurrency.com是否仍然访问www目录经过测试,域名匹配总是先走精确匹配,匹配不到再走通配符匹配

【测试效果】
通配符匹配域名后缀
用
*作为域名结束匹配可以匹配以不同字符.com或.cn结尾的域名到同一个站点,由于只购买了域名concurrency.cn,所以需要在hosts文件中添加www.concurrency.org和www.concurrency.net本地域名解析
测试效果
只要能被本地解析或者远程解析出主机ip的域名即使无法精确匹配,只要存在对应端口的站点目录,就会自动匹配到对应端口的第一个站点目录,hosts中配置的默认是以www作为二级域名,像vod.concurrency.org这种既无法被本地解析又无法被远程解析出主机IP的就会直接报错;如果找到主机IP,但是nginx配置文件中没有找到对应的端口,也会报错
同样的,优先进行精确匹配,再进行通配符匹配或者直接用端口进行匹配

正则匹配
配置
正则匹配前缀是纯数字的,即
concurrency.cn和纯数字.concurrency.cn跳转www站点目录,非纯数字.concurrency.cn、concurrency.net和concurrency.org匹配video站点目录
测试效果

域名解析技术架构
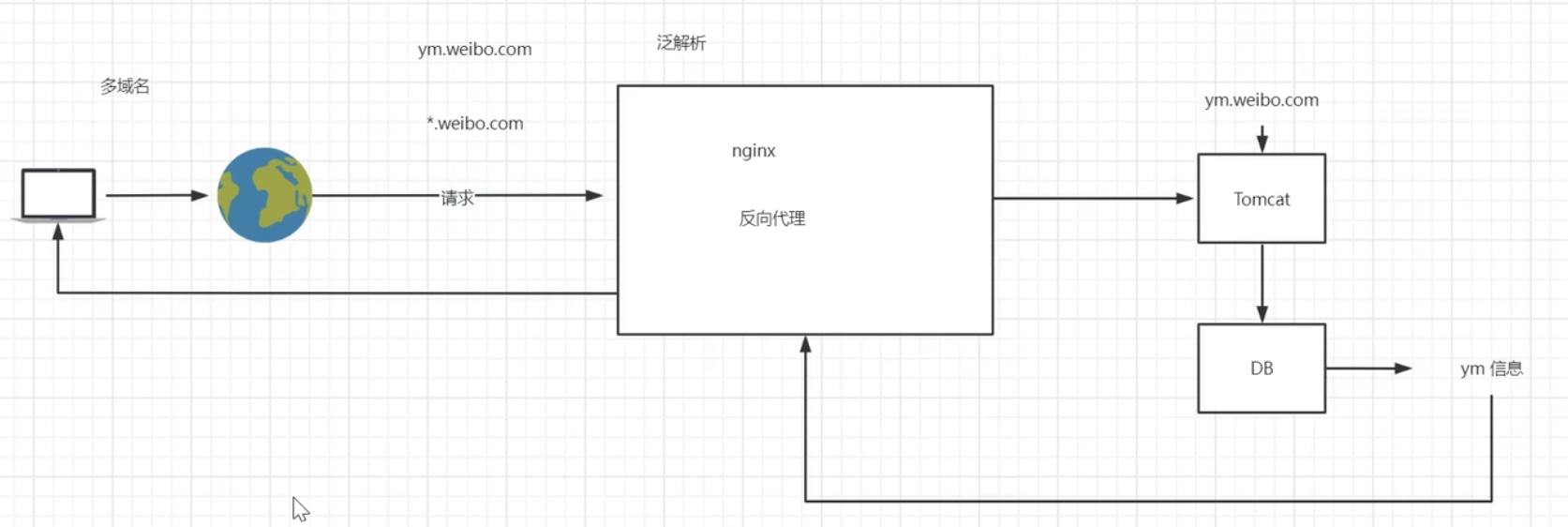
多用户二级域名
二级域名系统就是指有很多的二级域名来访问该系统
原理
所有的二级域名通过泛解析全部接入同一台服务器中,nginx通过反向代理将所有的请求转发到另一台业务服务器上【不是虚拟主机】,比如Tomcat和java实现的服务器,Tomcat能够获取到访问请求访问的二级域名,业务服务器处理完请求将结果返回给反向代理,反向代理将数据传递给nginx,nginx把数据响应给用户
感觉课上讲的像反向代理将请求转发给业务服务器,业务服务器解析二级域名前缀,拿着前缀去数据库获取该二级域名前缀的信息并传递给反向代理再传递给nginx,最后响应给客户端
短网址
原理
短网址就是用户发送一个请求如
dwz.cn/aidfjoasidfj21739给nginx服务器,nginx服务器将请求转发到短网址运维系统,该系统在数据库存储了短网址的uri部分即aidfjoasidfj21739和真实地址的对应关系【uri常用UUID保证唯一性,怎么处理真实地址获取到UUID的没有说】,用户使用短网址被打到对应的短网址运维系统,系统根据uri从数据库查询到真实地址,使用重定向将请求转发到真实的请求地址上
Httpdns
DNS服务器走的UDP协议【去全网广播,就是在腾讯云上配置的域名解析】,HttpDNS走的Http协议
具体原理还是要看计算机网络和操作系统,图也只是讲了个大概,这些只是nginx域名解析的应用场景,了解个大概
走HTTP协议需要有HTTPDNS服务器的IP地址,用HttpDNS就是想获取相应目标域名的IP地址,一般HTTPDNS服务器地址都存在客户端,HTTPDNS一般不适合网页即浏览器使用,一般是给手机的APP或者基于C/S架构的应用进行使用,【可以在这种软件中预埋几个ip地址,这几个IP地址就是nginx服务器,浏览器记不住这些HTTPDNS服务器的IP地址】,系统启动后,会向预埋的几个IP发起请求,请求传参某个域名获取其当前真实的ip地址,HTTPDNS将真实的IP地址返回
直接理解成发送请求前先使用预埋IP请求HTTPDNS服务器获取目标域名的IP,再次使用真实的IP发起用户的请求;浏览器无法实现因为浏览器无法持久化HTTPDNS服务器的IP,无法向HTTPDNS服务器自动发起请求,所以只适用于C/S架构的应用,HTTPDNS服务器就是
Nginx的错误页配置
错误页配置详解
错误页配置的目的是为了处理请求过程中发生了错误通过对错误进行捕获,用补偿的信息替代掉错误信息返回给客户
可以自定义发生错误时修改响应的状态码并且配置对应展示的资源或者跳转的网站,让浏览器认为没有报错,正常响应了资源或者友好提示,可以通过选项返回首页
以下展示了发生错误根据错误码展示对应的站点目录资源;
发生错误将响应错误码替换成302跳转到指定网站;
发生错误将响应错误码替换成200并响应指定站点目录资源
xxxxxxxxxx...http {...server {listen 80;server_name vod.concurrency.cn;location / {root /www/video;index index.html index.htm;}#发生404错误,发生错误就跳转到对应的网站上去,等号和302之间不能有空格,有空格会启动报错,跳转地址和分号间也不能有空格;HTTP状态码错误是可以处理的,系统级别的错误是用户是处理不了的,配置响应码302需要给重定向的地址给浏览器#error_page 404=302 http://www.atguigu.com;#发生404错误响应200状态码,响应/401.html站点资源;此外错误页还可以设置响应图片或者其他东西,但是一般都是使用网页给用户响应error_page 404=200 /401.html;#error_page的相关设置,如果是500系列错误就会跳转到location站点/50x.html下,/50x.html是一个location,不是一个地址;如果是APP或者前后端分离的项目也可以返回一个友好提示的json数据error_page 500 502 503 504 /50x.html;#location的根目录是html目录,没有指定uri对应的资源名就会去访问uri对应的同名资源location = /50x.html {root html;}error_page 401 /401.html;location=/401.html{root html;}}}【404错误的响应效果】
【响应站点目录资源的效果】
匿名location
匿名站点目录的匿名针对的是客户端,客户端访问该站点是访问不到的,主要用于希望location只在内网中被使用的情况,在内网调用的情况下就可以把匿名站点的内容展示给用户
匿名location的配置
此前配置的站点目录用户通过对应的uri都是可以访问到的,包括错误页配置
匿名location的写法是location后面不使用等号使用@符号
xxxxxxxxxxlocation @666 {root html;}【访问匿名站点目录的效果】
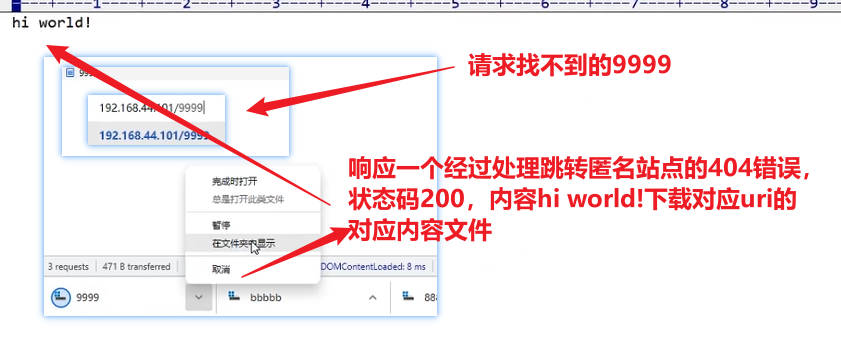
html站点目录下有index.html资源,但是匿名站点目录无法访问,返回错误码404,404此前设置错误页响应200并响应资源401.html

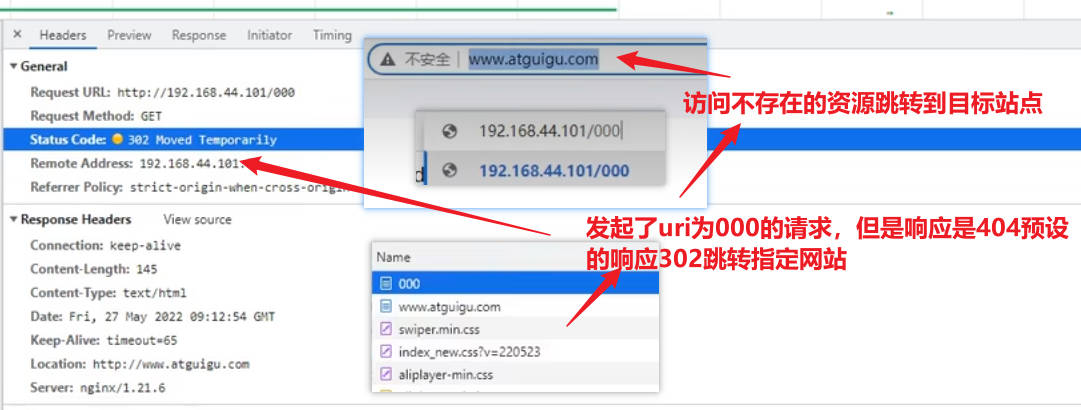
希望用户无法访问但是内部可以跳转的匿名站点目录
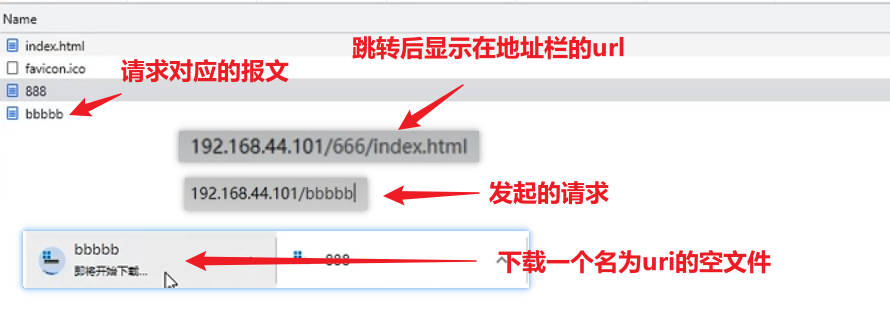
这种配置下找不到资源会报错404,但是会被跳转到配置的@666站点目录下并响应return中响应的内容,如果只有200状态码,没有指定响应的资源,会响应一个请求uri作为文件名的空文件
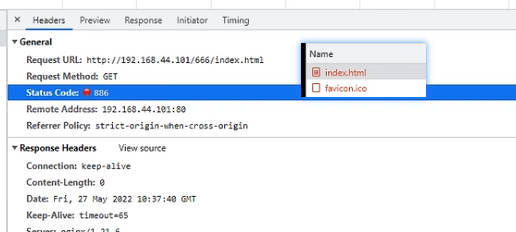
如果状态码不是200比如886,浏览器只会在响应头中看到状态码886,不会再显示下载文件;因为状态码200告诉浏览器要读取响应内容,对200状态码下载的行为是浏览器做出的判断,在响应头中没有Content-Type类型,不知道如何展示响应内容,就只能选择以文件下载的方式处理响应内容
xxxxxxxxxx#发生404错误跳转@666匿名站点,这个等号和@666之间有空格也能成功启动nginxerror_page 404= @666;#@666是站点的名字,html是站点目录;return命令可以直接返回后面跟的资源,无需进行资源和uri的匹配;只有状态码200会开始下载一个空文件location @666 {return 200;#return 886;}【上述找不到资源404错误跳转匿名站点@666并响应站点目录return后面的资源内容】
名字经过确认就是对应uri,且大小为0K
【状态码886的响应效果】
只有return不设置响应内容类型Content-Type,响应头中就没有Content-Type参数,浏览器不知道如何去展示响应数据
location中return响应状态码和文件内容
【匿名站点响应200状态码并添加资源】
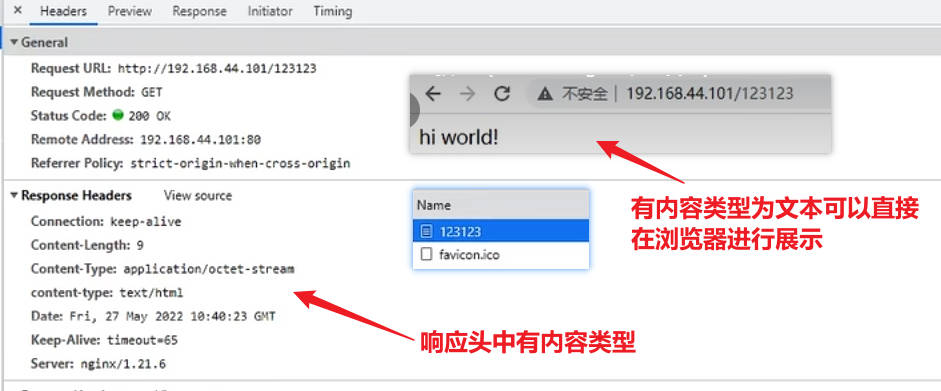
xxxxxxxxxx#发生404错误跳转@666匿名站点,这个等号和@666之间有空格也能成功启动nginxerror_page 404= @666;#@666是站点的名字,html是站点目录;return命令可以直接返回后面跟的资源,无需进行资源和uri的匹配;只有状态码200会开始下载一个空文件location @666 {return 200 "hi world!";}【响应效果】
在使用return的同时添加Content-Type参数
设置成响应类型为文本类型,浏览器就能对响应内容进行展示
xxxxxxxxxxerror_page 404= @666;location @666 {#向响应头信息中添加头信息content-typeadd_header content-type "text/html";return 200 "hi world!";}【响应效果】
反向代理
反向代理是nginx应用中极为重要的功能,也是系统架构选用nginx使用的主要功能,基于反向代理可以衍生出非常多的应用场景和需求的解决方案
网关、代理和反向代理
反向代理
用户访问系统通过互联网将请求打到机房的网关上,网关会把所有的请求都打到nginx服务器上,nginx作为反向代理服务器时会将所有的请求全部转发到后端的应用服务器,这些应用服务器可以是java和tomcat做的项目集群,tomcat是不会被用户直接访问到的,应用服务器响应之后再将结果响应给nginx,在nginx和应用服务器之间形成内网,就是nginx在中间做了中间商,这种系统结构就是反向代理,相当于nginx代表用户去访问应用服务器,发现访问成功,数据也都拿回来了
机房内的网关和应用服务器也不互通,网关想要直接连接应用服务器连不上

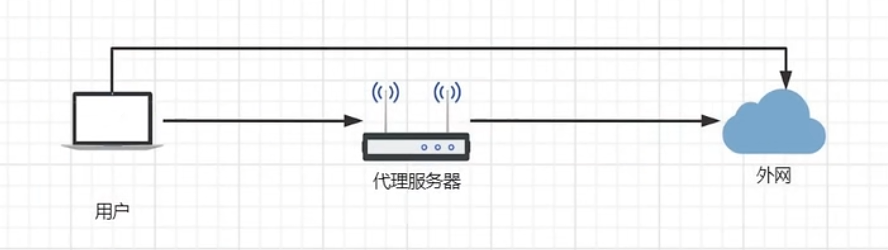
正向代理
正向代理系统结构
比如用户无法直接连通外网,此时需要一个代理服务器,用户能够连接代理服务器,代理服务器能够连接外网,用户就能通过代理服务器连接到外网【有点像vpn】
正向代理和反向代理的区别就是正向代理是用户主动配置代理服务器【用户和代理服务器是一家子】,需要这个代理服务器去访问某些网络;反向代理是nginx代理服务器与用户想要访问的网络是一家子【即该代理服务器不是用户主动配置的】,用户甚至机房网关都不能直接访问应用服务器,由服务提供商提供给用户一个访问入口来对访问不到的应用服务器进行访问;实际上两种代理服务器都起到一样的作用,即在用户和网络资源之间起到中继和网络传递的作用,本质上都是用户--代理服务器--网络资源的结构,就看代理服务器是谁提供的
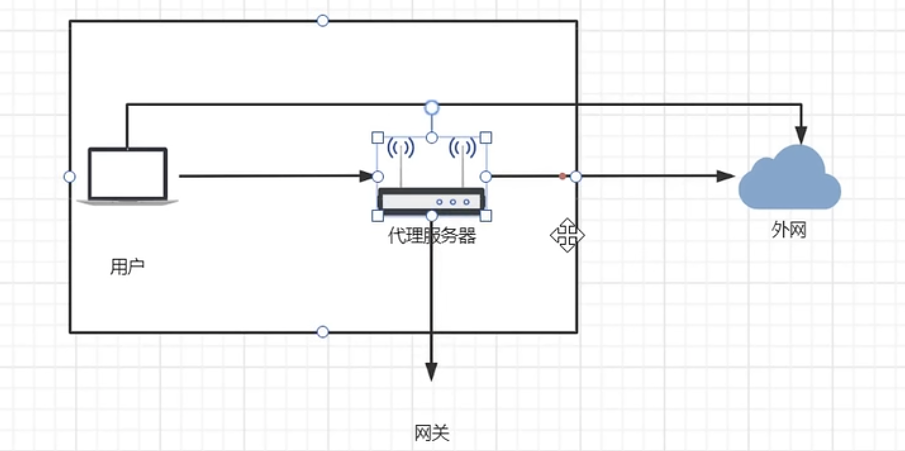
网关
手机连上家里的路由器,把所有的数据都发送给路由器,由路由器转发给下一跳的路由中继或网关服务,一跳接一跳地跳到目标服务器的位置,目标服务器收到请求处理后再一跳一跳的返回回来;家里的路由器其实就是网关,网关其实就是一种代理服务器,在正向代理结构中的爱丽服务器就是网关,网关就是访问网络的入口,就像学校的大门,需要从大门进出学校
网关的特点:在用户和目标服务器之间中转所有的数据,这种特点注定如果网关的带宽不足【比如路由器的带宽只有10M,但是下载的东西是100M,意为着最大地下载速度只有10M,千兆网络如果路由器的下载速度只有10M,下载速度也会卡在10M,请求越多越卡,多个请求访问外网会竞争路由器的带宽资源,越竞争路由器的分配效率越低,认为带来很多额外的操作,避免这种情况只能提升代理服务器即网关的带宽】,在反向代理结构中,nginx服务器的网络带宽就是整个应用集群的带宽,nginx服务器的带宽只有10M,后续网络即使千兆,数据传输速度也只有10M;这种特点决定了在较高品IO操作的情况下nginx做反向代理服务器就不合适了,这种数据一进一出必须走一个nginx代理服务器的模型称为
隧道式代理模型,这种模型有天然的网关性能瓶颈;有其他办法可以避免这种隧道式代理模型带来的网关性能瓶颈,即用户请求打到nginx反向代理服务器,nginx将请求转发到应用服务器,应用服务器直接将数据返回给用户,而不是将数据返回给网关由网关将数据返回给用户【只有请求进应用服务器走代理服务器,响应数据的时候不再走代理服务器】,这样的模型叫DR模型,是LVS提供的一种功能,LVS是一种性能比nginx还要高的负载均衡器,但是功能比nginx简单的多,LVS是专业的负载均衡器,在反向代理的时候既可以做隧道式反向代理,也可以做DR模型的反向代理【请求进入系统通过代理服务器,响应返回的时候不过代理服务器】,DR模型的应用举例:必须想获取应用服务器一个500MB大小的文件,可能发送的是一个get请求,get请求只有1KB大小,1KB的请求消耗的网络带宽不大,此时返回数据500MB数据如果走nginx,在高并发情况下nginx的网络就首先扛不住了,此时由Tomcat把数据包直接传递给用户【也不是直接传递,而是先将数据包传递到机房的网关上,即使用DR模型需要应用服务器能和机房网关通讯,此时应用服务器也是接入外网的,应用服务器此时不处于纯粹的内网环境,但是这种情况一般应用服务器被设置成只能向外网传数据,不能接收任何请求】就会极大地减小nginx的压力,DR模型是靠虚拟伪装IP完成的,逻辑在LVS中会详细讲解
Lvs是一款很简单的软件,直接内嵌在linux内核中,甚至不需要额外装软件就可以直接使用LVS,
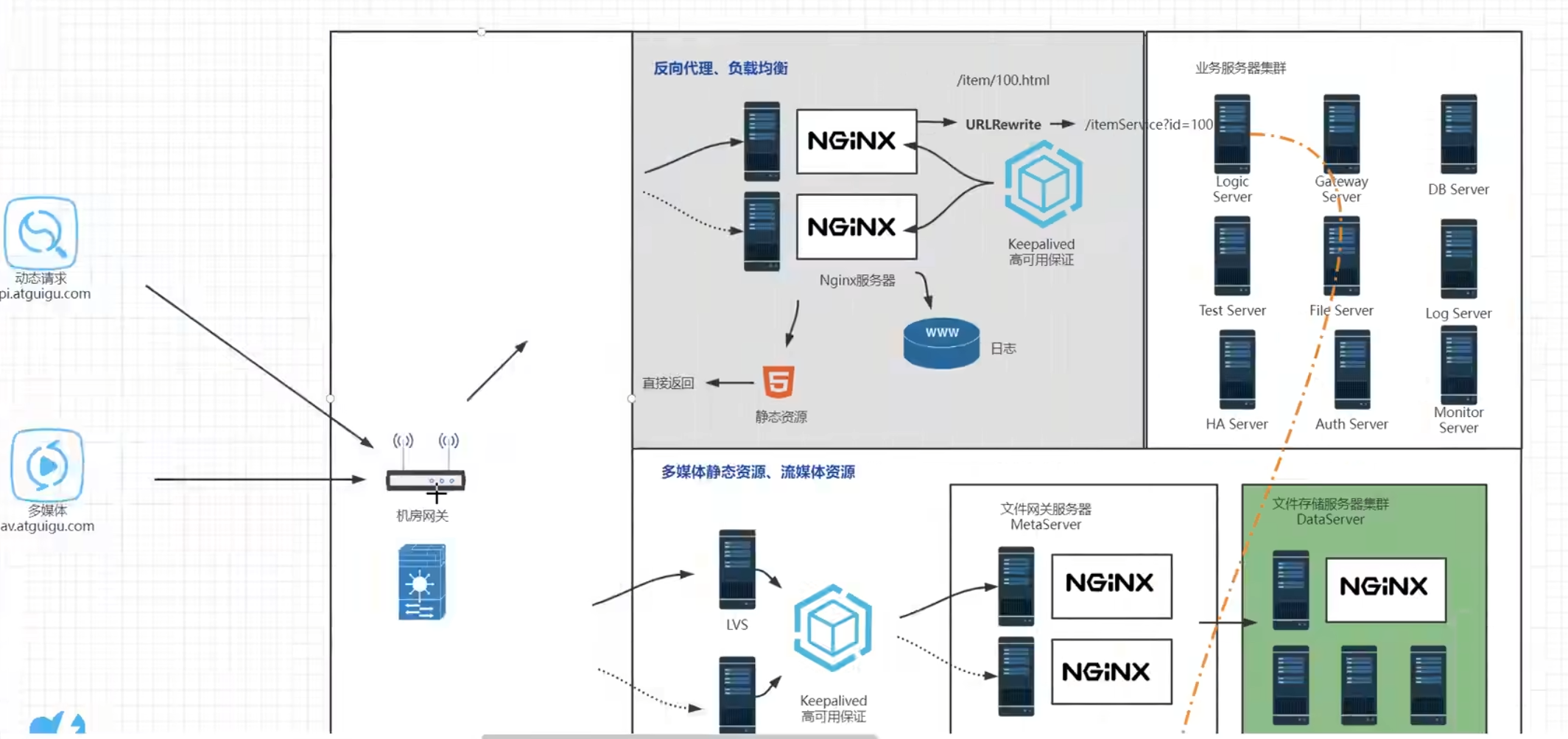
反向代理的应用场景
超大型的互联网项目还是传统公司里面的ERP、CRM、CMS、OA这种项目基本上都有nginx的反向代理,主要还是性能高,成本低,体验好
传统公司系统架构
最简单的应用架构,这种架构适用于传统小型项目,像一些提供给内网用户使用的系统并发量不大直接用nginx代理请求即可
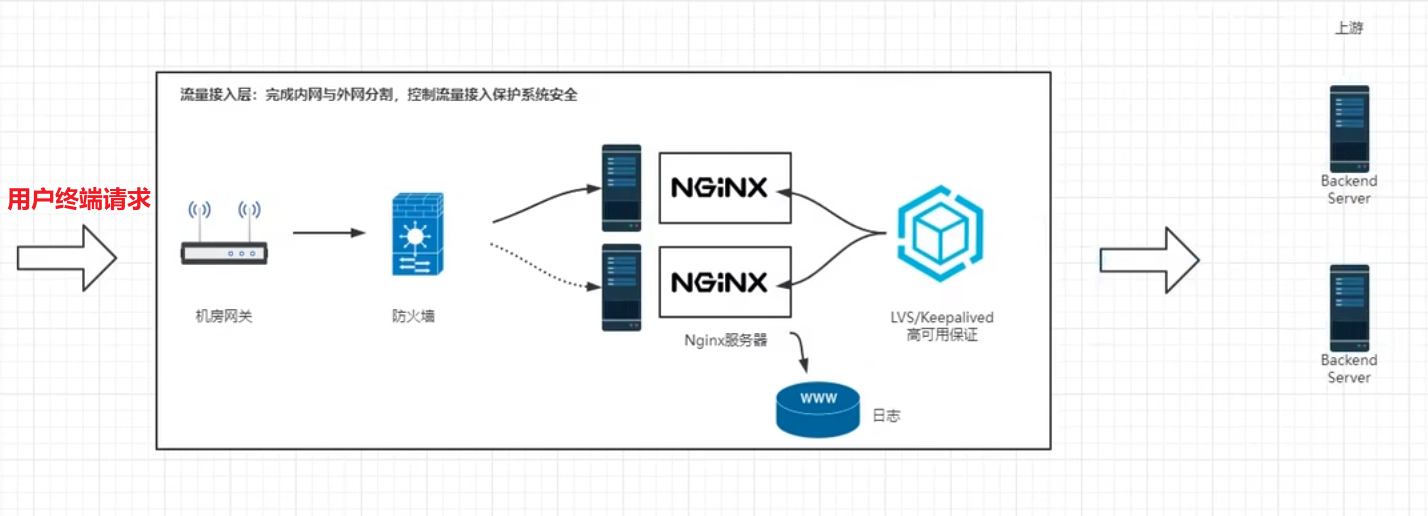
用户接入层
用户请求经过网关,经过域名解析,通过互联网访问到公司系统的流量接入层
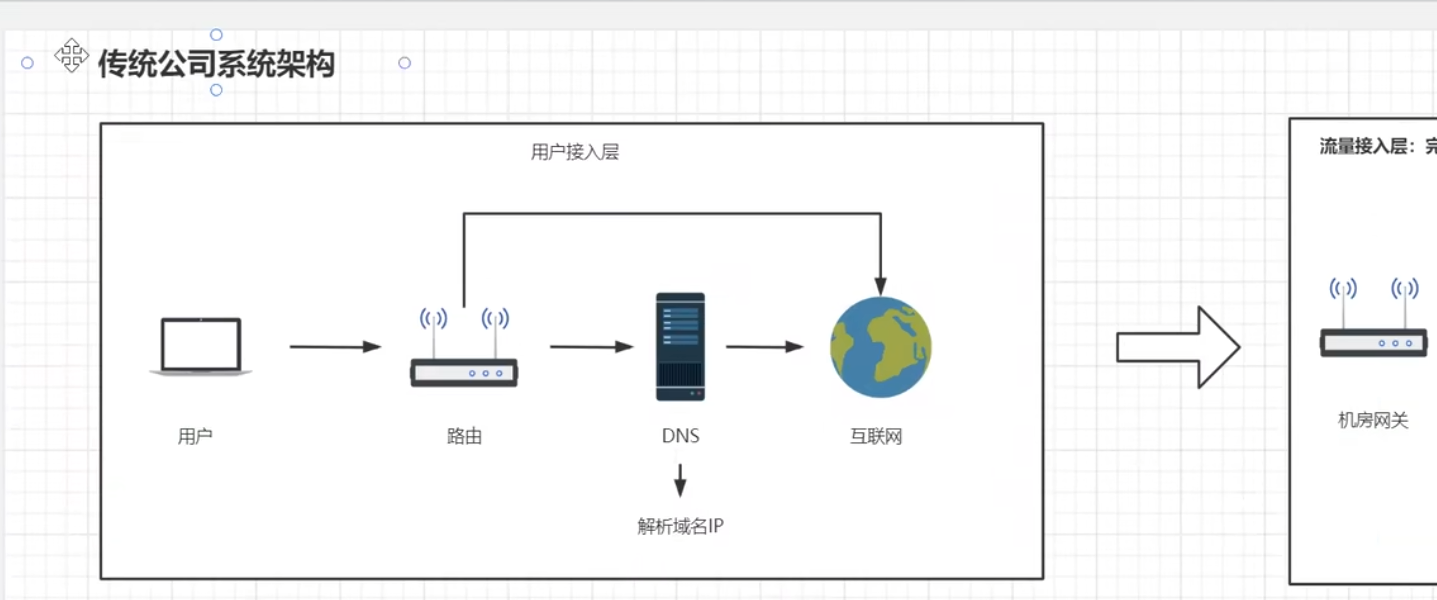
机房网关加代理服务器
用户请求打到机房网关,机房网关中转请求并通过防火墙,转发带nginx反向代理服务器,反向代理服务器将用户请求转发到对应的业务服务器
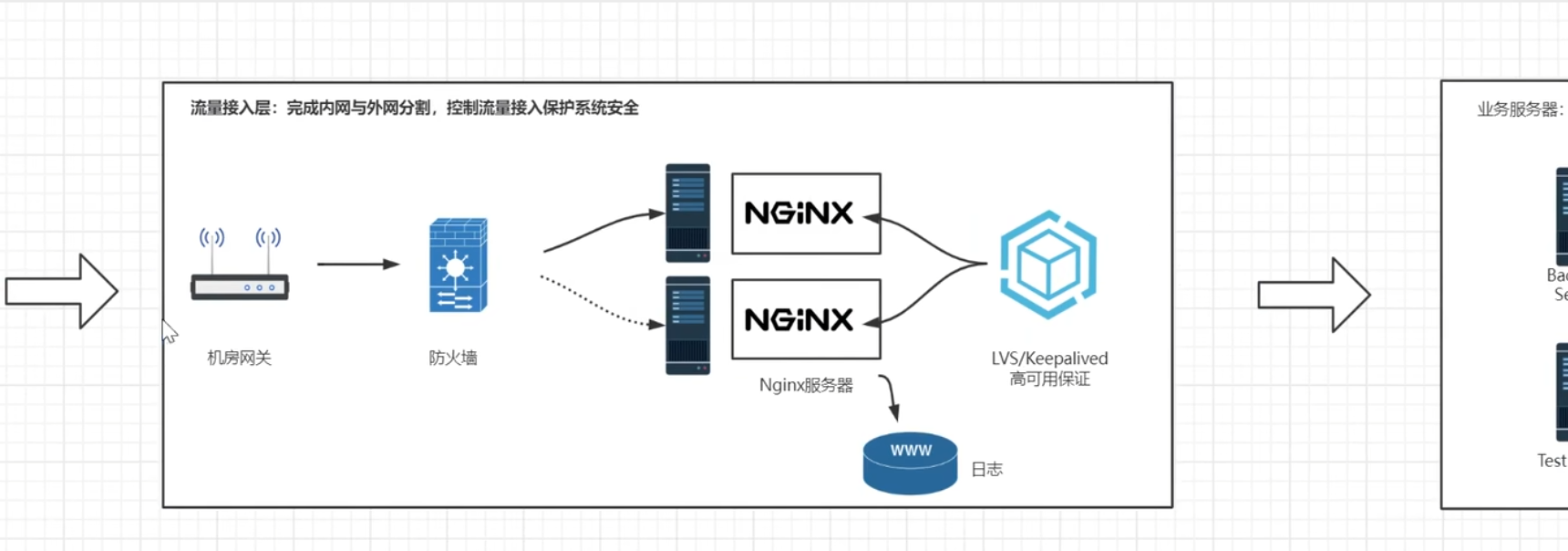
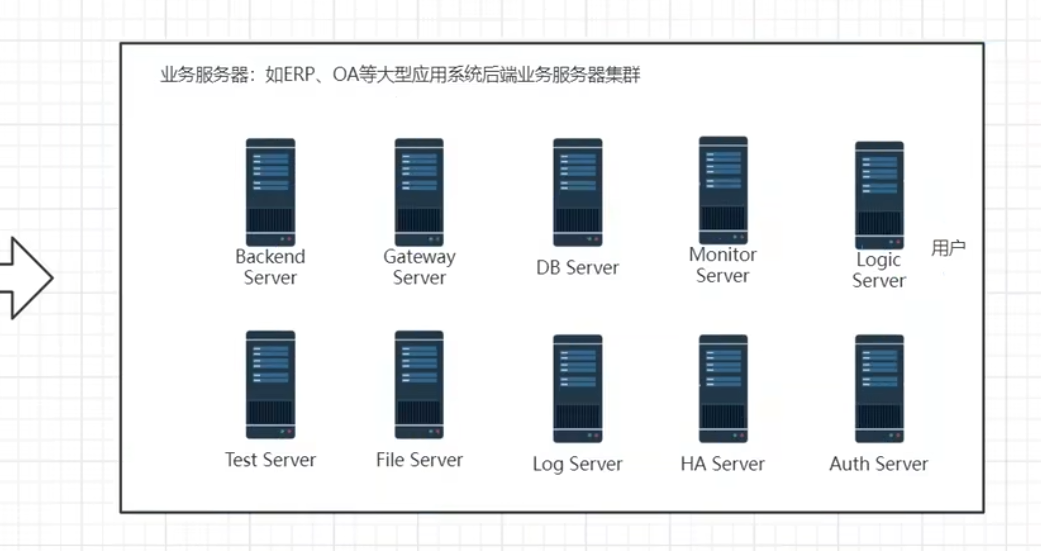
业务服务器
举例:英语培训在线教育APP,以nginx代理后边的三台tomcat,系统性能非常好,3台tomcat服务器能抗住300的并发量,并发量就是QPS,QPS300对传统的互联网项目来说已经非常可以了,这个产品的价值也已经非常可观,不是同时在线人数,是每秒钟有300的点击量,实际上大部分时间都是浏览,所以点击量是低于在线人数的
backend Server是后端服务器,GATEWAY是后端的网关路由服务器,数据库服务器、测试用的服务器、文件存储服务器、日志服务器,业务逻辑服务器、保证高可用的HA服务器、权限管理的Auth Server服务器
GATEWAY服务器是将所有的业务服务器统一的管理起来,在中间起到查找和一定的鉴权作用,并不是所有的请求都可以直接访问业务服务,而是需要在GATEWAY做一次权限认证
Nginx是服务器级别的网关, 当后端的网关需要做成集群时需要Nginx做负载均衡, 后端的网关是项目级网关
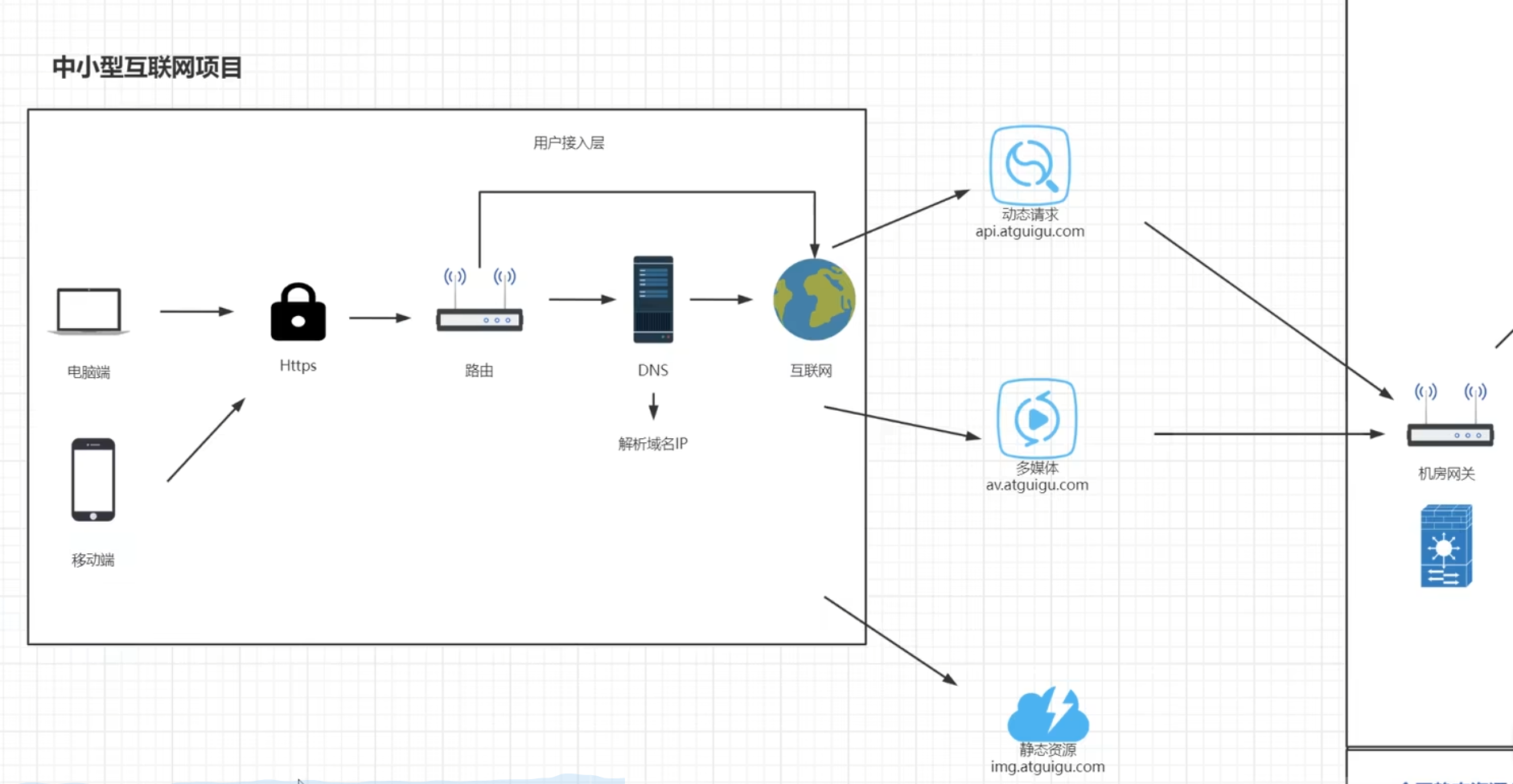
中小型互联网项目
用户接入层
这一块后面再说
系统
nginx作为反向代理服务器需要起到更多的功能,如伪装当前访问资源的真实地址【发送请求的URI为
/item/100,能在nginx中改写成真实访问的URI/itemService?id=100,这样能显得更高级;电商类似京东会将/itemService?id=100这样的访问URI改写成/item/100.html的形式,用户看起来会觉得这是一个独立的页面,实际上数十亿的商品根本不可能存在这么多静态页面,这种方式会让商品在计算网页排名的算法PageRank中占到的权重更高】nginx服务器对业务逻辑的转发,转发的数据包一般就是json数据,可能就几KB大小【比如修改密码】,这种情况下nginx很能抗,一台nginx服务器就能代理后边的数十台业务逻辑服务器
对于多媒体静态资源,流媒体资源的服务器,nginx代理服务器因为带宽就会成为瓶颈,文件存储服务器存储的都是文件且数据比较大,电影、软件等;如果此时用nginx做反向代理就需要多配置一些nginx代理服务器,分成好几组去代理后边的文件服务器
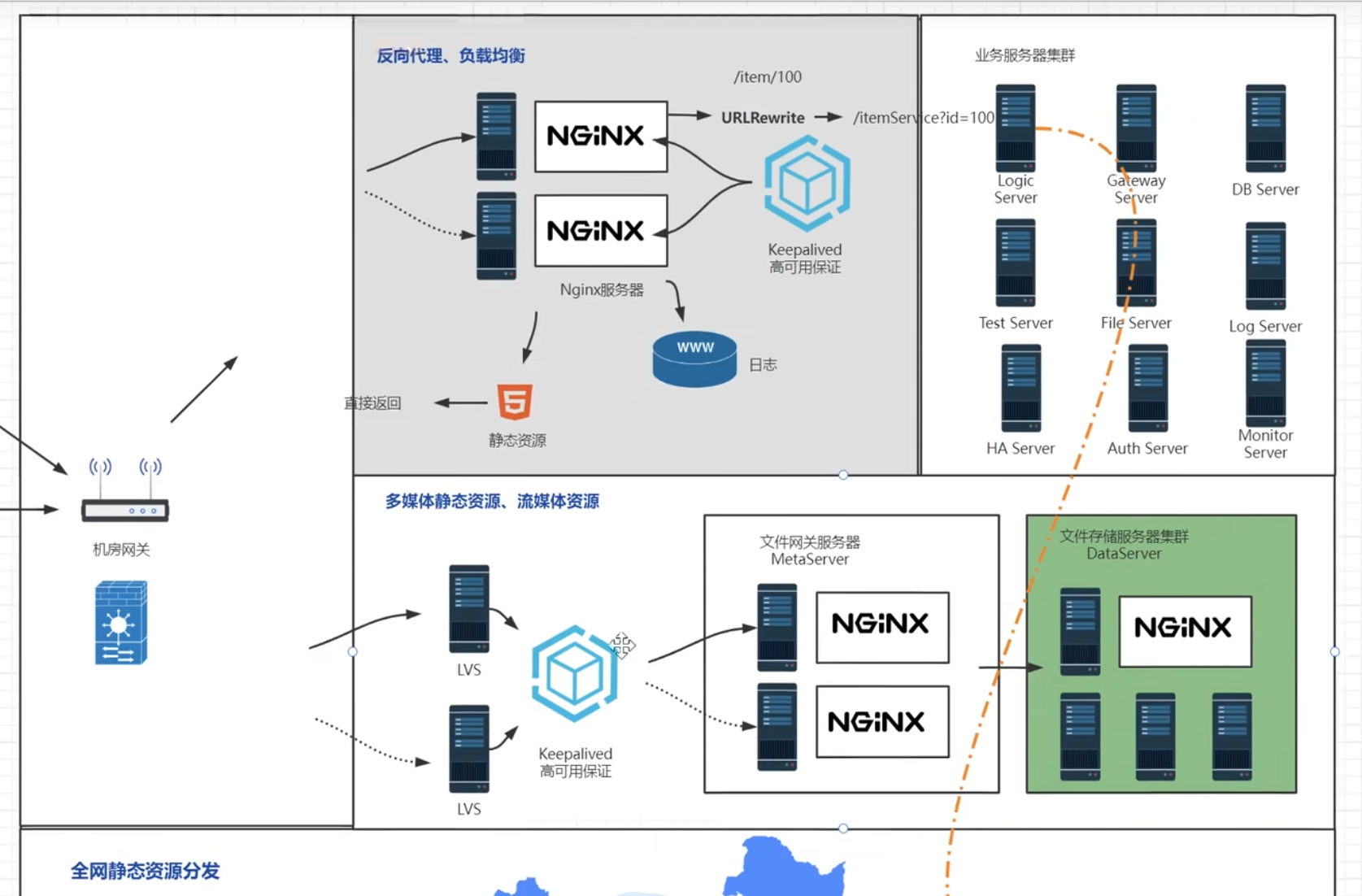
全网静态资源分发
不清楚这个是干什么的,没讲,先mark
Nginx反向代理配置
Nginx代理一个网址
proxy_pass属性
proxy_pass在nginx.conf文件找那个的server.location中配置,在其他位置配置启动会报错,proxy_pass属性和root属性是二选一的关系,proxy_pass一旦配置,root属性【配置寻找静态文件的目录】就不能使用了,包括
静态资源目录和对应的路径静态资源映射。proxy_pass的属性值有两种,一种是要让nginx代理的地址,可以是一台具体的主机,也可以是一个网址;另一种是配置一组服务器代理一个网址时的nginx配置文件配置
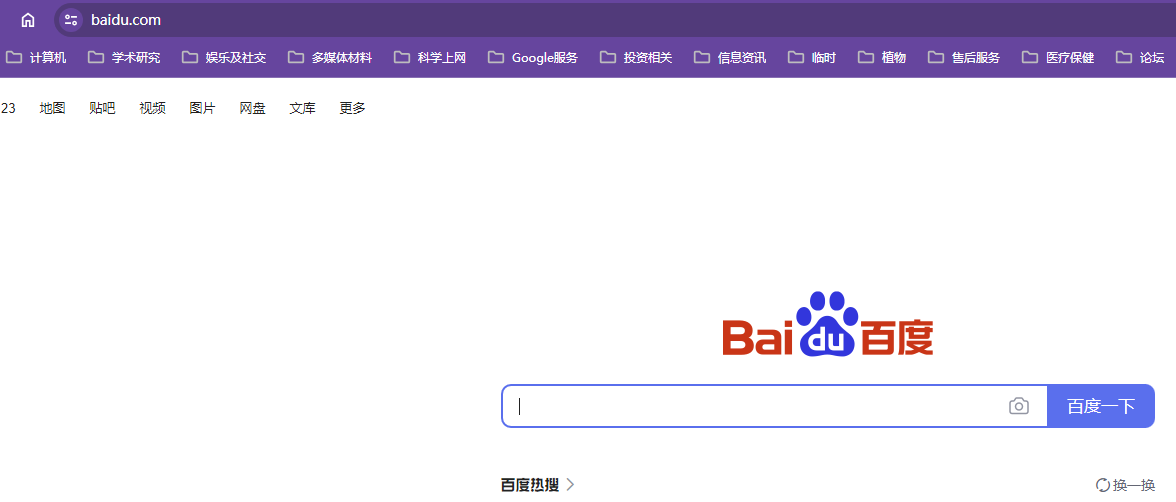
能实现访问当前站点的根目录能跳转到网址https://www.baidu.com/上,但是跳转到百度上可能因为重定向的原因地址栏显示百度的网址了,使用尚硅谷的网址就不会出现这种问题
过程是用户访问nginx代理服务器,代理服务器根据proxy_pass将请求转发过去,拿到数据后返回给nginx,nginx再返回给用户
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;server {listen 80;server_name localhost;location / {#这里使用https协议的目前的nginx配置加载配置文件会报错#与前面类似,访问百度或者京东proxy_pass http://www.atguigu.com;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}使用命令
systemctl reload nginx将nginx配置文件重新加载使用命令
systemctl daemon-reload用重启nginx服务访问效果
【跳转百度】
【跳转尚硅谷】
完全显示的是nginx代理服务器的ip
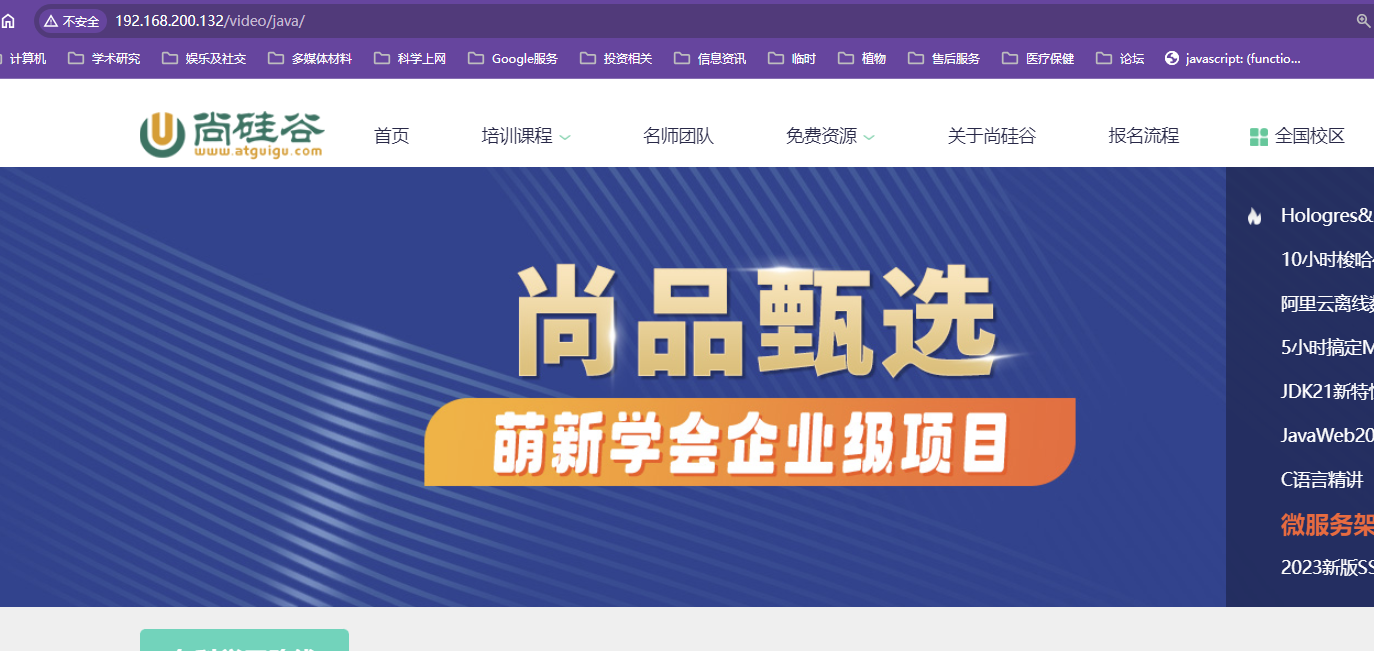
【使用自己的域名跳转尚硅谷】
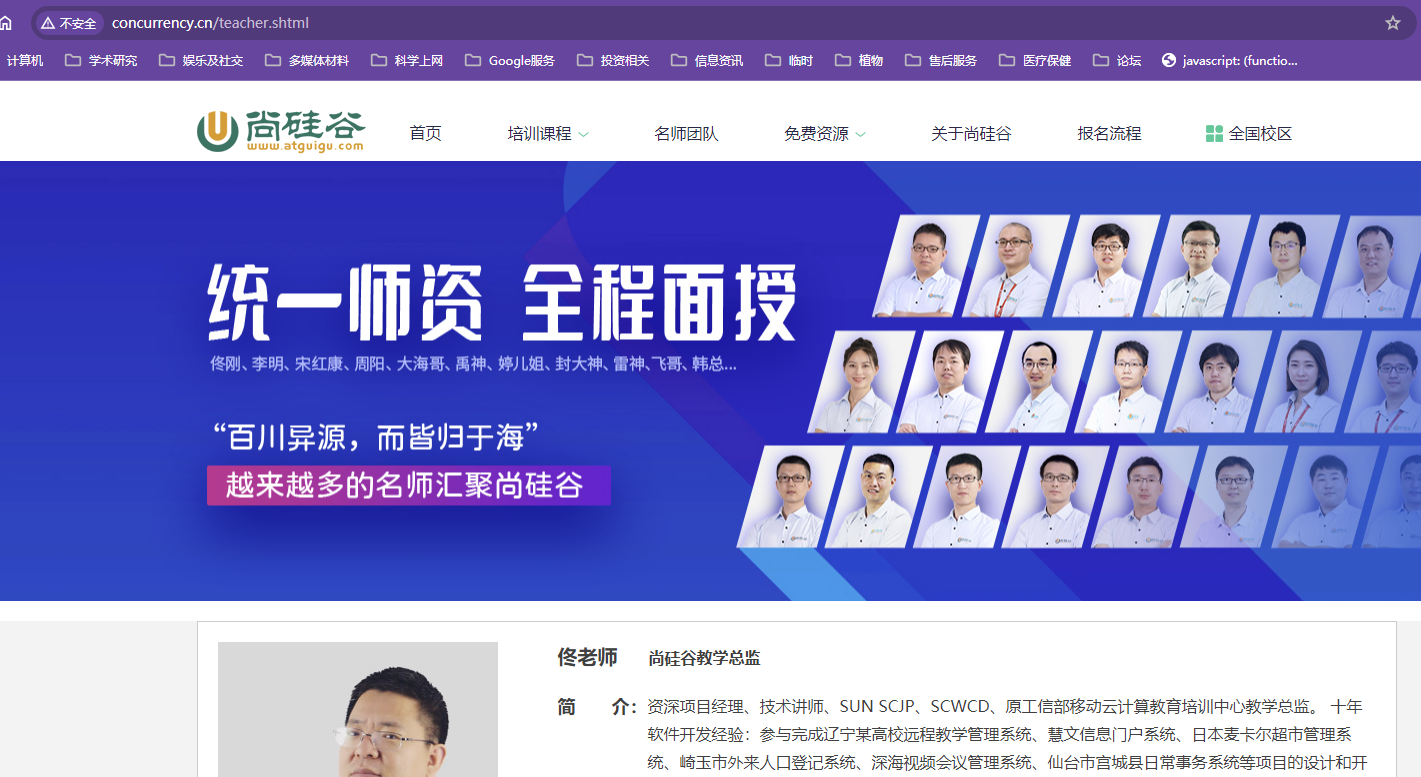
如果proxy_pass的属性值不带www,请求nginx代理服务器会发生重定向
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;server {listen 80;server_name localhost;location / {proxy_pass http://atguigu.com;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}代理效果
配置文件中的proxy_pass不带www,此时再用nginx地址访问
192.168.200.132地址栏会直接显示尚硅谷的地址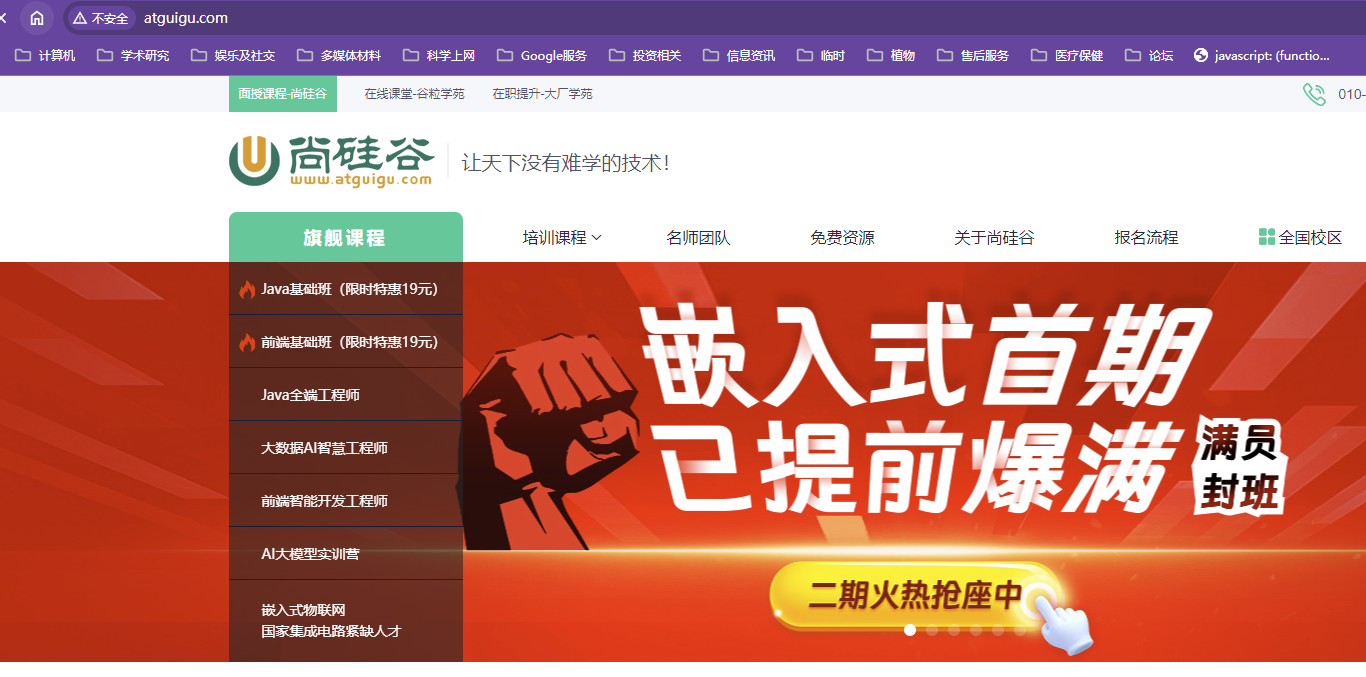
【执行效果】
使用IE浏览器才能看见,Chrome是看不到第一个请求的,从信息中能看到nginx服务器的版本是1.20.2,原请求返回状态码302【http协议中的重定向状态码,让浏览器重新加载响应头中的location】,要求重新跳转,响应头中的跳转地址是
http://www.atguigu.com/跳转https协议的时候会发生相同情况,即302状态,location中是https的重定向地址;而且nginx.conf的proxy_pass不支持反向代理https服务器,https服务器需要与域名对应上【后面会讲证书和域名之间的关系】,据说https可以代理,只是https报错是因为没装openssl以及编译时没开启ssl模块
重定向的原因没讲,猜测是服务提供商针对其他域名做了重定向处理
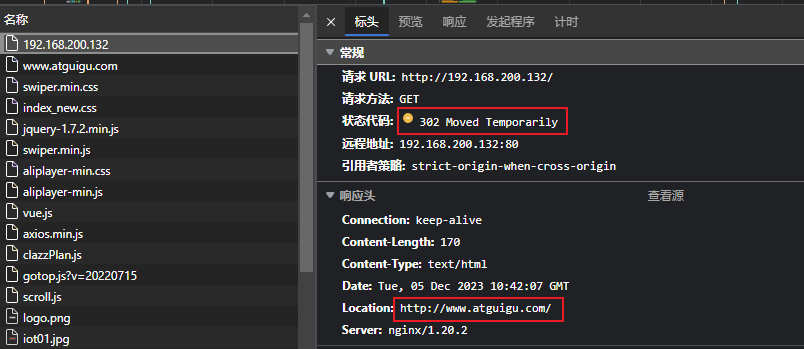
Nginx代理一台主机
nginx代理一台主机
创建第二台虚拟机上
192.168.200.133的nginx,配置文件修改如下nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;server {listen 80;server_name localhost;location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}第二台nginx服务器访问效果
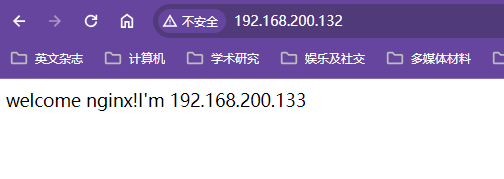
更改/usr/local/nginx/html目录中欢迎页添加第二台虚拟机的IP信息,用浏览器访问查看效果

第一台nginx服务器的proxy_pass指向第二台nginx服务器
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;server {listen 80;server_name localhost;location / {proxy_pass http://192.168.200.133;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}通过第一台nginx代理服务器访问第二台nginx代理服务器效果
这只是一台nginx代理一台服务器,还可以配置nginx代理到多台服务器上
Nginx代理多台服务器
创建第三台nginx虚拟机
nginx服务器访问效果
基于反向代理的负载均衡
一台nginx把请求代理到应用服务器后还会有非常多的服务器集群
负载均衡器
女朋友一个月总有几天不能用,不能用怎么办,找一个备胎,不能用的时候备胎续上,服务不行了就下线
nginx对服务集群做反向代理可以添加负载均衡功能,负载均衡策略(算法)包括轮询、IP哈希、定向流量分发、随机,以满足服务下线维护,短时间故障期间的服务正常提供
存在请求已经发送给服务器,但是才发现服务宕机,此时产生一种retry【重试】机制来解决这个问题,再去找一台正常的机器来处理该请求
配置负载均衡
负载均衡的配置需要和proxy_pass配合使用,配置了三台nginx服务器,想要实现在第一台nginx服务器上负载均衡访问第二台和第三台nginx服务器,访问第一台nginx服务器一会儿显示133服务器,一会儿显示144服务器
当反向代理服务器需要代理多台服务器时,需要将proxy_pass属性的属性值弄成
http://自定义名,这个自定义名是随便起的,可以用来代替服务器IP,但是要和upstream 自定义名中添加多台代理机器的IP和端口号【为了统一,将端口号也配置上,80端口不写其实也是可以的,规范一点】,upstream 自定义名和server是同一级的配置,配置详情见nginx.confxxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.200.133:80;server 192.168.200.134:80;}server {listen 80;server_name localhost;location / {proxy_pass http://proxyServers;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}多台机器负载均衡效果
但是没有讲怎么配置nginx对多台服务器的代理,这里添加了负载均衡,去掉负载均衡就是配置对多台服务器的代理效果
负载均衡策略也是轮询策略,轮询应该是nginx默认的负载均衡策略
Nginx负载均衡策略
准备了一台nginx代理服务器和三台用来测试负载均衡策略的nginx服务器。ip分别为
192.168.200.132,192.168.200.133,192.168.200.134,192.168.200.135,用132作为代理服务器剩余三台作为被代理服务器测试负载均衡策略,以上服务器都在欢迎页添加了服务器IP信息动态分配nginx服务器的上下线,仅靠nginx的基础命令如down和backup是不行的,一般来说,所有在线机器都挂掉,很有可能是程序运行导致服务器出现共性问题宕机,备用服务器上线也不一定好使,所以实际down和backup都不常用,down需要修改配置文件并在服务器reload一下,这样一般是来不及的,有这个时间可以考虑直接再向集群中再加入一台服务器,所以down和backup实际生产中使用比较少,负载均衡的权重是比较有用的
权重
权重负载均衡策略
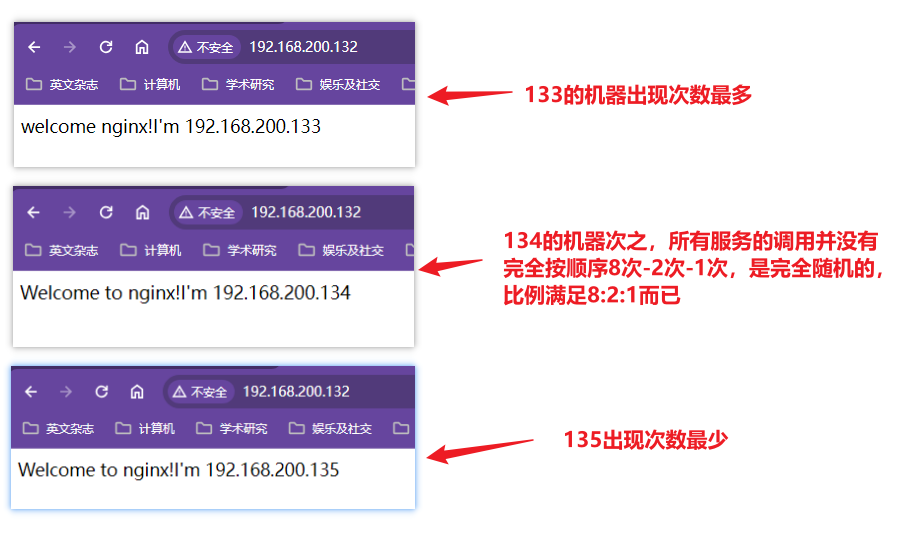
给每台服务器设置权重值,有的服务器配置比较高或者网络出口带宽比较高,比如133机器的网络带宽为1000M,134机器的网络带宽为100M,设置133的权重为8,设置134的权重为2,设置135的权重为1;使用nginx代理服务器做负载均衡,每八次请求访问133机器后,每两次请求访问134机器,每一次请求访问135【并不是完全按照8-2-1的顺序执行的,是多次请求中的访问比例满足8:2:1】
nginx.conf
配置被代理服务器的权重是在upstream中server后面配置weight属性
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.200.133:80 weight=8;server 192.168.200.134:80 weight=2;server 192.168.200.135:80 weight=1;}server {listen 80;server_name localhost;location / {proxy_pass http://proxyServers;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}测试效果
Down服务下线
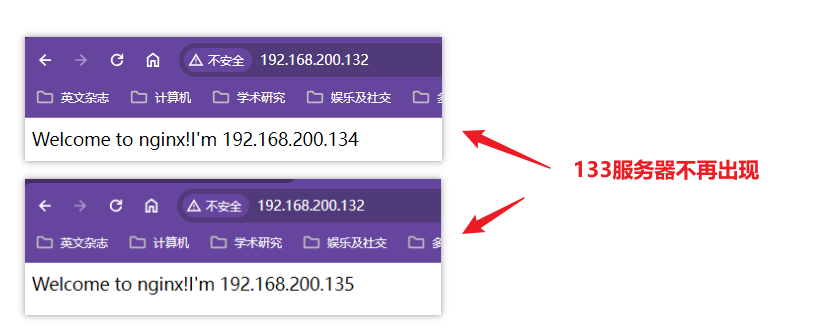
down可以让某些机器不参与负载均衡,相当于服务直接下线,不再提供服务
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.200.133:80 weight=8 down;server 192.168.200.134:80 weight=2;server 192.168.200.135:80 weight=1;}server {listen 80;server_name localhost;location / {proxy_pass http://proxyServers;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}测试效果
Backup备用服务器
备用服务器,指正常情况下不使用被backup标记的服务器,只有其他的机器实在没得用了,才用备用的服务器
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.200.133:80 weight=8 down;server 192.168.200.134:80 weight=2 backup;server 192.168.200.135:80 weight=1;}server {listen 80;server_name localhost;location / {proxy_pass http://proxyServers;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}测试效果
使用命令
systemctl stop nginx能停掉nginx服务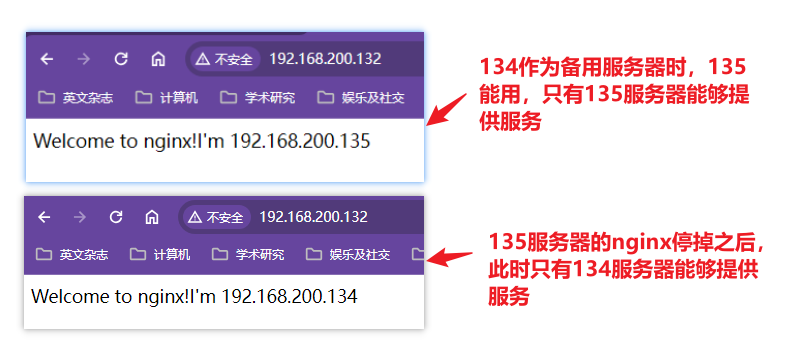
其他负载均衡策略
除了轮询和权重,其他的负载均衡策略声场上基本不使用,只做了解即可,最核心的问题是这些负载均衡策略无法做到服务器动态上下线,即即时的上下线服务器;类似hash值映射服务器的对应映射都写死在配置文件中,服务器上下线非常的不灵活死板,特殊场景使用这些方式需要结合Lua脚本在nginx中去编程来动态的管理当前服务器列表,可以动态的监测后端服务器的上下线情况,用程序配置权重值,做定向流量转发以及定向用户转发【定向用户转发存在严重的流量倾斜问题,非常容易造成几台服务器繁忙,几台服务器空闲的情况】,实际生产要么直接使用轮询的方式【存在无法保持会话的问题】,要么就用lua脚本去自定义请求转发规则,直接使用第三方插件的方式非常不灵活
轮询存在无法保持会话的问题:用户登录tomcat服务器,会将用户的状态存储在session中,这个用户状态只是存储在当前这一台tomcat服务器中【但是不是可以通过token令牌实现单点登录吗? 】,其他tomcat服务器中没有存储对应的session,此时用户的访问会被拒绝,凡是需要session的操作都会出现问题,单纯使用轮询负载均衡策略是会出现问题的
ip_hash
nginx会根据请求来源的ip地址将来源相同的请求转发给同一台服务器
存在问题,比如手机的信号时好时坏【比如乘坐高铁飞机移动速度很快】,通信商为了维持信号,将信号切换了一个移动基站,此时ip地址变化,没法保证处在不同地方的移动请求一定访问同一台服务器,无法保持会话状态
所以一般也不会用ip_hash来做负载均衡保持会话状态
least_conn
最少连接数的访问,目的是让后端服务器更加均衡,原理是将每次请求转发到连接数最少的服务器上,
这种方式在实际生产中也有很大的缺陷,服务器的连接数少可能是考虑到机器性能给其配置的权重比较低,才会造成流量倾斜,
正常情况下,不同服务器之间的连接数差异很大这是不大可能发生的;
即使在新加入机器的时候,此时除了新加机器,其他服务器全部进入reload阶段,即不接收新的请求,只处理已经接收的请求,等到新加机器正式上线,所有服务器此时的连接数都趋近于0。只有比较耗时的请求,比如需要两分钟才能解决的请求,才会出现连接数偏差较大的情况,但是几乎见不到这样的请求处理方式【用户点击一下,等待2分钟跳转页面,如文件上传,异步任务呢?如文件上传下载服务器?我真牛逼,马上就讲了除非异步化的处理,以消息队列的方式等待慢服务处理完成以后讲处理状态通知给用户即可,也不需要业务服务器进行长时间的处理并让用户一直等待】,所以这种负载均衡方式没有常用的场景,权重方式下还要慎用,所以几乎看不着这种方式的使用
fair
这种方式需要使用第三方的插件,配置到原始的nginx中才能使用,这种方式根据后端服务器的响应时间来转发请求,这种方式也不是很合理,
响应时间长短还和网络延迟【交换机过热就会造成网络延迟比较高,当前服务器和其他服务器接入的网络交换机不是同一个,就可能存在网络延迟差异的情况,导致网络延迟小的服务器会短时间处理大量的请求,可能直接就将服务器压垮了】、业务逻辑有关系,如果只根据响应时间来判断转发逻辑,会造成短时间内响应时间短的服务器的请求突然急剧增加,短时间内就可能压垮服务器,实际响应时间长的服务器空闲的很,
因为存在流量倾斜的风险并且需要下载第三方插件,所以实际生产这种方式使用的也比较少
url_hash【定向流量转发】
url_hash默认也是不支持的,也需要第三方插件,url_hash是定向流量转发,不一定是定向的用户转发,ip_hash就是定向的用户转发,根据用户的请求url如
http://atguigu.com/register计算哈希值,相同哈希值的url转发到同一台服务器上,这就是定向流量转发,比如登录和注册的哈希值不同会转发到不同的服务器上,在这种情况下,会话状态也无法保持,比如刚注册就要用户登录,这种方式比较适合访问固定资源不在同一个服务器【比如100个文件散落在不同的服务器,此时就可以根据URL去定位文件在哪台服务器上】的场景使用,几乎只有这样一种情况才需要用到url_hash
通过$request_uri做负载均衡
使用场景:访问相同url会转发到同一个服务器,适合用在没有cookie的场景如手机APP,将jsessionid直接带在url的最后,即使相同的请求也能根据jsessionid的不同将用户分配到特定的服务器来管理会话【如果只是集群系统并不是分布式系统下能这么用吧,而且uri整体计算的哈希值也可能不同啊,为什么能保持会话,这不是和url_hash是一回事吗?】
这个是将系统扩容会话管理的时候讲的,不知道和url_hash有什么关联没
在不支持cookie的情况下【手机上的APP不支持cookie】可以直接把jsessionid直接带在URL的后面,根据用户的jsessionid来对用户进行会话管理【存疑,是对jsessionid做哈希还是对整个uri做哈希,对整个uri做哈希还是可能被派发到其他服务器上,一样无法维持会话,而且还得是单一系统的集群才行啊】
第二种情况就是类似url_hash的情况,当资源有所倾斜的时候,根据uri去确定资源位于哪一台服务器上【比如流媒体服务器,文件太大,不可能分发到所有的流媒体服务器上,也没有必要】,文件上传的时候根据请求的url算出哈希值放上对应的服务器【还是有一些问题,如做集群,其实都能解决,再代理一台给集群做负载均衡,虽然不太优雅,实际方案不了解,有机会学习一下】
会话状态保持
保持会话状态一般不用nginx自带的负载均衡策略,这些负载均衡策略为了会话状态保持业务方面肯定会出问题
轮询无法保持会话状态
ip_hash可以保持会话状态,但是这种方式并不好,存在严重的流量倾斜问题且移动端ip随基站变化会发送变化,
java中存在基于客户端的会话保持工具,因为后端服务器只要做到轮询就没办法做到有状态【有状态指在独立的服务器上存储用户的固定信息,比如session就是用户状态信息,服务器存储了session才会 】,解决方案:
springSession默认解决方案把session单独存在redis服务器上,根据请求的cookie在本机找session,找不到就去redis服务器上找session【这也是最基本的集群化session共享,session不会每台服务器都存一份】,这种方式不适用于高并发场景,
高并发情况下需要使用真正的无状态会话token;用户请求到nginx服务器,nginx服务器会转发到一台专门负责权限校验认证的服务器,当用户登录校验完权限后给用户下发权限,权限记录成一个比较长的字符串或者记录在文件中并根据用户登录时间和有效期限以及服务器密码生成加密token,将token下发到客户端,客户端无法对token进行更改,客户请求带token,服务器不存储客户状态,只拿token做校验,只有服务端有密码可以解开token的加密信息【?拿到别人的token在别的客户端使用怎么办,大佬们说是可以的,但是拿不到token,以后看能不能回答这个问题】,这也是现在比较主流的方式
动静分离
动静分离适合中小型的网站,大型网站一般不这么操作,因为小型网站的并发量不高,且需要分离出来的静态资源不是特别多,把这些静态资源挪niginx中,如果是大型系统那么文件就太多了【淘宝,用户上传的文件就非常多,买家秀,卖家秀,商品介绍都属于静态资源,不适合使用动静分离这种简单的技术架构,适合初创企业、网站H5内嵌到APP或者网站中展示,也适用于ERP系统等传统项目】
动静分离架构
动静分离可以起到给系统加速的作用,用户请求通过网关,很多时候只需要展示一些图片,js、css等静态文件;此时可以把这些文件放在nginx中,不让这些请求进入后端的服务器,因为一个网页一般都是一个动态响应的主页+内嵌的数个静态资源,不使用动静分离的情况下,所有的请求都会被代理到tomcat,一个网页可能会有上百个请求,还有nginx代理转发的过程,这样不好;如果把静态资源全部前移至nginx,让nginx来响应这些静态资源的请求,让tomcat专心于动态请求的处理,通过动静分离给系统加速
【传统静态资源架构】
用户请求被nginx代理到tomcat,原本项目全部部署到tomcat服务器的某个目录下如webApp,webApp中包含项目类似于SpringBoot相关的jar包,jar包的static目录中会包含一些静态资源,static目录下的静态资源可能存在文件无法上传的问题【可以通过配置配置在外部目录中】,第二个问题是tomcat会响应很多非动态的请求,用户请求打到网页,网页会内嵌很多的图片、css、js资源,一次请求无法完成任务,用户请求到tomcat,tomcat会返回一个主页index.html,这个主页中会镶嵌很多的图片等静态资源,用户此时还会发起请求给nginx,再被代理到tomcat上去找相关的静态资源
【多次请求说明】
www.jd.com的响应就是一个静态页面,这个响应一般是后端的动态服务器返回的静态页面,该静态页面关联了非常多的图片,css文件,js文件资源,会同时再次并发发起N多个请求给服务器,使用传统架构,这些请求都会并发打到tomcat上,而且页面只要移动,很可能还会发起新增请求,比如鼠标滚轮加载页面,课程演示时又多了100多个请求,都是页面内嵌的图片等静态资源;tomcat的功能主要响应动态的请求,将这些静态资源前置到nginx可以将动态请求和静态请求分离开,静态资源的请求不需要再被代理到tomcat,直接就被nginx处理了响应了
配置动静分离
传统项目经过这样的改造能够大大提高系统的并发量,因为静态文件全部都交给nginx来处理,nginx处理静态文件的能力和tomcat处理静态文件的能力不相上下,不像网上传闻nginx的QPS有两万,tomcat为800完全是胡扯,因为现在java、tomcat已经比较先进了,先进在于利用操作系统底层的NIO,操作系统内核支持高性能网络数据的传输,才能达到这么高的性能,但是每次建立连接tomcat还是会有额外的会话级别的开销,开销还是比nginx高,性能比nginx略低,但是低的不多,因为现在还有keepalive技术的存在,
tomcat服务器中的静态资源
tomcat动态服务器上的静态资源,tomcat跑在8080端口
没有资料,有资料我高低也部署一个
【tomcat中欢迎页的访问】
【源码】
F12Source选项卡下
nginx对tomcat服务器的初始配置
nginx和tomcat在两台虚拟机上,没有搭建项目,借用尚硅谷张一鸣老师的配置演示效果
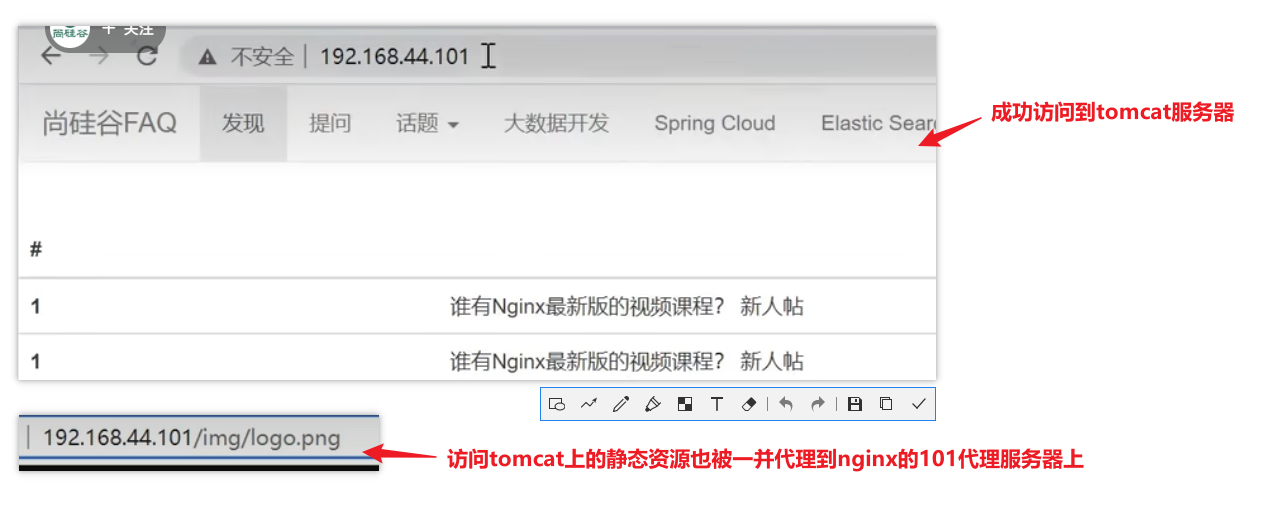
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.103:80 weight=2 backup;server 192.168.44.104:80 weight=1;}server {listen 80;server_name localhost;location / {#proxy_pass指向tomcat服务器的ip和端口proxy_pass http://192.168.44.104:8080;root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【测试效果】
104ip上的8080端口的tomcat成功101nginx代理服务器代理
访问tomcat过程解析
用户首次访问tomcat有一个会话的概念,即session,不管用户请求啥都会去检查session,而且tomcat运行在JVM中,执行效率从语言层面来说略低于nginx,首次连接tomcat会生成session并保持链接【keepalive】,因为keepalive可以复用之前的网络连接通道,不至于创建出无数个连接诶;比如同时有200个请求打个tomcat,可能中间会握手连接十几次,连接都会得到复用,因为大多文件请求是瞬时的过程,
以京东为例,请求后的页面加载不是一次性加载完毕,分多个阶段,当滚轮滑到一定位置需要展示时才会去加载资源,不至于资源加载请求的并发量特别的高,比如一次并发二三十个请求,建立十几二十个链接,再有这种请求时还会复用之前的连接,
tomcat还会利用底层的一些技术如epoll【高性能网络接口,网络数据传输变得很快,只是java和tomcat调用的系统底层实现】、
静态和缓存一类的东西利客户端越近越好,减少网路开销,在内网环境下,nginx转发静态资源请求给服务器,nginx再接收服务器的静态资源是没必要的开销,让nginx读取静态资源响应给客户端效率最高,资源开销最小
简单配置
缺点:根据请求路径匹配站点目录【路径匹配规则,优先匹配最长的,最长的匹配不了再匹配短的。所以先匹配下面的】,目录多的情况下location要配置非常多,不像虚拟主机的server_name的配置属性值能写很多个
nginx对静态资源的第一种简单配置
适用于静态资源少,目录少的情况
为了演示效果,上传完成后将104上的静态资源全部删掉
【删掉后的访问效果】
样式没了,下拉菜单也没了,部分图片也没了,注意此时nginx服务器上还没有对应的静态资源
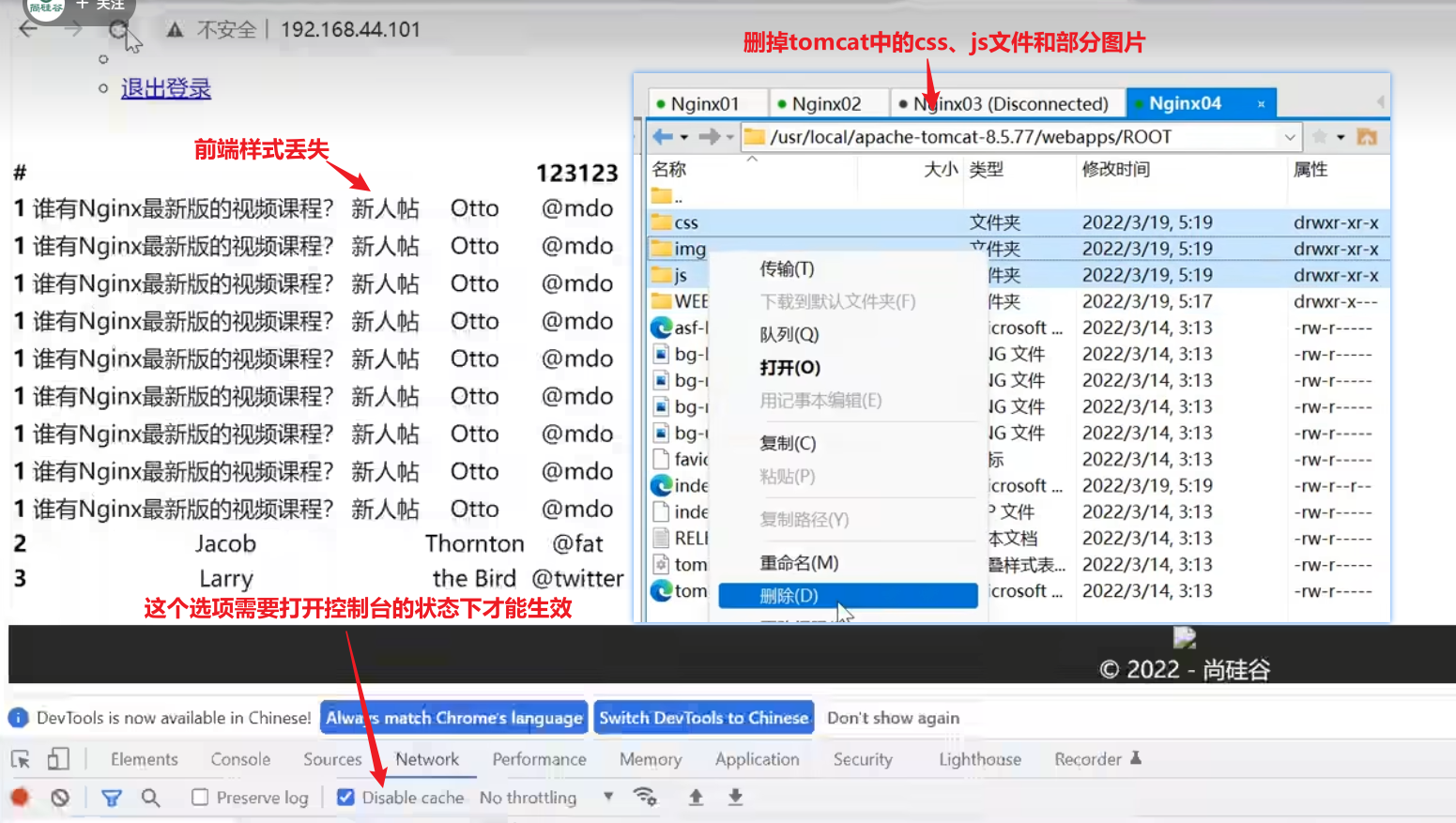
在nginx代理服务器上虚拟几个目录,将静态资源上传到nginx服务器对应的目录下,
【使用proxy_pass,配置目录失效】
此时考虑的是静态资源放在nginx服务器的哪个地方,因为使用poxy_pass,此时直接使用html目录是无效的,所有访问html目录下的请求都会被代理到配置的tomcat服务器上,此时考虑如何对静态资源目录进行配置,此时需要配置多个location【后面详细讲location配置规则】,使得根据请求路径判断文件的地址

【location即静态资源目录配置】
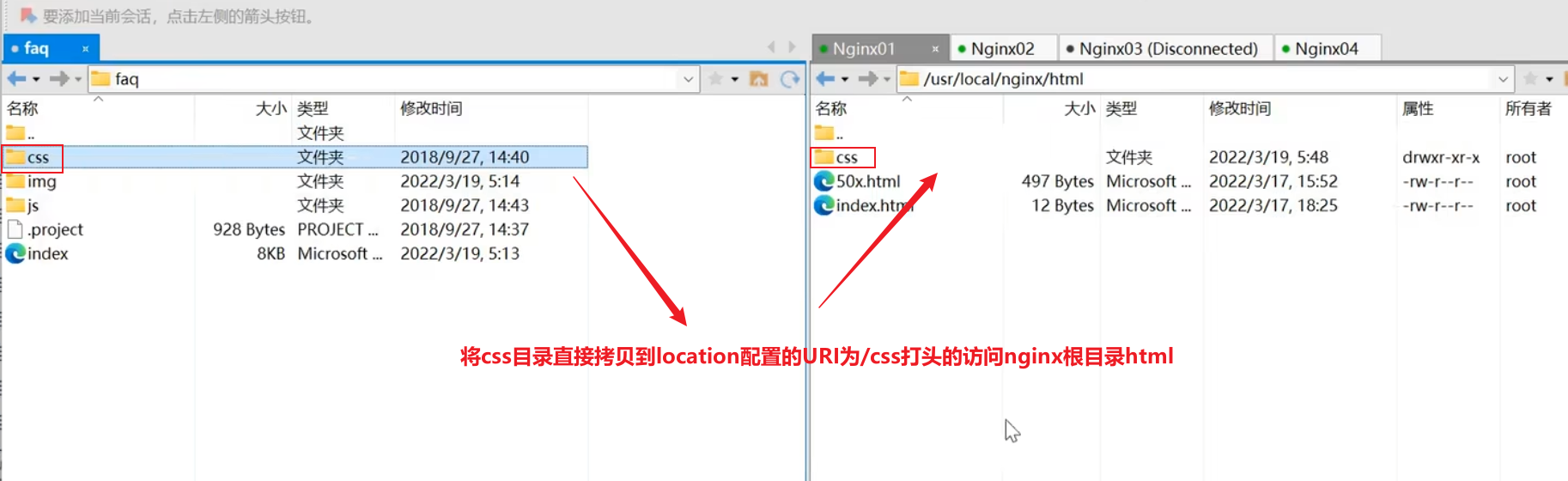
配置location添加站点URI以/css打头的访问nginx服务器下的html目录
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.103:80 weight=2 backup;server 192.168.44.104:80 weight=1;}server {listen 80;server_name localhost;location / {#proxy_pass指向tomcat服务器的ip和端口proxy_pass http://192.168.44.104:8080;}#uri打头为/css的请求会走nginx在该站点下的对应的根目录去寻找资源location /css {root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【将css文件拷贝到根目录下】
注意配置的uri打头为css,此时也只上传了css文件,并没有上传另外两个img和js文件到该目录下
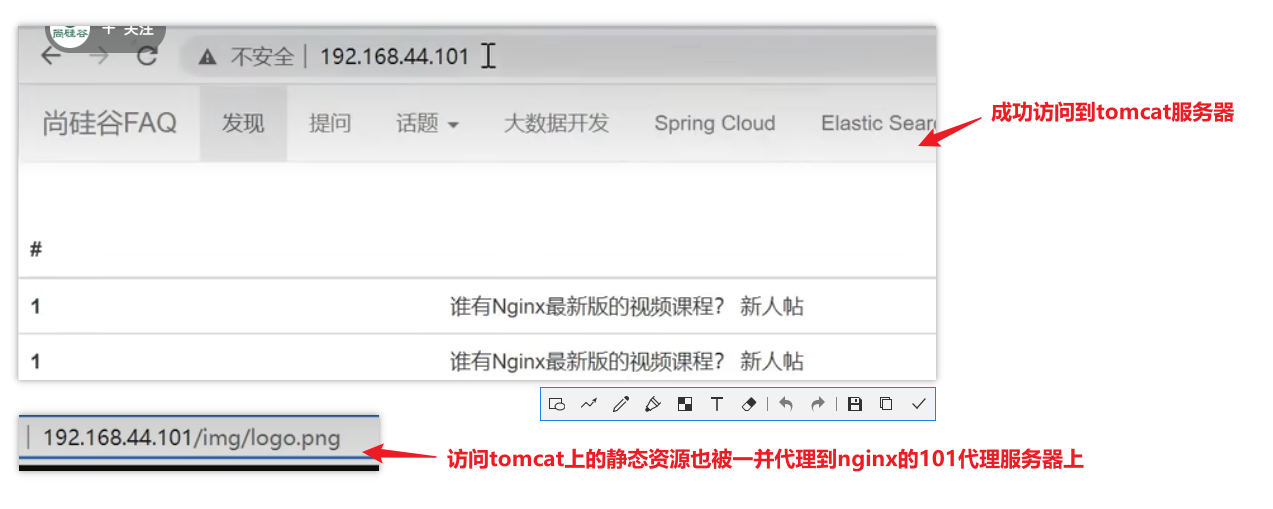
测试效果
此时样式已经有了,注意此时样式相关的文件在nginx服务器的根目录html下的css目录下,tomcat中的该文件已经删除
【对应css文件的请求路径】
uri打头带
/css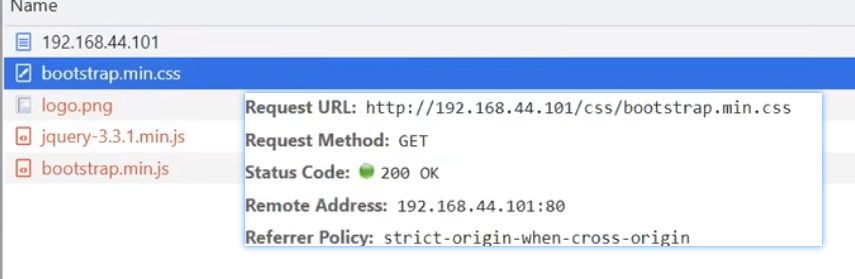
完整配置
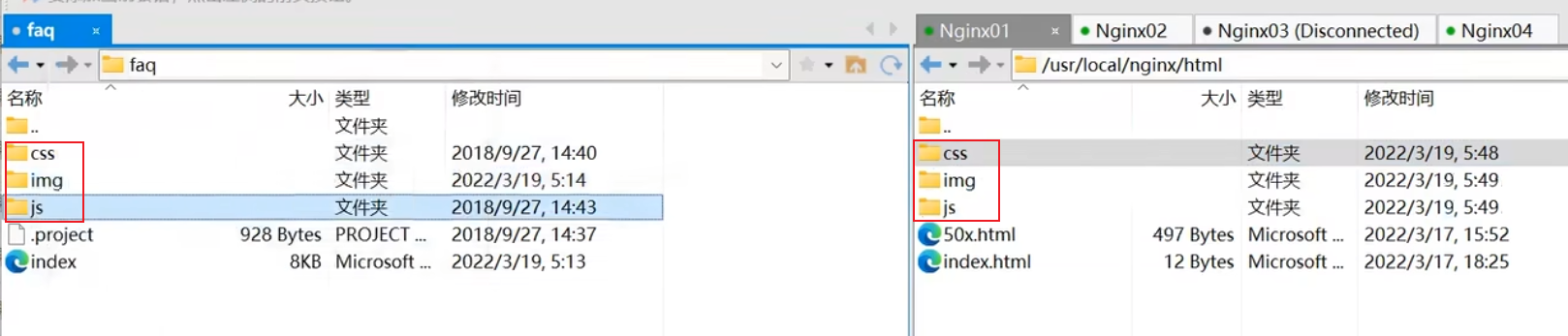
将静态资源目录都配置到nginx的html目录下,即将html目录配置为'/css','/js','/img'作为uri打头情况下的请求的资源根目录
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.103:80 weight=2 backup;server 192.168.44.104:80 weight=1;}server {listen 80;server_name localhost;#默认规则,匹配所有以'/'打头的请求URI,优先级比较低,测试过程能够看到凡是有/的子路径,就会去匹配请求的子路径/css,符合优先精确匹配的原则location / {#proxy_pass指向tomcat服务器的ip和端口proxy_pass http://192.168.44.104:8080;}#uri打头为/css的请求会走nginx在该站点下的对应的根目录html去寻找资源location /css {root html;index index.html index.htm;}#uri打头为/js的请求会走nginx在该站点下的对应的根目录html去寻找资源location /js {root html;index index.html index.htm;}#uri打头为/img的请求会走nginx在该站点下的对应的根目录html去寻找资源location /img {root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【静态资源文件上传】
不同字符打头的uri请求路径都要单独配置location,但是都可以配置成同一个根目录
最终测试效果
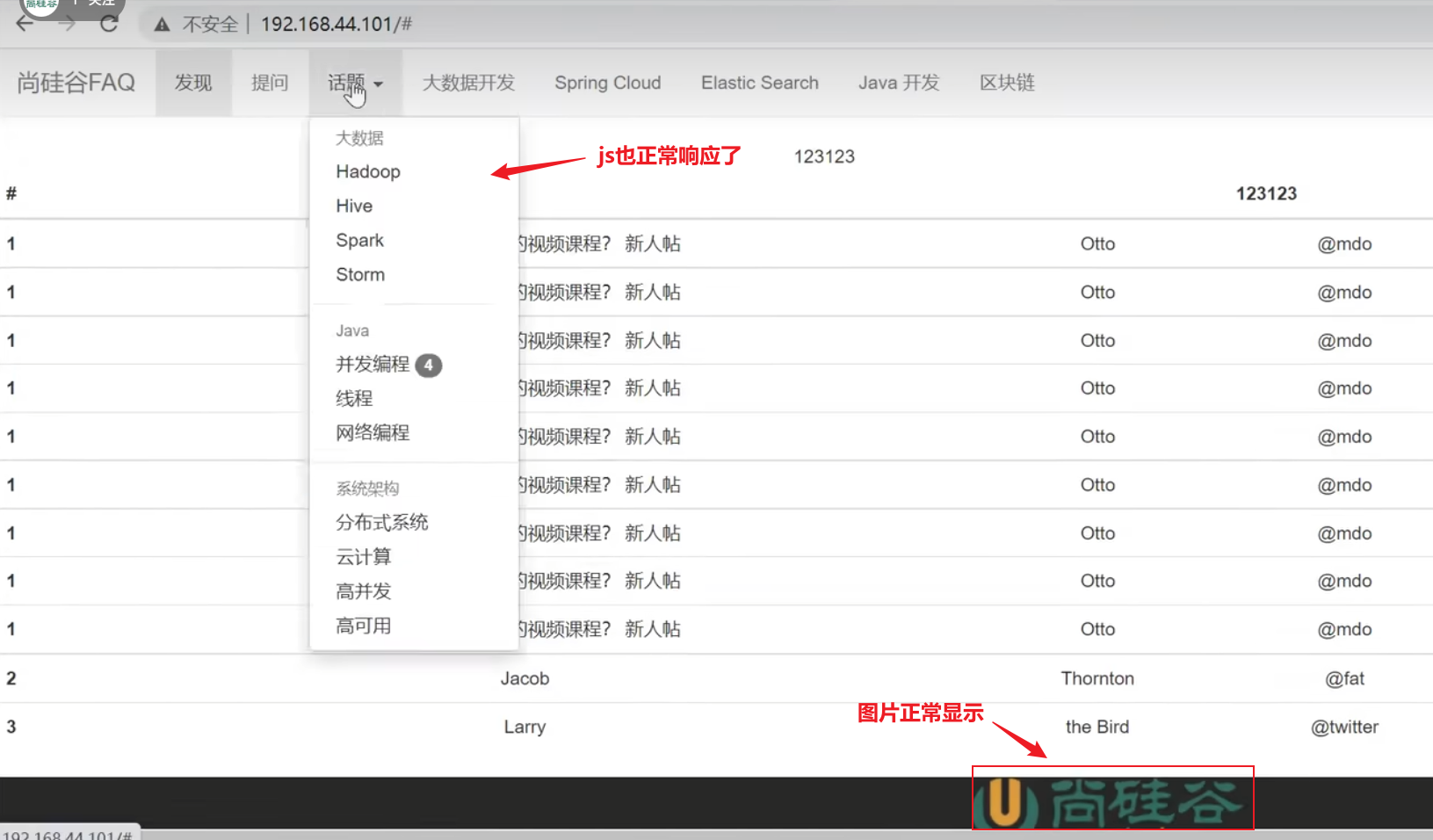
正则配置
写正则表达式可以将上述三个匹配路径合并成一个正则表达式,只需要多写一个location
配置详情
【nginx.conf】
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.103:80 weight=2 backup;server 192.168.44.104:80 weight=1;}server {listen 80;server_name localhost;#默认规则,匹配所有以'/'打头的请求URI,优先级比较低,测试过程能够看到凡是有/的子路径,就会去匹配请求的子路径/css,符合优先精确匹配的原则location / {#proxy_pass指向tomcat服务器的ip和端口proxy_pass http://192.168.44.104:8080;}# ~* 表示要开始写正则表达式了,区分大小写的正则 ~ 开头,不区分大小写的正则 ~* 开头,(css|js|css)表示\后匹配括号中内容, | 表示或,location ~*/(css|js|css) {root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}测试效果
开启Disable cache的情况下反复刷新,让请求不要走缓存
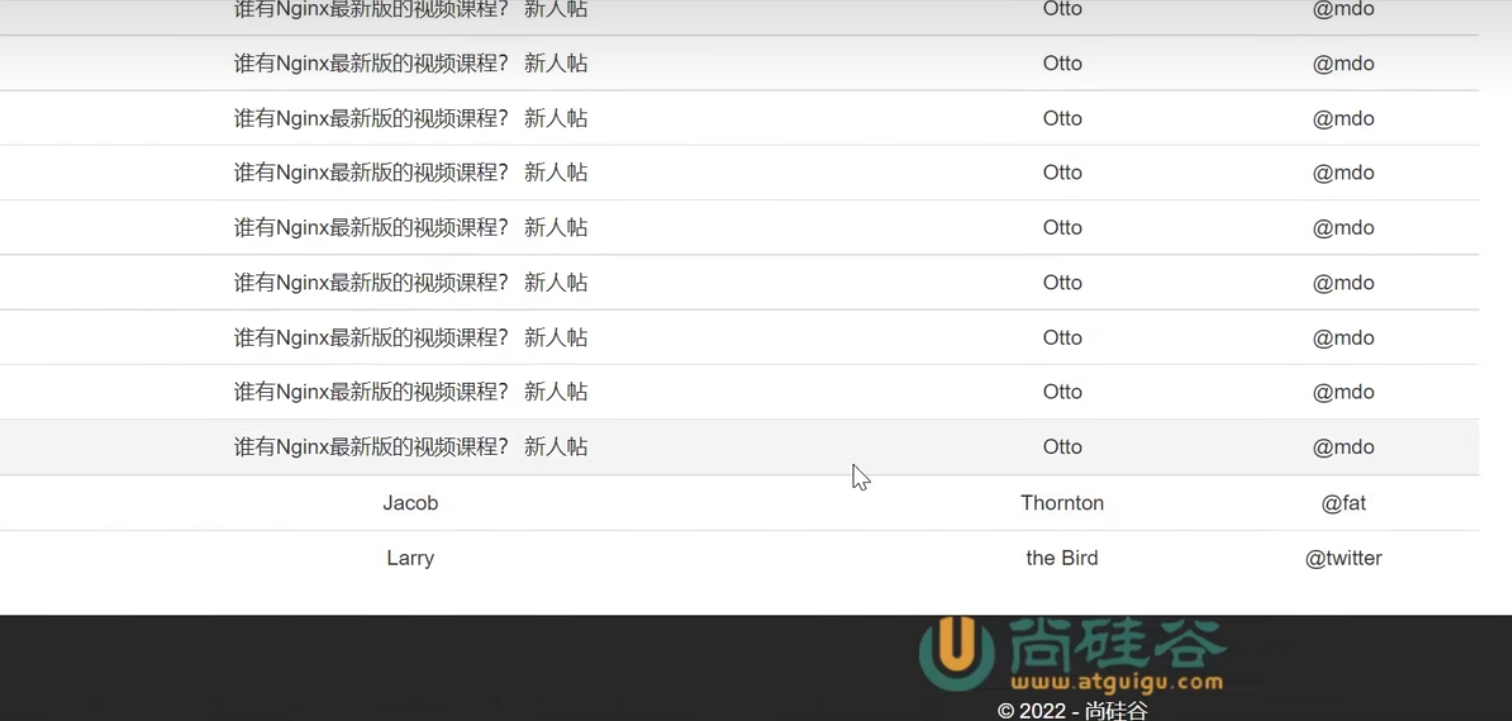
动静分离存在的问题
注意使用nginx管理静态css、js文件和图片,此时再直接访问tomcat服务器,tomcat中没有对应的静态资源,页面的样式、js函数和照片都无法加载
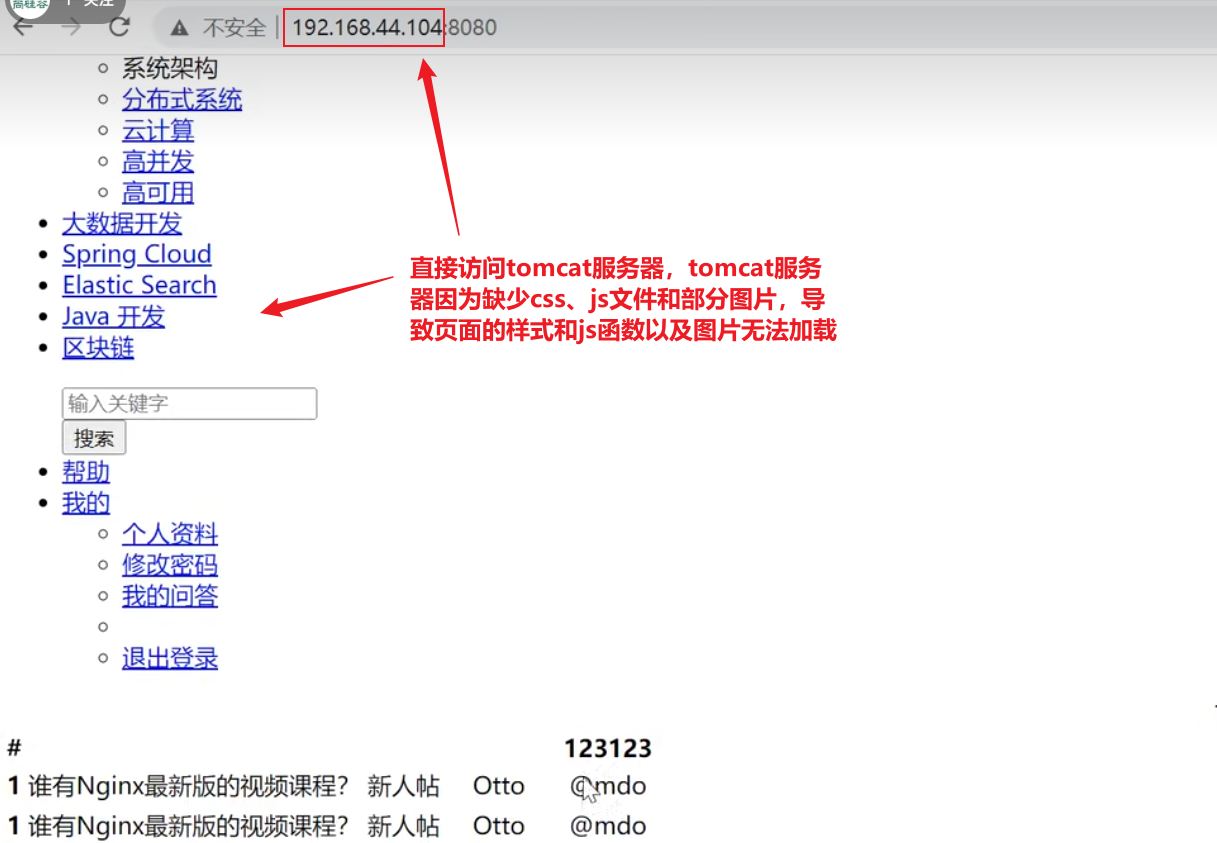
URLRewrite
能够隐藏真实的后端地址
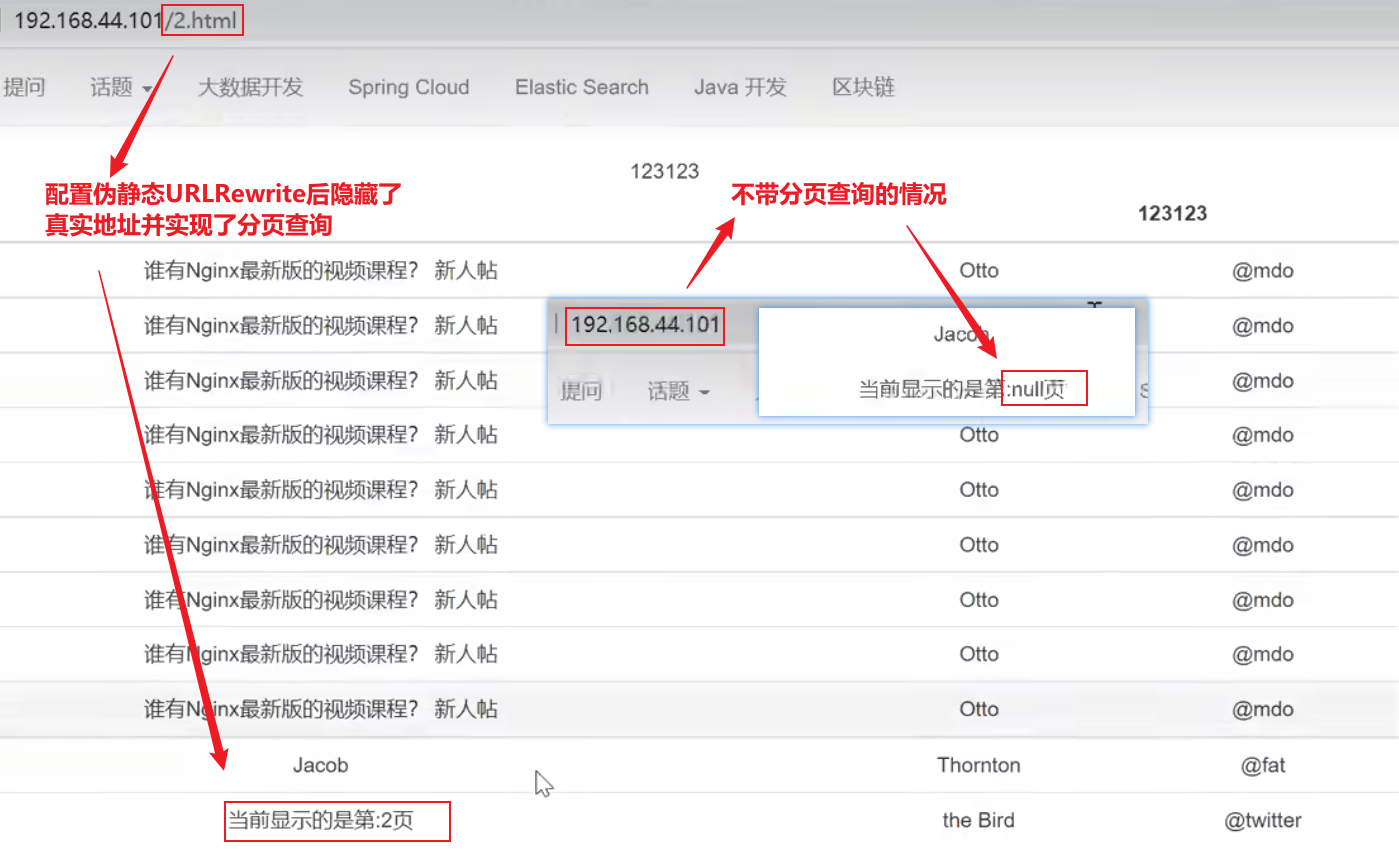
http://192.168.44.101/index.jsp?pageNum=2这是查询分页评论的链接,连接长且暴露入参,可以将该连接隐藏起来,让请求连接伪静态变成http://192.168.44.101/2.html
配置URLRewrite伪静态
通过proxy_pass同一个站点的rewrite关键字指定,属性值使用正则表达式
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.103:80 weight=2 backup;server 192.168.44.104:80 weight=1;}server {listen 80;server_name localhost;#默认规则,匹配所有以'/'打头的请求URI,优先级比较低,测试过程能够看到凡是有/的子路径,就会去匹配请求的子路径/css,符合优先精确匹配的原则location / {#正则表达式以^开头,以$结尾,正则表达式匹配访问nginx服务器的该站点下的URI部分;演示用的是静态的形式,即定死2.html,入参也定死了2#/index.jsp?pageNum=2是真实的访问地址;#最后的break是请求转发的形式,转发形式FLAG 有 4 种:break、last、redirect、permanent;break 表示本条规则匹配完成即终止, 不再匹配后面的任何规则。rewrite ^/2.html$ /index.jsp?pageNum=2 break;#proxy_pass指向tomcat服务器的ip和端口proxy_pass http://192.168.44.104:8080;}# ~* 表示要开始写正则表达式了,区分大小写的正则 ~ 开头,不区分大小写的正则 ~* 开头,(css|js|css)表示\后匹配括号中内容, | 表示或,location ~*/(css|js|css) {root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}伪静态页面配置效果
显示的是访问静态资源2.html,但是本机实际没有2.html这个资源
不足:没有介绍怎么实现动态的将客户端的参数传递给实际的请求地址,仅仅只是配置了一个静态页面
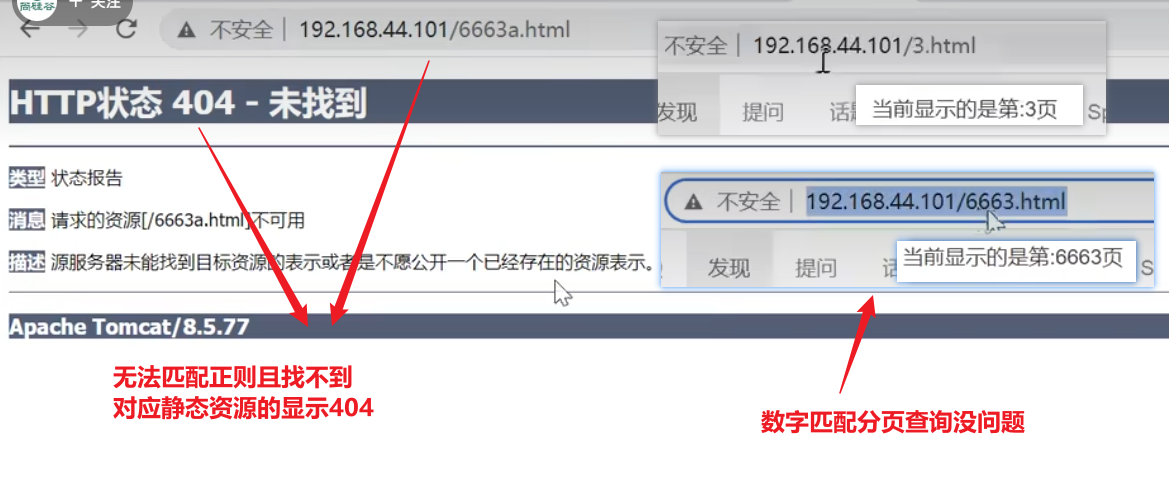
配置动态参数的伪静态URLRewrite
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.103:80 weight=2 backup;server 192.168.44.104:80 weight=1;}server {listen 80;server_name localhost;#默认规则,匹配所有以'/'打头的请求URI,优先级比较低,测试过程能够看到凡是有/的子路径,就会去匹配请求的子路径/css,符合优先精确匹配的原则location / {#[0-9]+表示匹配任意位数字,正则表达式中使用小括号括起来的部分表示URLRewrite时用来入参的参数,实际地址中的$1表示入参选择正则表达式中第一个括号括起来的内容,如果有第二个入参可以用$2表示使用第二个括号括起来的参数,可以使用多个参数rewrite ^/([0-9]+)$ /index.jsp?pageNum=$1 break;#proxy_pass指向tomcat服务器的ip和端口proxy_pass http://192.168.44.104:8080;}# ~* 表示要开始写正则表达式了,区分大小写的正则 ~ 开头,不区分大小写的正则 ~* 开头,(css|js|css)表示\后匹配括号中内容, | 表示或,location ~*/(css|js|css) {root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}配置效果
根据客户端地址的参数将入参参数动态的传递给真实请求地址
参数说明
rewrite是实现URL重写的关键指令,根据regex (正则表达式)部分内容,重定向到replacement,结尾是flag标记。
rewrite/*关键字*/ <regex>/*正则*/ <replacement>/*替代内容*/ [flag]/*flag标记*/参数要领
关键字:关键字中的error_log不能改变,rewrite关键字可以使用的标签段位置:server、location、if;
正则:perl兼容正则表达式语句进行规则匹配
替代内容:将正则匹配的内容替换成replacement
flag标记:rewrite支持的flag标记,有四种
rewrite关键字有优先级区分,break的优先级最高,
flag标记类型 标记含义 last 本条规则匹配完成后,继续向下匹配新的location URI规则,一直匹配到配置文件最下面的URI规则 break 本条规则匹配完成即终止,不再匹配后面的任何location URI规则,继续执行后续的proxy_pass redirect 返回302临时重定向,响应页面后浏览器地址会显示配置文件中当前页面真实的URL地址 permanent 返回301永久重定向,浏览器地址栏会显示跳转后的URL地址 【flag标记为redirect的显示效果】
相当于nginx发起302请求,让客户端自己重定向到真实地址
临时重定向和永久重定向对用户来说没有区别,是给网络爬虫看的,比如百度来爬取网页,临时重定向以后还可以爬取,永久重定向永远记录重定向地址,这里讲的不清楚,无伤大雅,有机会了解网络爬虫再结合学习
注意:重定向ip地址还是nginx的地址192.168.44.101,不是tomcat104的地址

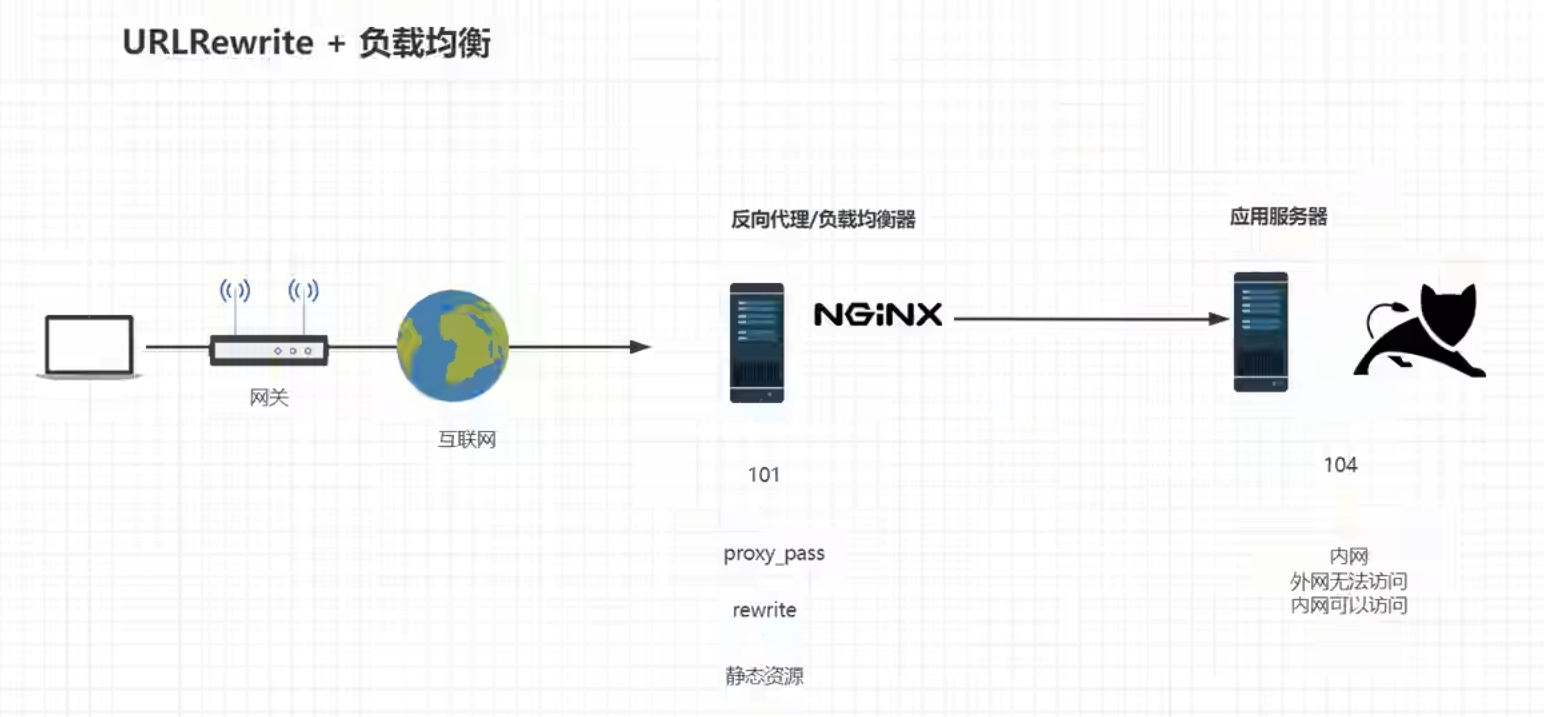
网关服务器
同时带有代理服务器、负载均衡和URLRewrite功能的服务器就能被称为网关服务器,网关配置可以直接用cloud的gateway的filter的RewritePath去写,可以不用nginx配置
目前nginx已经用上了反向代理、负载均衡、动静分离和URLRewrite的功能了
当前系统架构
nginx在此处担任起了反向代理,动静分离和URL重写的作用,此时直接访问tomcat会导致一些资源无法访问,需要设置tomcat只能从内网访问,不能从外网访问;
设置防火墙关闭tomcat外网访问
直接开启防火墙不设置端口通讯会切断一切外网tcp端口的连接,但是注意这种情况下xshell还是能连接的,此时打开tomcat所在的8080端口,但是又不希望外网访问到,只希望nginx能访问到
使用命令
firewall-cmd --permanent --add-rich-rule="rule family="ipv4" source address="192.168.44.101" port protocol="tcp" port="8080" accept"添加nginx反向代理服务器的ip地址192.168.44.101为可信任的ip地址,并对该地址在104机器上开启tcp协议上的8080端口通讯此时104机器上的tomcat只能被反向代理服务器101访问,外网已经访问不了该tomcat了,实现了不介入互联网,通过nginx反向代理服务器将一切资源转交给外网,如果nginx挂掉了,在这种配置的前提下这台tomcat服务器就彻底访问不到了
此时nginx就相当于tomcat服务的大门,大门一旦关闭了tomcat服务器的任何服务都访问不了了,此时nginx换个更专业的名字就是网关服务器,之前叫代理服务器、负载均衡器都很片面,无法包含他的一切功能【反向代理服务器、负载均衡器、URLRewrite、】
整合nginx的反向代理、负载均衡、URLRewrite完整功能
proxy_pass使用upstream时ip和端口号都写在upstream中,rewrite还是写在proxy_pass的上面,只是匹配uri
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.104:8080 weight=1 backup;}server {listen 80;server_name localhost;location / {rewrite ^/([0-9]+)$ /index.jsp?pageNum=$1 break;proxy_pass http://proxyServers;}location ~*/(css|js|css) {root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}访问效果
102服务down了,此时只会显示备用的tomcat服务器
防盗链
防盗链指存在服务器上的资源只能由我们自己的服务器进行访问,其他引用的服务器无法访问,
盗链
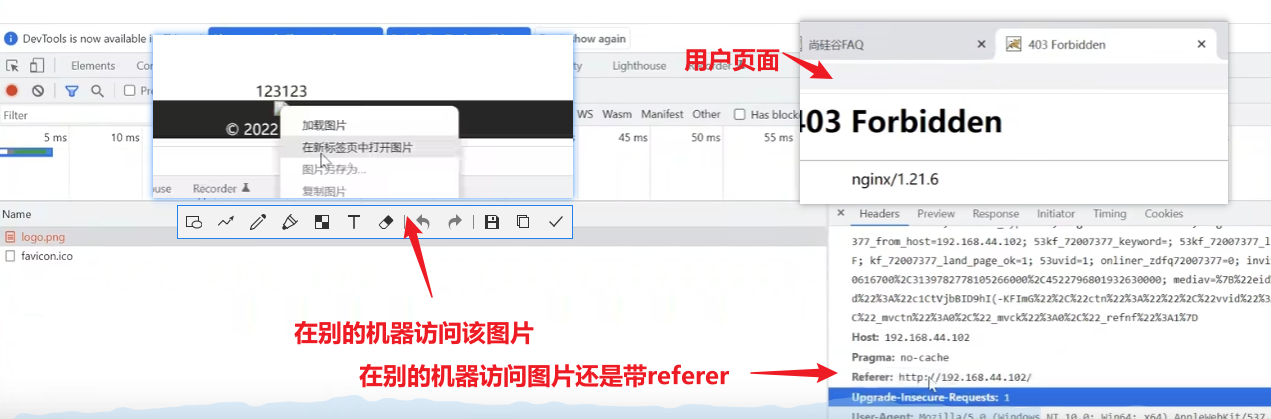
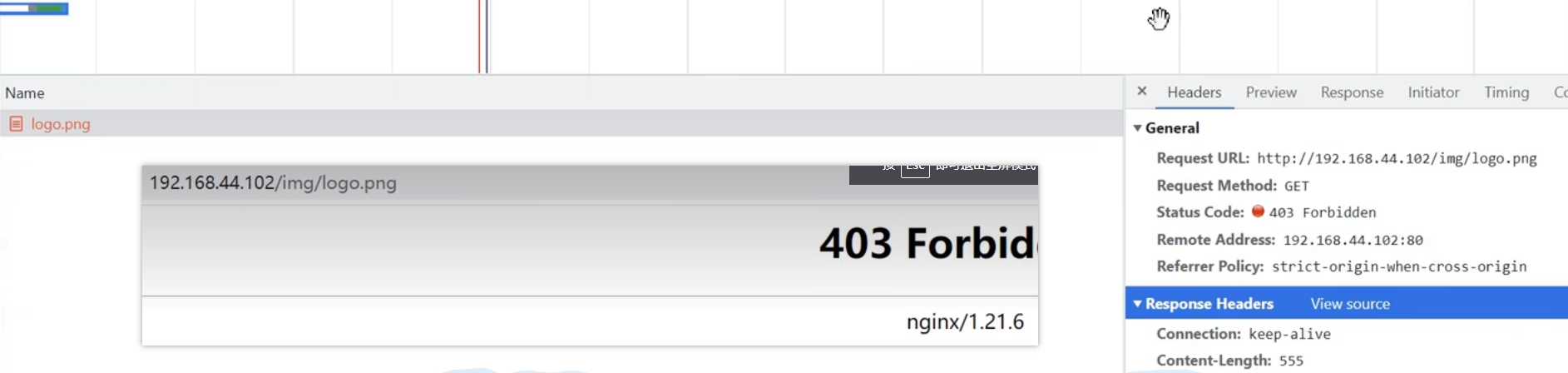
当用户访问某个主页,主页响应以后会二次甚至多次去请求当前站点主页中用到的引用资源【css、js文件和图片资源】,二次请求的时候会在请求的时候在请求头中添加referer参数,参数值就是首次请求的请求地址的URL,这是http协议规定的,由浏览器遵守的规定,只会出现在二次请求中,首次请求的请求头中是没有的,表示本次请求是从第一次请求的响应页面过来的;
此时可以根据请求头中是否含有referer属性来判断该请求的来源是一次请求响应结果进行的二次请求,还是某个用户单独进行的请求【用户无法操纵请求头中的referer的属性值,因为网络数据想要安全,涉及到的HTTP协议内容都必须由浏览器本身来进行填充?但是我试过向请求头中添加token】
如果别的站点对相同资源进行了引用,二次请求时可以根据请求头中的referer属性判断对资源的请求是否是自己的站点,因为referer属性是浏览器进行填充的,合法的浏览器是无法进行篡改的,如果不是自己的站点就可以判断是非法请求【说明有其他的网站引用了自己不想让别人引用的资源,允许别人引用就不需要对防盗链进行配置】;
一般来说,网站上的资源希望别的站点使用,增加曝光量,不是所有的资源都需要防盗链;一般防盗链的使用场景如公众号上的图在自己的网站上引用就会提示不能在外地引用该图片资源【也是不缺流量或者资源的size很大,或者资源很稀缺,只希望用户只能在该站点才能看到该资源才会这样设置】
防盗链配置
新建一个站点102,配置站点102的proxy_pass为101,此时访问102会直接跳到101,

此时我们想实现被别的站点代理的二次请求的css、js和图片文件不能被访问的配置方法
更改101的配置文件nginx.conf【此时101是静态资源存放的服务器】
需要把对资源的限本站点访问的设置配置到资源站点即location下,不能配置在service下
本例中不希望css、js文件和图片不能被访问,需要配置在
location ~*/(css|js|css)站点下xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#因为proxy_pass已经指向tomcat服务器的ip和端口号,这个upstream实际已经不认识了,但是不会报错,显示也应该只显示tomcat服务器内容upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.104:8080 weight=1 backup;}server {listen 80;server_name localhost;location / {rewrite ^/([0-9]+)$ /index.jsp?pageNum=$1 break;proxy_pass http://proxyServers;}location ~*/(css|js|css) {#检测二次请求的主机ip是否符合配置项,设置有效的referer的ip为101,如果访问的referer不是有效的referer,就返回错误码403,该站点下的下述配置指定站点目录的配置就不走了,就达到了访问该站点下限制访问的静态资源的站点目录找不到了#有效的ip可以设置多个,referer为这些ip的时候可以不限制访问valid_referers 192.168.44.101;#注意此处if和()之间必须有空格if ($invalid_referer) {return 403;}root html;index index.html index.htm;}#出错跳转nginx目录下的错误页error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}配置效果

【请求状态】
二次请求的response中没有数据,头信息中的状态码为403
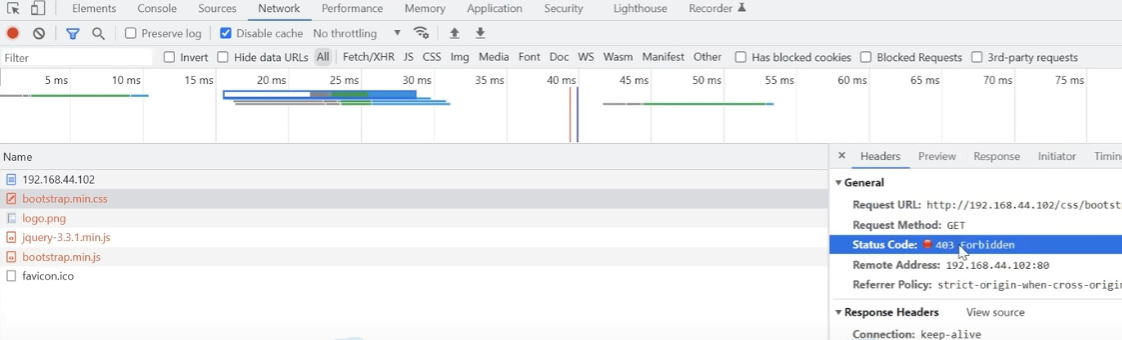
【其他服务器单独访问图片效果】
仍然无法访问,还是报错403
【地址栏输入地址访问效果】
不仅是引用访问非法,直接地址栏访问也是不行的,直接在地址栏输入其他服务器ip加资源路径也是不行的,只要访问了非本机服务器,而是中途被代理的服务器,就无法访问被限制访问的资源,只能访问对应的站点才能访问相应的资源
也可以使用none关键字配置非应用但是地址栏访问允许的设置,即检测到请求中不带referer就允许访问
配置非引用状态下的资源允许访问
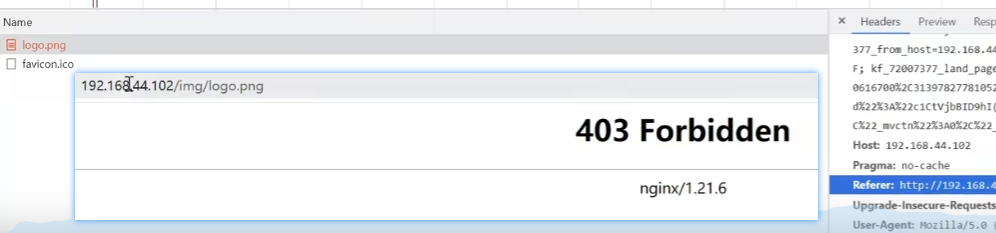
从被引用界面点击新标签打开图片,这种情况下带referer,这种情况下是无法访问的,虽然地址栏的地址是一样的,只能通过在地址栏输入地址且请求头不带referer属性才能访问加了none关键字对应资源
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.104:8080 weight=1 backup;}server {listen 80;server_name localhost;location / {rewrite ^/([0-9]+)$ /index.jsp?pageNum=$1 break;proxy_pass http://proxyServers;}location ~*/(css|js|css) {#添加了none关键字,此时请求非引用即不带referer就可以从别的服务器访问对应的资源,但是引用不可以valid_referers none 192.168.44.101;if ($invalid_referer) {return 403;}root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【地址栏直接访问效果】

【通过引用在新标签打开图片的方式访问效果】
带referer不行
关键字意义
none, 检测 Referer 头域不存在的情况。即请求没有referer属性即是直接访问不是引用访问的情况
blocked,检测 Referer 头域的值被防火墙或者代理服务器删除或伪装的情况。这种情况该头域的值不以“http://” 或 “https://” 开头。
不常用,即请求的
referer不带http或者https的情况下资源可以访问,目前可以看到referer中是带http的
使用curl测试防盗链
curl工具,该工具是linux系统下的工具,默认不会安装,windows是自带的,curl在做测试方面更加纯粹,更加方便一些;浏览器为了给用户做访问加速会在多个地方做缓存,导致用户刷新时可能无法即时刷新最新的页面,可以使用curl测试配置是否生效更加方便准确
使用命令
yum install -y curl在linux上安装curl使用命令
curl -I http://192.168.44.101/img/logo.png对目标地址发起请求,返回响应的头报文信息,不带-I会完整的显示响应内容,包括响应体使用命令
curl -e "http://baidu.com" -I http://192.168.44.101/img/logo.png对目标地址发起带引用的访问请求,即在请求头信息中添加referer参数注意,带引用的引用值不匹配设置的引用值,即使是访问原服务器地址的资源请求也一样会返回设置的403错误码
防盗链友好提示配置
实际生产中防盗链拒绝访问不会直接返回错误码,会响应一个对应错误提示的图片或者错误的提示页面
防盗链生效返回错误提示页面
在101服务器的根目录html中创建对应的错误页面401.html
在nginx.conf中配置错误代码对应的站点资源
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.104:8080 weight=1 backup;}server {listen 80;server_name localhost;location / {rewrite ^/([0-9]+)$ /index.jsp?pageNum=$1 break;proxy_pass http://proxyServers;}location ~*/(css|js|css) {#添加了none关键字,此时请求非引用即不带referer就可以从别的服务器访问对应的资源,但是引用不可以valid_referers none 192.168.44.101;if ($invalid_referer) {return 401 ;}root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}error_page 401 /401.html;location = /401.html {#在root目录即html目录下去找资源401.htmlroot html;}}}访问效果
在页面引用中还是和原来一样,原因是文档的编码方式和图片的编码方式不同,当单独在新地址栏带引用访问对应资源就会显示错误页信息
整合URLRewrite返回报错图片
当引用的图片发生拒绝访问的情况,如果是跳转一个报错页面,内嵌于引用网页的图片不能显示对应的报错页面,但是这种方式本质上已经消耗了本地服务器的流量,请求经过处理也响应了内容,用URLRewrite的方式能返回一个友好提示的图片替代原来访问的图片
准备好对应的友好提示图片x.png【名字随意】,
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.44.102:80 weight=8 down;server 192.168.44.104:8080 weight=1 backup;}server {listen 80;server_name localhost;location / {rewrite ^/([0-9]+)$ /index.jsp?pageNum=$1 break;proxy_pass http://proxyServers;}location ~*/(css|js|css) {#添加了none关键字,此时请求非引用即不带referer就可以从别的服务器访问对应的资源,但是引用不可以valid_referers none 192.168.44.101;if ($invalid_referer) {rewrite ^/ /img/x.png break;#需要用图片提示友好信息,要注释掉返回的错误码,使用rewrite来指定满足条件后的真实访问地址#return 401 ;}root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}error_page 401 /401.html;location = /401.html {#在root目录即html目录下去找资源401.htmlroot html;}}}引用图片访问效果
nginx的高可用配置
高可用配置【Highly Available】,一台nginx做代理服务器、负载均衡器可能会发生单点故障导致后端服务完全不可用,此时要考虑配置多台nginx服务器来避免nginx不可用的情况,
此时会发生要实现nginx的切换或者nginx服务器的负载均衡需要再加一台代理服务器或者负载均衡器在nginx服务器集群之前,但是此时又会存在负责nginx服务器集群服务器切换和负载均衡问题的服务器需要设置集群,那么这样永远存在不停地在nginx服务器集群前加机器的问题,这样在nginx服务器集群前加机器控制nginx服务器的切换无法解决nginx服务器集群的控制切换问题
通过keepalived技术可以实现在不在nginx服务器集群前加机器的前提下实现nginx服务器的切换和控制,keepalive就是一个小小的软件,跑在nginx服务器集群的每个nginx服务器中,keepalived的作用是实现不同机器上的keepalived的通讯,检测集群中机器是否存在宕机,
nginx集群的运行
局域网内不同的nginx服务器的ip地址不能相同,用户请求主要用111的nginx服务器进行请求代理,如果nginx服务器111挂掉,keepalived会发现111机器挂掉,并将用户请求代理的地址改成112nginx服务器
但是如何判断一台机器是真的宕机了,还是假死状态【交换机过热、网络分区故障】,
网络分区故障:机房一个机柜中存在多台不同ip的主机,每个机柜对应有自己的小型交换机,如果交换机和交换机之间发生了通讯故障就发生了网络分区故障【即同一个机柜中不同ip的机器之间的通讯没问题,由于交换机之间的通讯故障,两个机柜之间的机器通讯断掉了,即网络分区故障】
当发生故障原nginx服务器假死,如果此时通过修改新nginx服务器的ip地址为原故障nginx服务器的ip【两台nginx服务器所处的机柜不同】,当原nginx服务器正常恢复以后,会发生ip冲突的情况;
多个nginx服务器是以主从的方式对外提供服务,并不会同时对外提供服务,从nginx服务器作为主服务器的备用,如果同时对外提供服务就变成了集群的形式,
如果采用主机宕机,将主机的ip直接切成备用机的ip,即修改备用机的ip为主机ip,此时在逻辑上确实能实现nginx服务器的切换,但是在使用场景中存在nginx服务器假死导致原nginx服务器重启发生两台nginx服务器ip地址冲突的情况
解决办法:
在局域网内虚拟出一个ip地址,术语叫做虚拟IP【VIP】,keepalived不去修改nginx服务器的真实ip地址,而是将虚拟IP来回漂移指向不同真实ip的nginx服务器,而用户直接访问入口的是虚拟IP【基于VRRP实现】,
一旦主机宕机,虚拟IP漂移到备用机上,如果此时主机恢复,此时涉及到主机的竞选机制,可以通过配置机器优先级【优先级越高,竞选称为主机的概率就越高】、keepalived只负责对虚拟IP进行漂移,不会修改真实的IP,不会导致出现较大的问题
注意,一台主机可以配置多个IP地址,不是一个机器只有一个ip地址,一个网卡【不是网关】上也可以配置多个地址,【一个机器可以有多个网卡,不同的网卡接入不同的网络,比如一个网卡接内网访问后端的应用服务器,另一个网卡接外网来接入电信、联通等主干网】,一个网卡上还可以配置好多个ip,只是最好不要配置太多
keepalived实现将用户的请求从主机迁移到备用机上,因为用户访问的ip一般不能主动更改【ip解析也不能老是更换,因为用户本机上的DNS缓存的域名解析还没来得及更新】,解决办法就是用户固定访问的ip地址在不同物理ip的机器上来回漂移
keepalived
keepalived是比较简单的软件,原理是检测keepalived的进程是否存在,不是依靠特别高明的机制,keepalived进程如果存活,就能相互之间发送数据包进行通信,如果无法通信了,就把虚拟IP按优先级漂移到可以通信的机器上
keepalived还可以通过编写脚本来控制keepalived监听的具体进程,当前keepalived只是监听自身的进程,并没有监听nginx的进程,如果nginx出问题但是keepalived没出问题,虚拟IP也是无法漂移的;脚本和keepalived也是分开的,和nginx也是分开的,脚本运行在目标机器上,三者唯一的联系就是运行在同一台机器上,脚本在设定时间间隔检测nginx当前是否报错,响应请求是否正常的200,如果连续监测到nginx的响应码不是200,就会将keepalived的进程kill掉,从而实现虚拟IP的漂移【此处不讲,可以自己研究一下】
keepalived的选举方式也很简单,就是根据配置文件优先级确定的,一旦新加入一台机器的keepalived的优先级更高,就自动将当前master改成BACKUP了,keepalived的应用不止nginx,是对主机和进程的检测,只是检测机器的keepalived是否或者,所以可以检测一切服务如多态mysql、redis、消息中间件、应用服务器等,都可以通过脚本检测进程运行状态,设定条件杀死keepalived进程实现虚拟IP的漂移
安装keepalived
编译安装
解压安装包,在当前目录下使用命令
./configure查看安装环境是否完整,如果有如下报错信息需要使用命令yum install openssl-devel安装openssl-devel的依赖xxxxxxxxxxconfigure: error:!!! OpenSSL is not properly installed on your system. !!!!!! Can not include OpenSSL headers files. !!!编译安装以前安装过,后面补充,包括上一条命令添加安装的位置
安装步骤
使用命令
yum install -y keepalived安装keepalived需要在线监测的所有机器都要安装keepalived
如果安装提示缺少
需要:libmysqlclient.so.18()(64bit),依次使用命令wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm和rpm -ivh mysql-community-libs-compat-5.7.25-1.el7.x86_64.rpm安装对应的依赖【是否需要注意mysql的版本和本机匹配,我这里匹配了没有问题】,然后再次执行yum install -y keepalived安装keepalived即可keepalived的配置文件在目录
/etc/keepalived/keepalived.conf,使用命令vim /etc/keepalived/keepalived.conf修改keepalived的配置文件用来做nginx服务器在线监测的keepalived配置
【默认的keepalived配置文件】
xxxxxxxxxx! Configuration File for keepalivedglobal_defs {#这一段是机器宕机以后发送email通知,作用不大notification_email {acassen@firewall.locfailover@firewall.locsysadmin@firewall.loc}notification_email_from Alexandre.Cassen@firewall.locsmtp_server 192.168.200.1smtp_connect_timeout 30#global_defs中只有router_id有点用,其他的都可以删掉router_id LVS_DEVELvrrp_skip_check_adv_addrvrrp_strictvrrp_garp_interval 0vrrp_gna_interval 0}vrrp_instance VI_1 {state MASTERinterface eth0virtual_router_id 51priority 100advert_int 1authentication {auth_type PASSauth_pass 1111}virtual_ipaddress {192.168.200.16192.168.200.17192.168.200.18}}#仅仅用来检查nginx服务器的存活状态不用关心从这里往下的所有配置,即virtual_server都可以删掉virtual_server 192.168.200.100 443 {delay_loop 6lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPreal_server 192.168.201.100 443 {weight 1SSL_GET {url {path /digest ff20ad2481f97b1754ef3e12ecd3a9cc}url {path /mrtg/digest 9b3a0c85a887a256d6939da88aabd8cd}connect_timeout 3nb_get_retry 3delay_before_retry 3}}}virtual_server 10.10.10.2 1358 {delay_loop 6lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPsorry_server 192.168.200.200 1358real_server 192.168.200.2 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3nb_get_retry 3delay_before_retry 3}}real_server 192.168.200.3 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334c}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334c}connect_timeout 3nb_get_retry 3delay_before_retry 3}}}virtual_server 10.10.10.3 1358 {delay_loop 3lb_algo rrlb_kind NATpersistence_timeout 50protocol TCPreal_server 192.168.200.4 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3nb_get_retry 3delay_before_retry 3}}real_server 192.168.200.5 1358 {weight 1HTTP_GET {url {path /testurl/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl2/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}url {path /testurl3/test.jspdigest 640205b7b0fc66c1ea91c463fac6334d}connect_timeout 3nb_get_retry 3delay_before_retry 3}}}
【做nginx代理服务器的keepalived配置文件】
xxxxxxxxxx ! Configuration File for keepalived global_defs { #global_defs中只有router_id有点用,其他的都可以删掉,这个是当前机器的自定义名字,随便起名的,当前机器的ip是131 router_id nginx131 } #vrrp是keepalived在内网中通讯的协议【vrrp虚拟路由冗余协议】,atlisheng是实例名称,也是自定义的 vrrp_instance atlisheng { #state是当前机器的状态,当前机器是master state MASTER #interface需要和本机的网卡的名称对应上,这里修改ip地址为ens32,需要和interface对应 interface ens32 #这个不用管 virtual_router_id 51 #主备竞选的优先级,谁的优先级越高,谁就是master;Keepalived 就是使用抢占式机制进行选举,一旦有优先级高的加入,立即成为 Master priority 100 #检测间隔时间 advert_int 1 #内网中一组keepalive的凭证,因为内网中可能不止一组设备跑着keepalived,需要认证信息证明多个keepalived属于一组,同一组的authentication要保持一致,这样能决定一组keepalived中的一台机器宕机,虚拟IP是否只在本组内进行漂移,而不会漂移到其他组上 authentication { auth_type PASS auth_pass 1111 } #虚拟IP,虚拟IP可以填写好几个,意义不大,一般虚拟一个IP即可,这里设置成192.168.200.200,用户访问的是虚拟的ip,不再是真实的ip地址 virtual_ipaddress { 192.168.200.200 #192.168.200.17 #192.168.200.18 } }【备用机的keepalived配置】
注意同一组的实例名、virtual_router_id、authentication得是一样的
注意备机的priority 要设置的比主机小,state需要改成BACKUP
且备用机使用命令
ip addr不会看到虚拟ip的信息
xxxxxxxxxx ! Configuration File for keepalived global_defs { router_id nginx132 } vrrp_instance atlisheng { state BACKUP interface ens32 virtual_router_id 51 priority 50 advert_int 1 authentication { auth_type PASS auth_pass 1111 } virtual_ipaddress { 192.168.200.200 } }使用命令
systemctl start keepalived运行keepalived
安装成功测试
启动keepalived后使用命令
ip addr查询ip信息在ens32下在原来真实的ip下会多出来一个inet虚拟ip:
192.168.200.200,master即主机上才有,备机上是没有的,即虚拟IP漂移到哪一台机器上才会出现这个虚拟IP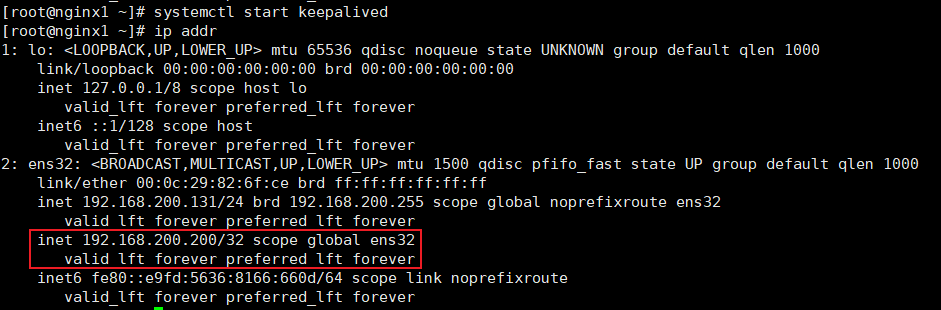
在windows命令窗口使用命令
ping 192.168.200.200 -t在windows系统ping一下这个虚拟IP,观察该ip是否能ping通没有-t只会ping4次,像下图这种情况
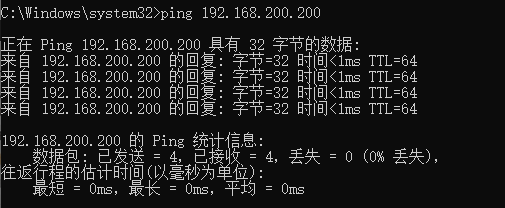
在linux系统下使用命令
init 0关掉master机器模拟nginx服务器宕机,在windows命令窗口观察网络通信情况windows通信切换时丢包一次,然后再次ping通,在备用机132上使用命令
ip addr能够观察到虚拟ip漂移到132机器上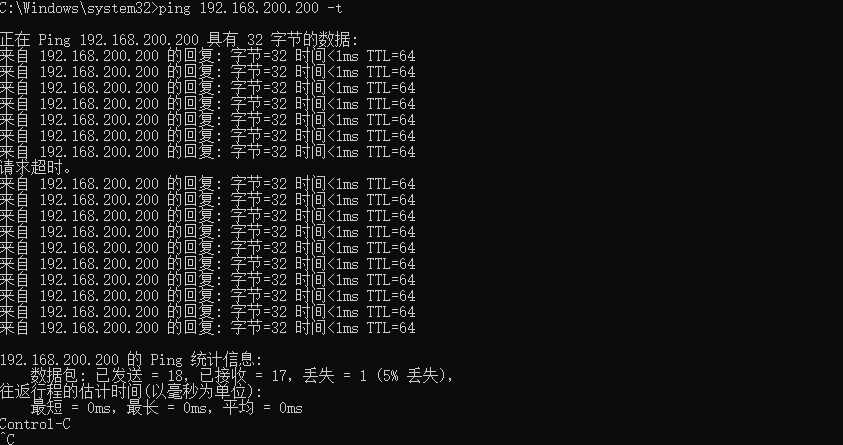
网络协议
客户端与服务器网络通信是通过客户端最底层的socket,即基于网卡的特别基础的网络接口,有一门课叫socket编程,学习socket编程会涉及TCP的编程和UDB的编程,这两种网络协议就已经是较为上层的网络协议了,socket是比操作系统更底层的协议,和物理硬件完成交互,通过操作系统内核和网卡驱动去传输数据,TCP/IP协议是中间层的网络协议,用TCP/IP协议传输的网络数据,对方服务器时不知道数据包传输何时结束的,基本的TCP/IP协议只是用来传递数据的;通常在TCP协议上加一层形成应用层的高级协议,越高级的协议在使用的时候比较简单,但是底层比较复杂;HTTP请求头中包含请求参数,请求体中是真实想要传递的透明数据【比如图片】
HTTP的安全性缺陷
因为Http协议的底层协议没有一个是保证数据传输是安全不会被劫持的,
防火墙不能防止数据传输被劫持,防火墙只能防止本机的端口莫名其妙的向外传递数据,防一些病毒和未知的程序,服务器的防火墙一般只会开启固定的对外通信端口,还可以根据用户的行为设定一些限制访问规则,比如频繁访问等功能,但是没有针对数据网络传递过程中的数据安全性
家里的网络传递经过自家的网关会经过小区的网关,然后到接到会有一个网关,然后区里还有一个大的,市里还有一个大的路由网关,才会接入到主干网络,如果访问的服务器在美国,期间经过的网关路由可能会多达十几二三十个,每个节点都要将数据包传递到下一个节点,最终传递到服务器;在每个网关节点内都是可以看到传递的网络数据的,如果能猜出来传输数据是按照什么协议编码的可以直接按照协议去数据包解码,看到传递的明文内容,所以http协议在数据传输的过程中是不安全的,而且有很多的节点都能监听到【比如公共场合的WiFi不要去传递很私密的东西,可能数据包会被截取做处理】
网络数据传输加密的解决方案
最简单的加密算法是凯撒加密算法
凯撒加密算法就是将明文向后挪动一位【123明文变成231密文】
用户数据经过凯撒加密算法从明文变成密文经过网络传输到服务器,服务器通过凯撒加密算法将数据解密以后处理将响应数据加密成密文再传递给客户端
客户端和服务器采用同一种算法来对数据明文加密解密的过程称为对称加密,优点是简单,缺点是对称加密算法一定要内置在服务器端,如果一个项目是开源的,就能获取到加密算法列表,并在中间节点使用这些加密算法去破解这些密文;并且客户端也需要这些加密算法来对用户的数据来进行加密,
即对称加密算法的保密性无法保证,又因为服务器和客户端都要内置加密算法导致对称加密算法不够灵活
在对称加密的基础上
如果客户端在首次向服务端传递数据时传递一个加密密码,即服务器需要使用该密码作为加密协议的因子才能解开密文,关键是用户的密码如何安全传递给服务器不被中间节点拦截住
所以对称加密算法实际上是无法解决安全问题的,即便使用密码进行解密,但是密码的传递还是不安全的
HTTPS原理
非对称加密算法基本原理
服务器生成一个加密因子,该加密因子不在互联网上进行传播;非对称加密算法加密和解密是不同的算法,客户端存在一个公钥,服务器存在一个私钥,用户首次请求去服务器主机的443端口而非80端口获取公钥,通过公钥和加密算法在数据传输前对明文进行加密生成密文,服务器接收到密文后用私钥和解密算法解开密文得到明文;响应请求以后用私钥和加密算法对响应进行加密【公钥私钥都是加密算法的因子】,密文传递给客户端以后可以用公钥和算法进行解密【请求是公钥加密,私钥解密;响应是私钥加密,公钥解密】
只是以上两点还无法满足安全性,此外还有第三点特征,公钥加密,公钥无法解开密文【因为公钥还是会经过各个节点,存在窃取的风险】
对称加密算法要安全一定要保证私钥要安全,这套非对称加密算法就是https协议的底层算法
存在问题
响应内容也存在被解密的风险
除此以外,这种非对称加密算法也不是绝对安全的,有些节点会存在模拟服务器的行为,拦截用户的请求,替用户去请求目标服务器的443端口获取真实服务器想要颁发给用户的公钥,然后自己给用户颁发自己的公钥,此后拦截用户的请求解密用户密文篡改用户请求信息并替代用户用服务器颁发的公钥进行加密向真实服务器发起请求
进一步优化
这种模拟目标服务器拦截用户请求篡改用户请求信息代替用户请求的行为类似于将银行颁发的银行卡存在自己手上,而向用户颁发自己发行的银行卡
此时需要一个第三方,该第三方不在网络中进行信息传递,同时当目标服务器颁发凭证时知晓和确认凭证且在用户使用凭证时对凭证进行确认,这个机构就叫CA机构,对服务器下发的公钥进行认证,CA机构也是一套系统,提供认证服务
服务器下发公钥之前会向CA机构提交公钥,CA机构会对公钥的提交者的身份进行验证,验证方式一般是给提交公钥的服务器提供一个即时生成的随机验证码文件,要求服务器将该文件上传放在目标域名服务器的指定目录下,CA机构通过指定目录访问该验证文件从而判定是可信任受客户管理的服务器地址【正常情况下拦截者是无法向提交公钥的服务器上传文件的】
当CA机构对提交公钥的服务器验证后,CA机构会使用CA机构的私钥和加密算法对服务器提交的公钥再进行一次非对称加密并生成CA证书【浏览器的地址栏最前面的菜单中有链接是安全的,点开就能查到对应的安全证书,网站单位和颁发机构、时效等等】
再有用户请求443端口想要公钥直接下发CA证书,不再下发公钥了
操作系统中内置了CA机构的公钥,使用CA机构的公钥能解开CA机构私钥加密的CA证书,CA证书也只能通过操作系统内置的CA公钥去解密,中间节点能拦截到CA证书,也能通过CA机构的公钥解密证书,但是无法篡改并生成新的CA证书,因为CA机构的私钥不可能丢,只要不是用这个私钥加密的CA证书,使用CA机构公钥就无法解密,无法被正常解密的CA证书就不认可为可信任的CA证书【非私钥加密,即使是公钥加密公钥也无法解开】
这也是为什么要用正版操作系统,由其是证书方面,避免在系统上被恶意软件安装了root根证书,导致外来root根证书成了可信任的状态,一般杀毒软件也会防范这种根证书的植入,任何操作系统都有内置的CA公钥,包括移动端
同时还要使用正版的浏览器,一系列的认证流程都是浏览器完成的,如果浏览器有问题,即便证书再安全,安全性也无法保证
所有内嵌在操作系统的证书可以通过
win+r呼出的窗口输入certmgr.msc显示的界面进行查看,第三方根证书颁发机构都是非常知名的机构,这些证书就是CA机构的公钥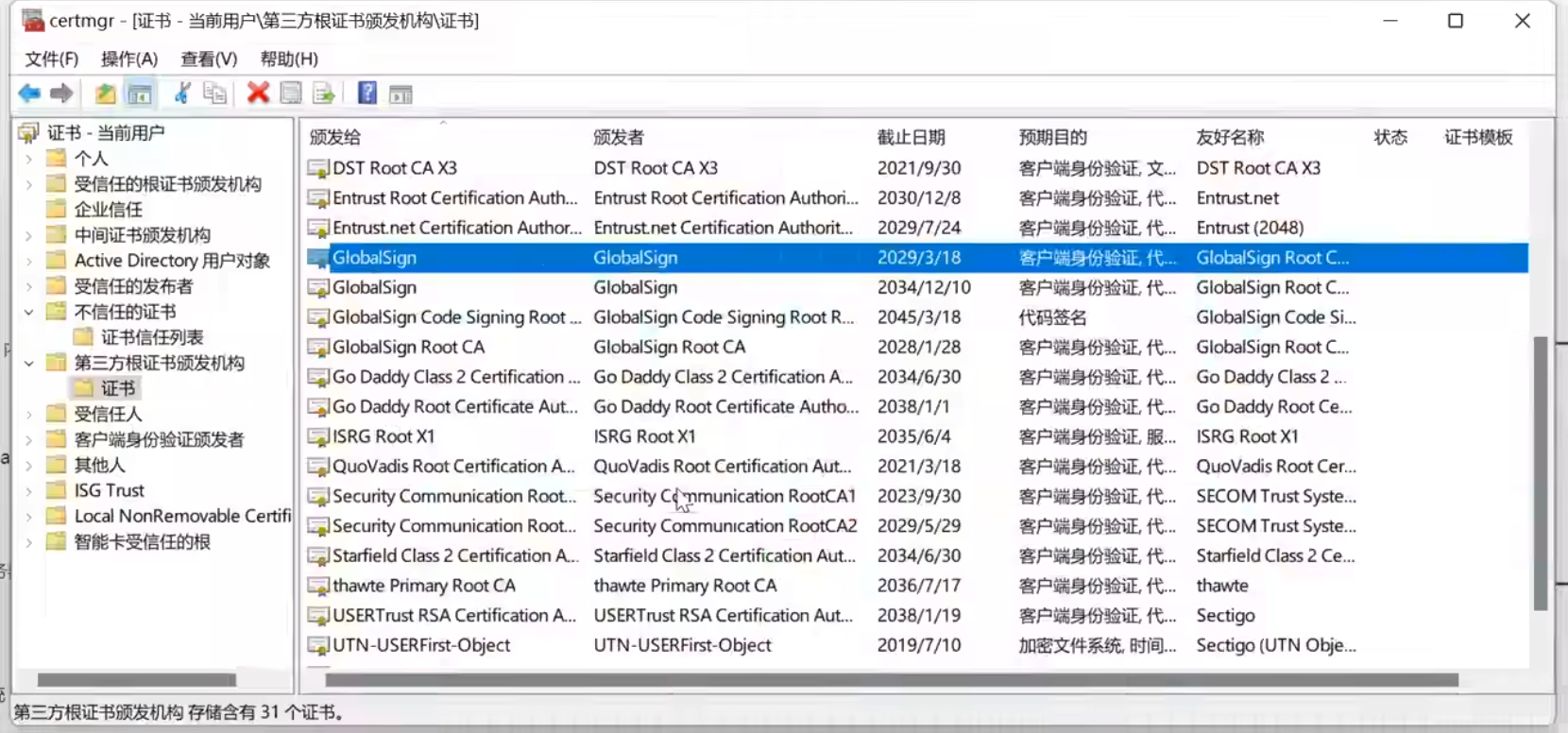
https被称为21世纪互联网最伟大的发明,在以前网络数据传输的安全性非常不可信任,数据非常容易被篡改,https发明以后数据安全性就好了很多,像银行这种对数据加密性要求很高的机构除了引入数据传输安全加密,还会引入其他的加密方案,包括加密键盘控件,避免输入账户密码的时候被恶意软件监听键盘输入;当然这种情况下还是可能被录屏导致不安全
证书自签名
证书自签名意思就是CA机构的角色是服务器自己扮演的,这种应用场景非常少,因为这种情况下,用户访问时浏览器不会有受信任证书的提示,浏览器也不会认为这是一个安全可靠的连接,因为CA机构不是系统内置的,而是用户自己签的CA证书,使用场景非常少,只有内网环境下才会用到自签名,CS的连接也可能用到自签名,但是用处也不大
自签名可以用OpenSSL实现
OpenSSL是一款非常出名的开源软件,相当于在开源界扛把子的地位,罗永浩在2015年左右拿出200w直接赞助给OpenSSL,对互联网安全贡献非常大,还赞助过OpenResty,OpenResty是提供给nginx做高并发的,OpenSSL是提供nginx上https的,OpenSSL基本上内嵌在操作系统上,没有可以使用yum源进行安装,基于命令行的工具,可以生成CA证书
XCA是基于OpenSSL的一款图形化工具,下载地址:https://www.hohnstaedt.de/xca/index.php/download
在线申请CA证书
中小企业可能会负责这件事,在线申请一个证书,绑定到一台服务器上,给服务器安装上nginx,对nginx进行配置,让nginx跑一些开源的程序
购买域名
域名的提供商非常多,最著名的就是万网,net.cn;注册域名到大的平台商,小商户可能带着域名跑路
注意顶级域名中含有中文的域名最好不要买,健壮性不行,稍微老一点的软件都不支持中文的编码,虽然目前流行的浏览器都支持中文
直接阿里云购买
购买主机
主机云服务器就是阿里云ECS,大陆的云服务器需要备案,香港和国外的云服务器不需要备案,CentOS7.4用的比较多,系统也比较靠谱
轻量级服务器有专门的产品界面,不在ESC中
使用xshell连接公网IP能连接上系统,需要输入设置的root账户和密码
在云服务器上安装nginx,该nginx版本除了基础的tengine和OpenResty,还集成了运行环境,包括PHP、数据库等等
使用命令
lnmp,l表示nginx、n表示nginx、m表示mysql、p表示php【安装php是为了演示bbs】oneinstack.com是一个集成环境,可以选择安装的产品并生成安装命令【云服务器安装nginx配置】
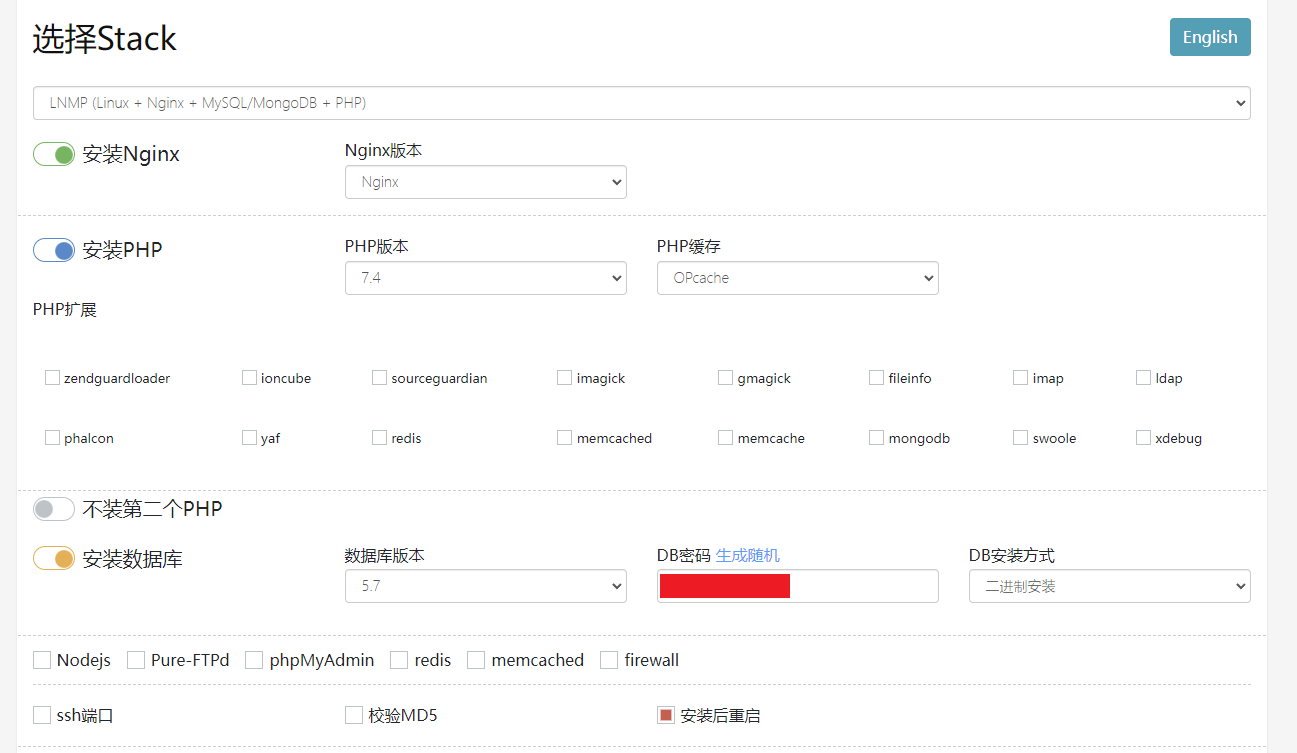
【生成的安装命令】
阿里云的云服务器默认是安装了wget的
我这儿安装好了没有位置提示,这里记老师的,nginx安装目录
/usr/local/nginx、数据库的安装目录/usr/local/mysql、数据库的data dir:/data/mysql、PHP的安装目录/usr/local/php、Opcache控制面板URL:http://172.18.45.195/ocp.php我这儿安装非常快,一分钟可能都没到,老师上课装了27分钟
wget -c http://mirrors.oneinstack.com/oneinstack-full.tar.gz && tar xzf oneinstack-full.tar.gz && ./oneinstack/install.sh --nginx_option 1 --php_option 9 --phpcache_option 1 --db_option 2 --dbinstallmethod 1 --dbrootpwd 个人数据库密码 --reboot配置云服务器的安全组【防火墙】
80、443、22端口,mysql数据库最好不要开放远程通讯端口,线上mysql管理最好安装一个PHPMyAdmin,redis开放6379端口一定要设置密码,很容易被黑
开放对应端口后浏览器访问对应公网ip,对应的大陆服务器没有备案会显示内容禁止访问,没有设置CA认证,地址前面也会提示不安全,使用oneinstack安装的nginx访问80端口会显示oneinstack的控制面板,控制面板中的Virtual host中的./vhost.sh是其提供的修改nginx.conf的脚本文件,oneinstack修改了nginx的配置,在最小配置的基础上还增加了其他配置,暂时先不管;此外还将欢迎页的根目录设置成了oneinstack的控制台,对应的root目录被改成了
/data/wwwroot/default,暂时还是用html,将server 80端口的服务的root改成html,其他的配置先不管,里面还配置了对php脚本的访问
【oneinstack修改的nginx配置文件】
这里和老师的情况不同,我这里默认的nginx配置被注释掉了,老师的是生效的,等服务器备案下来了再说
xxxxxxxxxxuser www www;worker_processes auto;error_log /data/wwwlogs/error_nginx.log crit;pid /var/run/nginx.pid;worker_rlimit_nofile 51200;events {use epoll;worker_connections 51200;multi_accept on;}http {include mime.types;default_type application/octet-stream;server_names_hash_bucket_size 128;client_header_buffer_size 32k;large_client_header_buffers 4 32k;client_max_body_size 1024m;client_body_buffer_size 10m;sendfile on;tcp_nopush on;keepalive_timeout 120;server_tokens off;tcp_nodelay on;fastcgi_connect_timeout 300;fastcgi_send_timeout 300;fastcgi_read_timeout 300;fastcgi_buffer_size 64k;fastcgi_buffers 4 64k;fastcgi_busy_buffers_size 128k;fastcgi_temp_file_write_size 128k;fastcgi_intercept_errors on;#Gzip Compressiongzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 256;gzip_proxied any;gzip_vary on;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";##Brotli Compression#brotli on;#brotli_comp_level 6;#brotli_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/svg+xml;##If you have a lot of static files to serve through Nginx then caching of the files' metadata (not the actual files' contents) can save some latency.#open_file_cache max=1000 inactive=20s;#open_file_cache_valid 30s;#open_file_cache_min_uses 2;#open_file_cache_errors on;log_format json escape=json '{"@timestamp":"$time_iso8601",''"server_addr":"$server_addr",''"remote_addr":"$remote_addr",''"scheme":"$scheme",''"request_method":"$request_method",''"request_uri": "$request_uri",''"request_length": "$request_length",''"uri": "$uri", ''"request_time":$request_time,''"body_bytes_sent":$body_bytes_sent,''"bytes_sent":$bytes_sent,''"status":"$status",''"upstream_time":"$upstream_response_time",''"upstream_host":"$upstream_addr",''"upstream_status":"$upstream_status",''"host":"$host",''"http_referer":"$http_referer",''"http_user_agent":"$http_user_agent"''}';######################## default ############################# server {# listen 80;# server_name _;# access_log /data/wwwlogs/access_nginx.log combined;# root html;# index index.html index.htm index.php;# #error_page 404 /404.html;# #error_page 502 /502.html;# location /nginx_status {# stub_status on;# access_log off;# allow 127.0.0.1;# deny all;# }# location ~ [^/]\.php(/|$) {# #fastcgi_pass remote_php_ip:9000;# fastcgi_pass unix:/dev/shm/php-cgi.sock;# fastcgi_index index.php;# include fastcgi.conf;# }# location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|flv|mp4|ico)$ {# expires 30d;# access_log off;# }# location ~ .*\.(js|css)?$ {# expires 7d;# access_log off;# }# location ~ ^/(\.user.ini|\.ht|\.git|\.svn|\.project|LICENSE|README.md) {# deny all;# }# location /.well-known {# allow all;# }# }########################## vhost #############################include vhost/*.conf;}oneinstack默认将nginx配置成了服务,可以直接使用
systemctl的相关命令【服务器备案中,后面补效果】目前图用的课堂的
在线生成证书
在云服务商搜索SSL证书【应用安全】
整DV单域名证书是免费的,但是限制主体域名【只能设置单个二级域名,一年可以设置20个】,类似通配符等自定义域名需要付费购买,还挺贵,一年几百上千,企业小或者单人没必要买付费的
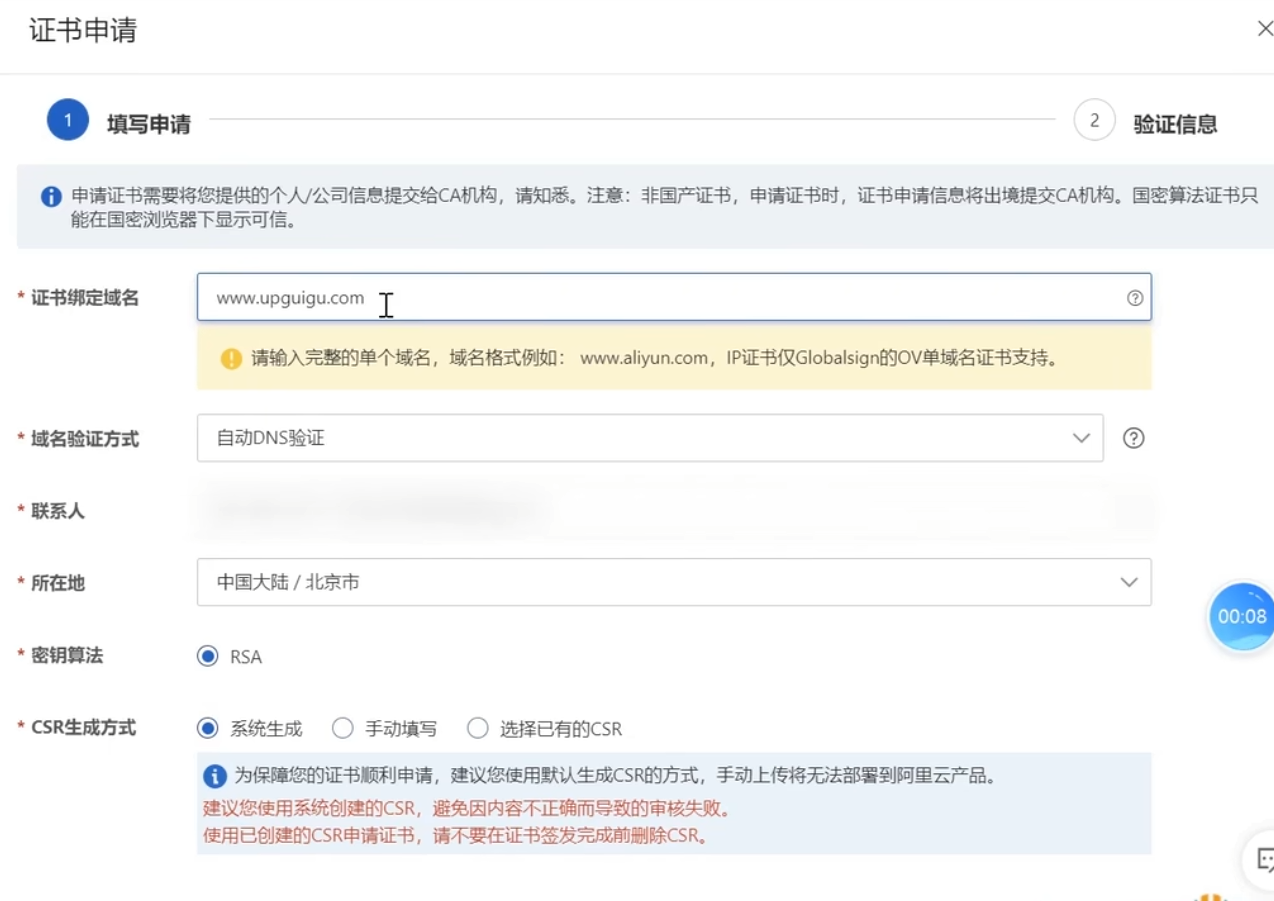
【申请填写信息】
域名验证方式选择自动DNS验证,后续验证的时候点击一下验证就会自动验证,如果是手动需要去配置指定的域名解析供认证机构去进行验证,一般只有域名和服务器在同一个平台才可以自动DNS验证,以文件的形式验证还需要点击上传文件
密钥算法RSA就是非对称的加密算法,CSR是证书文件【直接系统生成即可】
成功提交以后会显示申请审核中,审核成功后会显示已签发,签发速度极快,几秒钟就能签发
证书下载
将证书下载下来传到服务器上,nginx的下载下来是一个zip压缩包
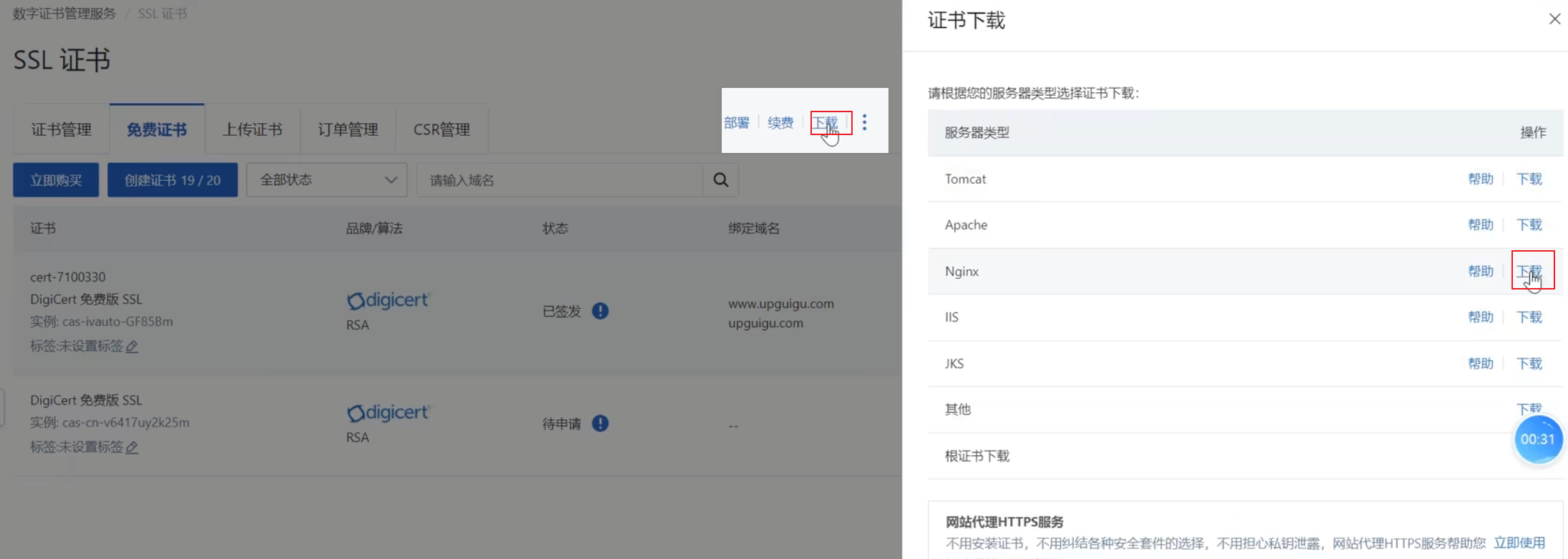
【证书文件】
一共有两个文件,以
.key结尾的文件是私钥,以.pem结尾的文件是证书,两个文件都要传到服务器上nginx的conf目录下,默认会从conf目录下找这两个文件证书安装
直接复制粘贴到nginx.conf的server80服务器的同级,端口是443,ssl_certificate是证书的位置,使用相对路径【注意文件要在conf目录下】
xxxxxxxxxxserver{#所有的请求都会去443端口获取公钥listen 433 ssl;#这个名字localhost是因为没有其他域名写的server_name www.concurrency.cn;ssl_certificate CA认证文件的pem文件带后缀名称;ssl_certificate_key CA认证文件的key文件带后缀名称;}【证书安装】
重新加载nginx没报错就表示安装成功,此时输入
https://域名就会显示安全,http开头还是会显示不安全;这种配置如果二级域名不是www就会显示不安全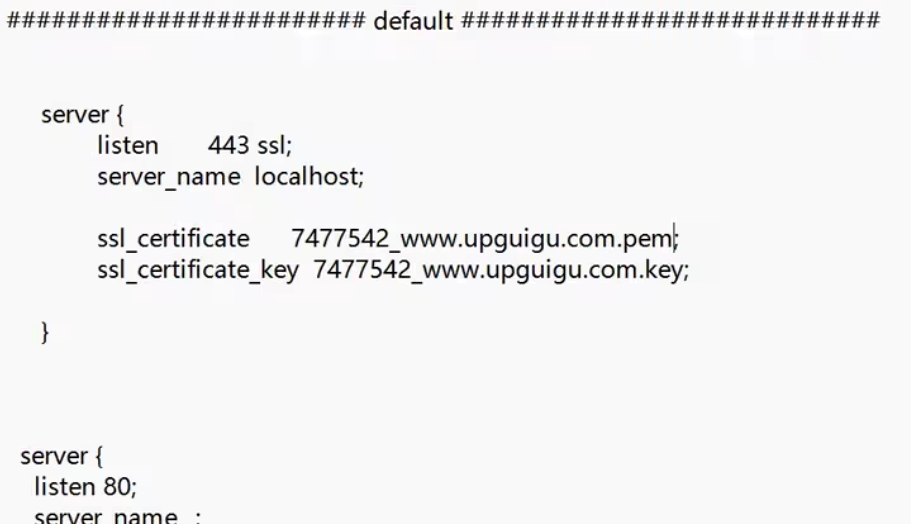
安装开源社区BBS
BBS就是Discuz,非常出名,国内的开源社区鼻祖,现在已经被腾讯收购,网站
https://discuz.dismall.com/【原网址已经被改了】很多的大型互联网网站bbs系统用的都是discuz,可以基于discuz进行二次改造,和现有系统进行集成,直接在官网下载安装:Discuz! X3.5 正式版【2023-10-01】 - Discuz! X 程序发布 - Powered by Discuz! (dismall.com)
discuz是PHP做的,但是可以和系统进行整合,整合之后系统相当于进行了一次升级,成为了异构系统【使用了不同的语言,不同的社群解决方案组成了一个大的系统】,还有其他很多有名的大型开源项目
【上传discuz的zip文件到nginx的html目录】
上传Discuz_X3.4_SC_UTF8_20220131到nginx的html目录,类似这样的开源项目还有WordPress【国内外都非常出名】
使用命令
unzip Discuz_X3.4_SC_UTF8_20220131.zip解压该安装包【解压后的文件】
bbs的安装不是在命令行安装的,是在线安装的,通过访问本机服务器地址来在本机的网站上进行安装
源码目录是upload目录,使用命令
mv upload/ bbs将upload目录改名为bbs
注意此时通过https访问安装目录
https://concurrency.cn/bbs/install/会失败,因为https默认会先访问443端口,但是443端口在nginx.conf文件中没有对该站点进行php环境的配置,所以直接访问该网址会失败;但是http的80站点,不访问443端口的URL:http://concurrency.cn/bbs/install/是可以使用的此时配置所有的请求都走https协议,将http协议下的PHP的所有配置移到443端口下
注意,似乎不是https会首次访问443端口,而是只会访问443端口,包括后续的请求;http才会始终访问80端口
【nginx.conf中80端口下php的相关配置】
xxxxxxxxxxuser www www;worker_processes auto;error_log /data/wwwlogs/error_nginx.log crit;pid /var/run/nginx.pid;worker_rlimit_nofile 51200;events {use epoll;worker_connections 51200;multi_accept on;}http {include mime.types;default_type application/octet-stream;server_names_hash_bucket_size 128;client_header_buffer_size 32k;large_client_header_buffers 4 32k;client_max_body_size 1024m;client_body_buffer_size 10m;sendfile on;tcp_nopush on;keepalive_timeout 120;server_tokens off;tcp_nodelay on;fastcgi_connect_timeout 300;fastcgi_send_timeout 300;fastcgi_read_timeout 300;fastcgi_buffer_size 64k;fastcgi_buffers 4 64k;fastcgi_busy_buffers_size 128k;fastcgi_temp_file_write_size 128k;fastcgi_intercept_errors on;#Gzip Compressiongzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 256;gzip_proxied any;gzip_vary on;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";##Brotli Compression#brotli on;#brotli_comp_level 6;#brotli_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/svg+xml;##If you have a lot of static files to serve through Nginx then caching of the files' metadata (not the actual files' contents) can save some latency.#open_file_cache max=1000 inactive=20s;#open_file_cache_valid 30s;#open_file_cache_min_uses 2;#open_file_cache_errors on;log_format json escape=json '{"@timestamp":"$time_iso8601",''"server_addr":"$server_addr",''"remote_addr":"$remote_addr",''"scheme":"$scheme",''"request_method":"$request_method",''"request_uri": "$request_uri",''"request_length": "$request_length",''"uri": "$uri", ''"request_time":$request_time,''"body_bytes_sent":$body_bytes_sent,''"bytes_sent":$bytes_sent,''"status":"$status",''"upstream_time":"$upstream_response_time",''"upstream_host":"$upstream_addr",''"upstream_status":"$upstream_status",''"host":"$host",''"http_referer":"$http_referer",''"http_user_agent":"$http_user_agent"''}';######################## default ############################server{#所有的请求都会去443端口获取公钥listen 433 ssl;#这个名字localhost是因为没有其他域名写的server_name localhost;ssl_certificate CA认证文件的pem文件带后缀名称;ssl_certificate_key CA认证文件的key文件带后缀名称;}server {listen 80;server_name _;access_log /data/wwwlogs/access_nginx.log combined;root html;#从此处开始是http协议中包含PHP的配置index index.html index.htm index.php;#error_page 404 /404.html;#error_page 502 /502.html;location /nginx_status {stub_status on;access_log off;allow 127.0.0.1;deny all;}location ~ [^/]\.php(/|$) {#fastcgi_pass remote_php_ip:9000;fastcgi_pass unix:/dev/shm/php-cgi.sock;fastcgi_index index.php;include fastcgi.conf;}location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|flv|mp4|ico)$ {expires 30d;access_log off;}location ~ .*\.(js|css)?$ {expires 7d;access_log off;}location ~ ^/(\.user.ini|\.ht|\.git|\.svn|\.project|LICENSE|README.md) {deny all;}location /.well-known {allow all;}#PHP的配置到此结束}########################## vhost #############################include vhost/*.conf;}【更改后的配置文件】
xxxxxxxxxxuser www www;worker_processes auto;error_log /data/wwwlogs/error_nginx.log crit;pid /var/run/nginx.pid;worker_rlimit_nofile 51200;events {use epoll;worker_connections 51200;multi_accept on;}http {include mime.types;default_type application/octet-stream;server_names_hash_bucket_size 128;client_header_buffer_size 32k;large_client_header_buffers 4 32k;client_max_body_size 1024m;client_body_buffer_size 10m;sendfile on;tcp_nopush on;keepalive_timeout 120;server_tokens off;tcp_nodelay on;fastcgi_connect_timeout 300;fastcgi_send_timeout 300;fastcgi_read_timeout 300;fastcgi_buffer_size 64k;fastcgi_buffers 4 64k;fastcgi_busy_buffers_size 128k;fastcgi_temp_file_write_size 128k;fastcgi_intercept_errors on;#Gzip Compressiongzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 256;gzip_proxied any;gzip_vary on;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";##Brotli Compression#brotli on;#brotli_comp_level 6;#brotli_types text/plain text/css application/json application/x-javascript text/xml application/xml application/xml+rss text/javascript application/javascript image/svg+xml;##If you have a lot of static files to serve through Nginx then caching of the files' metadata (not the actual files' contents) can save some latency.#open_file_cache max=1000 inactive=20s;#open_file_cache_valid 30s;#open_file_cache_min_uses 2;#open_file_cache_errors on;log_format json escape=json '{"@timestamp":"$time_iso8601",''"server_addr":"$server_addr",''"remote_addr":"$remote_addr",''"scheme":"$scheme",''"request_method":"$request_method",''"request_uri": "$request_uri",''"request_length": "$request_length",''"uri": "$uri", ''"request_time":$request_time,''"body_bytes_sent":$body_bytes_sent,''"bytes_sent":$bytes_sent,''"status":"$status",''"upstream_time":"$upstream_response_time",''"upstream_host":"$upstream_addr",''"upstream_status":"$upstream_status",''"host":"$host",''"http_referer":"$http_referer",''"http_user_agent":"$http_user_agent"''}';######################## default ############################server{#所有的请求都会去443端口获取公钥listen 433 ssl;#这个名字localhost是因为没有其他域名写的server_name localhost;ssl_certificate CA认证文件的pem文件带后缀名称;ssl_certificate_key CA认证文件的key文件带后缀名称;#从此处开始是http协议中包含PHP的配置,没有index.php也会去找index.php,优先级从前到后,前面的文件找不到就去找后面的index index.html index.htm index.php;#error_page 404 /404.html;#error_page 502 /502.html;location /nginx_status {stub_status on;access_log off;allow 127.0.0.1;deny all;}location ~ [^/]\.php(/|$) {#fastcgi_pass remote_php_ip:9000;fastcgi_pass unix:/dev/shm/php-cgi.sock;fastcgi_index index.php;include fastcgi.conf;}location ~ .*\.(gif|jpg|jpeg|png|bmp|swf|flv|mp4|ico)$ {expires 30d;access_log off;}location ~ .*\.(js|css)?$ {expires 7d;access_log off;}location ~ ^/(\.user.ini|\.ht|\.git|\.svn|\.project|LICENSE|README.md) {deny all;}location /.well-known {allow all;}#PHP的配置到此结束}server {listen 80;server_name _;access_log /data/wwwlogs/access_nginx.log combined;root html;}########################## vhost #############################include vhost/*.conf;}将http协议的请求转发到443端口
http协议跳转https,一般服务器上都是这样配置的,在80站点下添加如下配置
此时任何http协议请求都会自动跳转到https上
xxxxxxxxxxserver {listen 80;#站点域名server_name www.concurrency.cn concurrency.cn;access_log /data/wwwlogs/access_nginx.log combined;#该配置实现http协议跳转https协议,server_name是当前的域名,即用户访问的是哪个域名就跳到哪儿,也就是当前80站点配置的域名,重定向的协议是https协议,request_uri是用户实际请求的urireturn 301 https://$server_name$request_uri;root html;}安装
在html目录下使用命令
chmod -R 777 bbs/将目录权限设置为可写状态,学习环境为了方便可以直接改成777,生产环境不要这么做,要根据用户需求设定具体的权限【生产环境的权限配置比较复杂,需要根据实际情况来】,更改以后刷新页面可以观察到当前状态全部变成绿色注意不需要创建目录,只需要更改bbs的权限即可
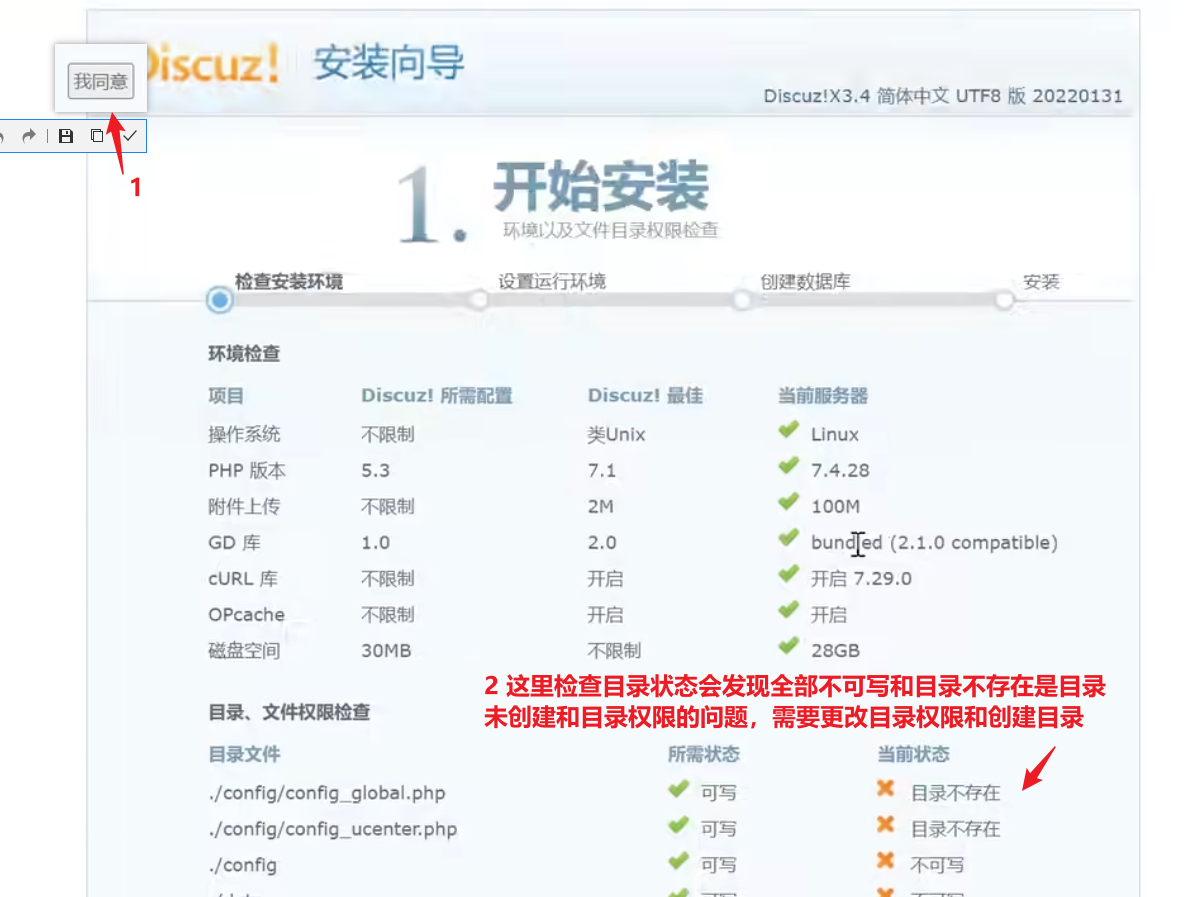
【数据库配置】
数据库会自动帮助用户创建对应自定义名字的数据库,管理员账户和密码需要自己设置,该过程比较慢,耐心等待,成功了会显示论坛已完成安装,此时自己网站上的bbs论坛系统就可以正常使用了,可以测试一下发帖
后台管理在管理中心,需要输入管理员账户和密码进行登录,功能很多
系统扩容
原有的用nginx构建的站点在运行过程中可能会产生一些瓶颈【内容越来越多,访问频次越来越高】,拉低用户的体验,此时需要用扩容来实现让系统支持更高的并发量和吞吐量
扩容方式有:单机垂直扩容、水平扩展、细腻度拆分、数据异构化、服务异步化;这里只重点讲了单机垂直扩容
扩容的原则:无状态原则和弹性原则
实际上从这里开始到多级缓存都在讲扩大系统对并发请求容量的各种手段和扩容衍生出来的一系列问题的解决手段
扩容方式
单机垂直扩容
简单粗暴直接增加硬件资源,类似一个井使用的人多了,水不够用把井打的更深;这种方式存在瓶颈,当一个井不够用了,再怎么深挖都不能解决问题【比如人太多了,只有一口井不停地打水还是不能让每个人都分到水】,这种一次性增加的成本或者资产从老板角度来看可能比招几个资深程序员来优化系统要更省钱
对云服务资源的增加,比如项目部署在云服务器上,可以通过增加云服务器的配置【换更高性能的磁盘、增加CPU的核数、增加内存】
自建机房或者云服务的可以考虑提升硬件质量,比如选用更好的产品来增加系统的并发度【知名品牌的高性能服务器厂商有IBM、浪潮、DELL、HP】
将CPU/主板更新到主流的产品
网卡:很多时候系统的瓶颈不是硬件瓶颈,是网络上的瓶颈,网络瓶颈可以通过购买更高的带宽解决【现在的网卡不局限于百兆、千兆;还有万兆即10G/40G的网卡,带宽特别高的网卡非常稀缺,一般还需要特定的渠道才能买的到】,还可以在主板上增加网口和网卡的个数【一个主板不止能插一个网卡,一个操作系统上也可以有不止一个IP地址】,可以通过串行和并行的方式,串行是流量通过多个网口接入系统后汇集到一块;并行的方式是指配置多个IP地址【貌似也是在主板上插入两块网卡】,服务器的一个网卡可以接入电信的网络,另一个网卡接入联通的网络,两个网卡的IP地址不同;流量的串行和并行都是非常成熟的方案,这也是网络工程师一般去做的事;网卡除了提升带宽来提升网络性能,现在的网卡还会内置芯片,提升网卡对数据包,网络请求在经过网卡时就进行初步处理,减少操作系统的工作
磁盘:磁盘控制系统内部数据的传输熟读,常见的磁盘种类:SAS(SCSI)HDD(机械)、HHD(混合)、SATA SSD、PCI-e SSD、MVMe SSD【MVMe是协议,MVMe SSD的速度和效率是最高的,相比如HDD的各种磁盘在读取和写入的速度上都是指数级别的提升】,在服务器上对磁盘的要求更多的是随机读取的效率,一般nginx部署在服务器上主要提供静态网页的资源,网页在磁盘上的读取一般都是随机的读取【因为无法预测用户究竟想要哪个网页】,随机读取方面还是SSD的速度比HDD的速度要高得多的多,但是HDD磁盘也是非常常见的,因为这种磁盘的可靠性会比较高7200转,服务器用的HDD一般是一万转或者一万五千转,转速越快磁头到磁盘的寻址速度就越快,转速快可能会导致故障率变高,HDD磁盘的故障一般都发生寻址过程中,磁盘栈的越快,磨损的几率就越高,一旦磁盘上盘片磨损,就会产生坏道,就可能导致磁盘中数据的丢失,HDD磁盘在服务器上还是比较主流,就是可靠性比较高,但是磁盘速度越快,出现坏道的概率就越大,而且一般转速高容量大的磁盘会比较贵
SSD速度快,故障率高,过热、读取写入频次过高,使用时间太长都会导致故障,故障可能会导致全盘数据丢失,一般将SSD作为系统主盘【系统盘】,并在SSD上存储热点数据,将数据库mysql等安装在SSD上;由于SSD容易发生故障的原因,一般都采用多副本机制,将SSD上的数据采用多副本的方式进行冗余存储【也有备份的比较成熟的方案raid5,多副本机制的实现有同时写入,单一读取;也有同时写入,同时读取的方式】,一般的公司都会在内网中对线上服务器中的数据再做一次备份
HDD比较适合冷数据的存储,也适合大文件的存储,因为单位容量成本低【用来存储电影数据等】
水平扩容
【集群化系统架构】
keepalived负责nginx服务器的高可用,后端服务器提供数据的统一称为上游服务器,流量接入层的服务器统一称为中游服务器,集群中的每台上游服务器中运行的代码都是一样的,分布式系统和单一的集群系统的区别是分布式系统中系统功能被拆分到多个服务器中,这些特定的服务器负责特定的服务,分布式系统中不一定有集群;单一的集群系统是每个服务器都是一个完整的系统,集群内的每台服务器都是一样的,集群是分布式系统的子集
nginx可以通过proxy_pass和UpStream关键字将用户请求中转到上游的集群服务器
在原来的单机系统垂直扩容基础上提供集群化增加更多机器的方式来整体对外提供服务,优点是成本低
集群化比单机扩容还要廉价,投入包含买服务器,研发和运维成本,单机提升达到一定程度的时候再增加单机硬件水平成本会格外的高【比如非常好的内存条可能主板不兼容,还需要更换主板】,更常见的是通过软件的手段提升系统的性能,在系统集群化配置的前提下:可以使用以下方式来分发请求
细粒度拆分
分布式,将已经集群化的系统通过数据分区【将一个nginx上存储的过多的文件,将文件拆分成几块分布在不同的nginx服务器上】、上游服务SOA化【SOA:面向服务做技术架构,主要针对后端的应用服务器,将原本庞大的单体系统拆分成更加细腻度、特定模块提供特定服务的分布式系统架构,这些模块运行在单独的服务器上,SpringCloud和Dubbo都属于SOA的一部分,nginx对这些细腻度的每个模块都单独进行代理】、入口细分【入口有浏览器、移动端原生APP和物联网应用、H5内嵌式应用,配置根据用户的请求入口来访问不同的nginx服务器达到分流的效果】再拆分成分布式的系统
数据异构化
最初是把nginx作为静态资源的主要载体,数据库和tomcat服务器作为对计算数据文件的存储载体;数据异构化是将数据进行拆分分布在不同的对象上【客户端、CDN、nginx服务器、DB、web服务器】;数据异构化中的一种方式就是做多级缓存,将缓存数据拆分分别做客户端缓存、CDN缓存、异地多活【把数据和缓存放在多个物理的空间如不同地区的机房去存储】、Nginx缓存后端服务器数据【nginx既可以做动静分离,还可以做动态数据的缓存】
服务的异步化
同步:用户从发起请求,请求数据通过网络传递、服务器处理响应到数据渲染,用户一直在等待的过程称为同步
异步:用户请求到服务器后针对需要长时间处理的请求,如上传下载文件可以先简单的给用户一个响应,让用户可以做其他事情,等真正处理完成后再把结果响应并通知到用户
服务异步化的实现方式:拆分请求【用户下载请求拆分成第一次查询文件大小并选择普通下载还是多线程下载;又比如比较复杂的用户信息填写使用下一步按钮引导的方式让用户完成填写,而不是一股脑的把表单丢给用户】、消息中间件
会话管理
依靠nginx自身的配置对集群化的会话管理在扩容方式的水平扩容中已经进行了介绍,以下介绍利用第三方
水平扩容会话管理
nginx自身对服务器集群会话的管理的配置
非分布式的集群化系统上游服务以Tomcat服务器为例,会保存用户登录的信息即session在服务器中,集群中的其他服务器没有这个session,也就没有相应的会话信息,维持用户会话状态的方案有以下几种
Redis+SpringSession:这是使用上游服务器自身提供的功能来维持会话,SpringSession是一个框架,会把用户的会话状态存储在Redis中,这是通过java来保持用户的会话,但是这种方式由于java的性能相比于nginx偏低,此外还需要额外增加服务器,此外如果上游服务器比较多,此时redis一台服务器很可能不堪重负,整体系统设计的复杂度也会非常高;如果使用nginx解决这个问题,就可以省去很多为了维持会话导致的额外开销
ip_hash:主要是为了在非分布式的集群系统中维持用户会话【其实之前已经讲过】,原生开源版本自带,根据客户端IP地址通过哈希算法得到定值,用哈希值对上游服务器取模将请求定向转发到一台服务器上【一致性哈希】,这里面存在一个问题,类似于网吧、学校、稍微大一些的公司或宽带用户共用一个IP地址,可能导致大量的请求取到一个哈希值,全被转发到一个服务器上,造成流量严重倾斜,这种方式特别不适合运行在局域网中的系统,如企业中的ERP、校园中的教务系统、考试系统【考生集中在几个学校考试,一共就只有几个IP】,但是分发效率很高,能够避免像用Redis+SpringSession的额外开销
除此以外,用户使用过程中如果发生服务器宕机的情况,用户的会话状态也会直接消失
这种ip_hash方式的应用场景一般是中小型项目初期的快速扩容,不想改代码,只需要添加机器就能立即扩大系统的并发度,用nginx来做流量分发原代码根本不需要改;如果使用SpringSession需要改代码,打包测试一系列操作
缺点:一旦服务器出现宕机,服务器中的会话状态就会丢失,尤其在与钱有关的系统中,所有分步操作都没有持久化全部保存在内存或者session中的情况下,请求在机器宕机后被转发到其他机器中,操作还能继续,但是此前的操作全部丢失,用户的体验极差
模拟使用ip_hash负载均衡策略做会话管理的配置
使用3台nginx模拟集群情况下的会话管理情况,一台131做代理服务器,另外两台132和133做上游服务器
【代理服务器的nginx.conf】
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream ip_hash_test{#ip_hash;单独成行,表示使用ip_hash的方式进行负载均衡ip_hash;server 192.168.200.132;server 192.168.200.133;}server {listen 80;server_name localhost;location / {proxy_pass http://ip_hash_test;#root html;#index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【访问效果】
本机的ip被分配到133机器,此后一直都是133机器
将131服务器的
ip_hash;去掉后,再访问192.168.200.131就会采用轮询的策略依次访问两台上游服务器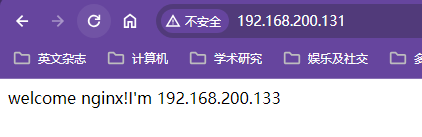
【删掉
ip_hash;后的访问情况】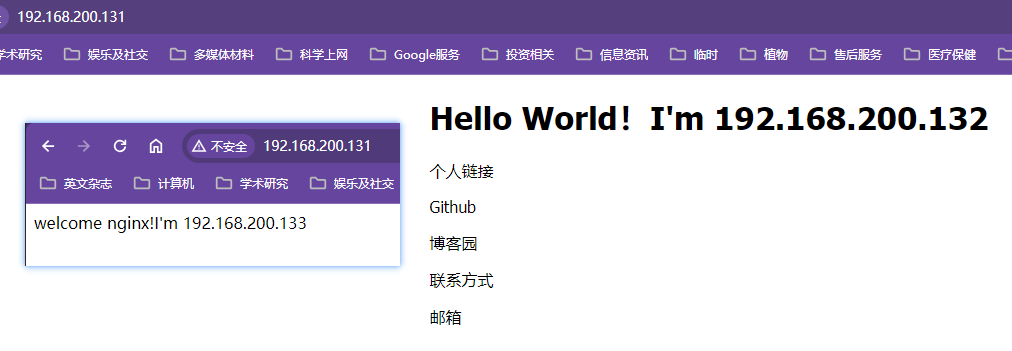
通过$cookie_jsessionid做会话管理
用户首次访问服务器时,服务器会给用户生成session并下发一个存于cookie的jsessionid,用户cookie缓存没有清空期间,对服务器的访问都会携带这个cookie和其中的jsessionid,用来匹配服务器存储的session,匹配上就认为用户已经登录
nginx可以根据客户端请求cookie中的jsessionid取哈希值将jsessionid相同的请求始终转发到同一台服务器
除此以外,nginx除了取cookie中的信息,URI和URL中的信息,还可以取请求头中的其他信息来做用户流量分发
这种方式可以替代ip_hash做局域网中的请求转发,不会发生类似ip只有几个导致大量请求集中在某台服务器的现象,没有细讲,只是说用jsessionid来做流量分发可以替代ip_hash处理这种场景
【RequestHeader中的所有信息】
这里面的参数都可以用来做哈希实现用户流量分发,一般挑选能对用户起区分作用的属性值,uri、ip、jsessionid等

【代理服务器131的nginx.conf】
注意jsessionid是tomcat服务器专门下发的,其他服务器不一定是这个参数,如果cookie中没有jsessionid这个参数这个配置会不起作用
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream request_uri_test{#根据请求头中cookie的jsessionid的哈希值来做负载均衡和会话保持hash $cookie_jsessionid;server 192.168.200.132;server 192.168.200.133;}server {listen 80;server_name localhost;location / {proxy_pass http://request_uri_test;#root html;#index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}通过$request_uri做负载均衡
使用场景:访问相同url会转发到同一个服务器,适合用在没有cookie的场景如手机APP,将jsessionid直接带在url的最后,即使相同的请求也能根据jsessionid的不同将用户分配到特定的服务器来管理会话【如果只是集群系统并不是分布式系统下能这么用吧,而且uri整体计算的哈希值也可能不同啊,为什么能保持会话,这不是和url_hash是一回事吗?】
这个是将系统扩容会话管理的时候讲的,不知道和url_hash有什么关联没
在不支持cookie的情况下【手机上的APP不支持cookie】可以直接把jsessionid直接带在URL的后面,根据用户的jsessionid来对用户进行会话管理【存疑,是对jsessionid做哈希还是对整个uri做哈希,对整个uri做哈希还是可能被派发到其他服务器上,一样无法维持会话,而且还得是单一系统的集群才行啊】
第二种情况就是类似url_hash的情况,当资源有所倾斜的时候,根据uri去确定资源位于哪一台服务器上【比如流媒体服务器,文件太大,不可能分发到所有的流媒体服务器上,也没有必要】,文件上传的时候根据请求的url算出哈希值放上对应的服务器【还是有一些问题,如做集群,其实都能解决,再代理一台给集群做负载均衡,虽然不太优雅,实际方案不了解,有机会学习一下】
【模拟使用$request_uri来做负载均衡】
【131的nginx.conf】
没有项目,没部署tomcat,测试效果用nginx来代理
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream request_uri_test{#根据请求uri的哈希值来做负载均衡和会话保持hash $request_uri;server 192.168.200.132;server 192.168.200.133;}server {listen 80;server_name localhost;location / {proxy_pass http://request_uri_test;#root html;#index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【测试效果】
没带参数的访问133,带参数的访问132,实际都是访问的index.html,相同的uri访问的都是同一台服务器
由此也衍生出问题,如果用户改动参数【比如复选框导致uri不同】,前后两次请求可能会打到不同的服务器上,这个要结合实际情况才行,不能瞎用,只是选择之一,这些都是用来在扩容后想要不改代码直接用nginx做扩容的
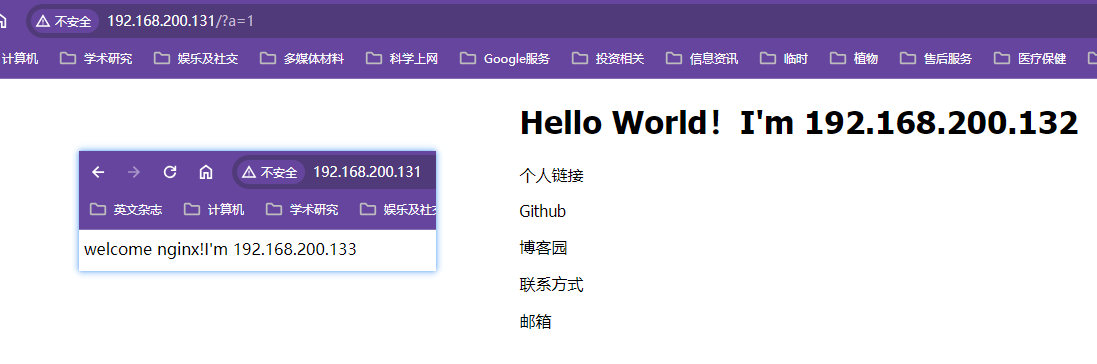
通过lua脚本做更加复杂的定向流量分发
可以看出,ip_hash或者$request_uri都有很多的问题,lua语言可以实现更加复杂的控制,讲OpenResty的时候再讲
这些方式结合起来能够应付90%依靠集群和nginx做负载均衡的方式来最小成本的成倍系统扩容
使用第三方模块对nginx进行升级
目的是使用sticky模块实现对静态服务器的会话保持,sticky是google开源的一个工具,利用cookie来做负载均衡和会话保持的扩展版本,这个功能是原生nginx开源版本不包含的功能,需要手动安装,sticky的功能比原有的
hash $cookie_XXX要多的多得多,原有依靠cookie的jsessionid来做会话保持需要上游服务器下发了jsessionid才能实现会话保持的作用,sticky不需要上游服务器下发任何东西,利用sticky就可以实现nginx服务器集群的负载均衡和会话管理sticky对会话的管理和tomcat的jsessionid理念是一样的,用nginx来生成一个专属的cookie,使得不论在上游服务器是tomcat还是不是tomcat都能通过代理服务器生成的cookie进行会话管理
应用场景:前部一台nginx服务器做路由,上游多台nginx服务器做静态文件存储【视频音乐等】,不希望多次相同客户端的请求和nginx服务器断开连接,因为建立连接是非常大的开销,此时就可以通过sticky来完成客户端与非tomcat服务器的会话状态保持【即sticky适用于不下发cookie来保持会话状态但是又需要保持会话状态的服务器】
使用nginx的时候经常会使用第三方模块,使用第三方模块前需要甄别一下第三方模块是否稳定,用户数量多不多,不稳定不确定的不要用,用的人不多出了问题都搜不到解决办法;此外使用第三方模块还要考虑场景是否需要,不需要就不要引入
准备五台虚拟机做演示:三台nginx【131、132、133】,两台tomcat【134、135】,注意tomcat的欢迎页配置的是test目录下的,即test作为webapp,使用
192.168.200.131:8080/test/进行访问【tomcat可以使用./startup.sh后台启动或者./catalina.sh前台启动】安装sticky
sticky在nginx上的使用说明:http://nginx.org/en/docs/http/ngx_http_upstream_module.html#sticky
tengine版本中已经有sticky这个模块了,安装的时候需要进行编译;其他的版本还是需要单独安装,sticky模块用的比较多
下载地址:BitBucket下载地址,里面也有对sticky使用的介绍、github下载地址,github是第三方作者的,google主要开源在BitBucket上
sticky主要还是使用BitBucket下载,该Sticky由google进行的迁移,而且一般都下载这个,下载点击downloads--Tags选择版本【很多年不更新了,但是功能已经算比较完善了,有不同的压缩格式,linux选择.gz】--点击.gz进行下载【sticky安装在nginx负载均衡器上即131】
将文件
nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d.tar.gz上传至linux系统/opt/nginx目录下使用命令
tar -zxvf nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d.tar.gz将文件解压到当前目录在nginx的解压目录
/opt/nginx/nginx-1.20.2目录下使用命令./configure --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d检查环境并配置将nginx编译安装至/usr/local/nginx目录下nginx重新编译会生成全新的nginx,如果老nginx配置比较多需要全部备份并编译后进行替换
--add-module是添加第三方的模块,如果是nginx自带的模块编译的时候用的是--vs-module命令,表示模块已经在nginx的官方安装包里了
在nginx的解压目录
/opt/nginx目录下使用命令make安装nginx编译过程如果遇到sticky报错,是因为sticky过老的问题,需要修改源码,在sticky的解压文件中找到
ngx_http_sticky_misc.h文件的第十二行添加以下代码添加后需要重新./configure一下再执行make
安装sticky模块需要openSSL依赖,如果没有make的时候也会报错没有openssl/sha.h文件,此时使用命令
yum install -y openssl-devel安装openssl-devel,再使用./configure检查环境并make进行编译安装,没有报错就安装成功了xxxxxxxxxx在nginx解压目录使用命令
make upgrade检查新编译的安装包是否存在问题【在不替换原nginx的情况下尝试跑一下新的nginx】,而不是直接把新的替换掉旧的nginx解压目录中objs是nginx编译后的文件,objs目录下的nginx.sh就是新编译的nginx可执行文件,想要平滑升级nginx不破坏原有配置可以将该nginx.sh文件直接替换掉原安装目录中的nginx.sh,但是一定要注意原文件的备份,
使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old对原nginx可执行文件进行备份,使用命令cp nginx /usr/local/nginx/sbin/将nginx解压包objs目录下的nginx.sh拷贝到目录/usr/local/nginx/sbin/不要直接用命令
make install,会直接把老的nginx全部覆盖掉,生成全新的nginx,之前的配置全都会丢失使用命令
./nginx -V来查看nginx的版本和nginx的编译安装参数使用命令
systemctl start nginx启动nginx,并使用浏览器访问nginx观察访问是否正常,访问正常即nginx升级第三方模块成功注意被代理的上游服务器要提前正常运行,否则访问代理服务器会报错,还需要进一步排错
使用sticky进行会话管理
sticky的作用域和hash各种参数一样在upstream中【代表某个服务器集群】
nginx.conf
没有添加sticky配置的情况下默认是轮询,只添加了sticky效果是nginx给用户下发一个默认名为route的cookie,根据这个cookie来做用户的会话管理和负载均衡,默认没有有效期
sticky对tomcat服务器和nginx服务器的效果都是一样的
sticky常用的配置有:
sticky name=route expires=6h:name为配置sticky下发的cookie属性名为指定属性名route,不配置默认也是route【千万不要将这个cookie的名字设置成和tomcat下发的名字jsessionid一样,会出问题,如果tomcat和nginx都下发jsessionid,nginx和tomcat每次都会因为找不到对应的jsessionid而一直重复更改jsessionid,nginx和tomcat共用一个jsessionid,导致nginx一直新生成jsessionid且对新生成的jsessionid做哈希并做负载均衡,就达不到根据指定cookie做负载均衡的效果了】;
经过观察,jsessionid只在两个值之间变化,应该是除了cookie还有其他的用户匹配确认机制
expires为设置名为route的cookie的有效时间
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;#代理tomcat服务器集群时upstream的名字stickytest不能带下划线,会报400错误;nginx服务器集群可以用下划线upstream stickytest{#使用sticky来做会话管理sticky;server 192.168.200.134:8080;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {proxy_pass http://stickytest;#root html;#index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【配置文件没有配置sticky】
【配置sticky后】
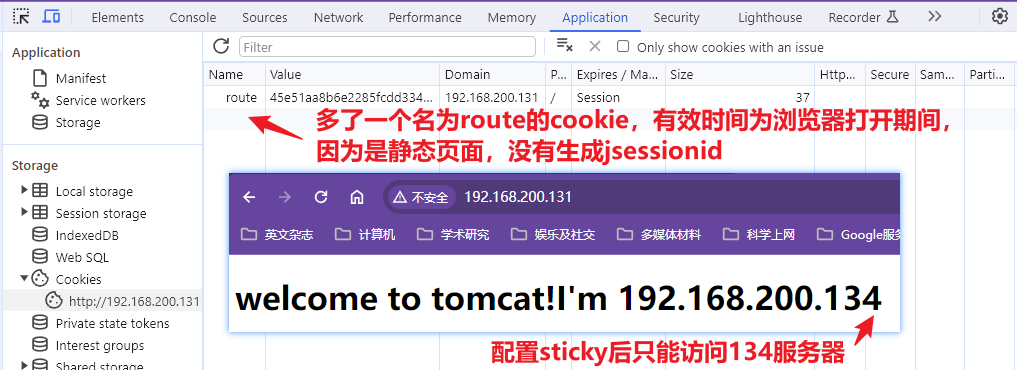
keepalive
keepalive不是keepalived,keepalive能够极大的减少nginx三次握手的开销,keepalive是HTTP提供与服务端保持链接
【百度的keepalive】
浏览器发起请求默认就期望支持keepalive,keepalive是指通过三次握手一次性建立好连接管道,再次发起请求保持之前建立的TCP连接,在浏览器发起请求的时候请求头中的
Connection:keep-alive就已经示意浏览器想要keepalive,响应头中也有Connection:keep-alive是服务器看到请求头中想要用keepalive的方式,服务器自身也支持这种方式,也愿意支持这种方式,就使用keepalive的方式;一般在对服务器主页的访问的请求和响应头中会看到Connection为keepalive,对图片、js文件等请求不带有Connection参数,更多的是缓存相关的参数,表示浏览器没有明显期望使用keepalive的方式图片、js文件请求头和响应头中都不含
Connection:keepalive;看了以下百度翻译的请求中css文件请求头中含有,但是响应头中没有
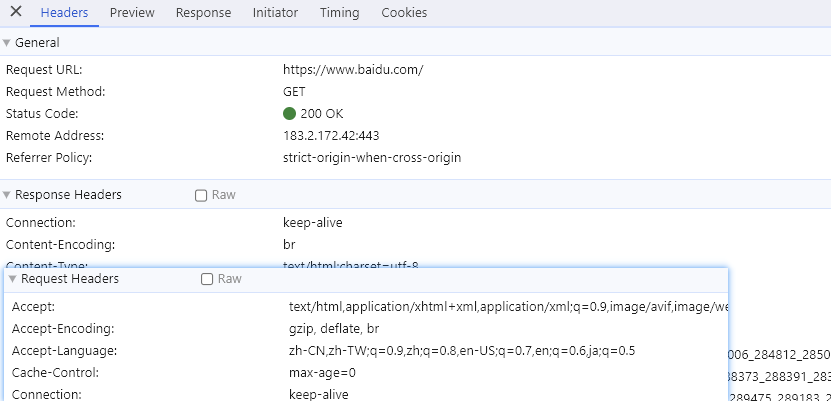
keepalive的使用时机
在一个页面停留的时间不会太长【比如百度的首页】,很快就会发起点击事件再次请求的情况,就可以使用keepalive的方式,复用此前建立的TCP连接;
主请求是一个骨架,内部还有很多对其他资源的引用,这些静态资源短时间一般都不怎么变化,可以走浏览器缓存,速度会更快,对服务器的压力也小
对引用资源的请求一般只请求一次【?这不对吧,多次访问相同的页面也会再次发起请求啊,难道是走缓存吗,这里不能理解,应该理解成静态资源不咋变化,后续对静态资源的请求可以走浏览器缓存】,更多的时候希望把静态资源缓存在浏览器中,因为静态的请求一般不会变化
在nginx中对客户端keepalive做配置
keepalive既可以对浏览器做配置,也可以通过nginx来设置keepalive
nginx配置keepalive的官方文档:https://nginx.org/en/docs/http/ngx_http_upstream_module.html#keepalive_time
nginx中对客户端keepalive的可配置参数详解
server是反向代理服务器内部的一个节点,该节点下对keepalive的配置参数如下:
keepalive_disable:把某些浏览器的长连接功能给禁用掉,并不是直接把keepalive给禁用掉,取值是浏览器的具体型号,默认值是微软的IE6版本【值是asie6】,该版本的浏览器对服务器端的keepalive是有一些问题的,所以直接把IE6的版本禁掉了,一般默认是不动这个参数的;官方文档中keepalive_disable位于ngx_http_core_module,对浏览器的keepalive配置位于该模块;对上游服务器的keepalive配置位于ngx_http_upstream_module模块下
keepalive_requests:建立起可复用的长连接之后,一个连接通道能同时发起多少个并发请求,默认是1000个【这是针对客户端的单个连接的,一般来说,一次请求中发起的并发请求并不是都是打向一个站点的,100个引用资源的并发请求可能打到同一个站点就10来个。1000的限值完全就够用了,不需要像一些nginx调优说的把通道的并发连接限制改大】;一个TCP管道不是单个时刻只能处理一个请求,服务器和客户端的操作系统的网络全部都是异步的,并不是同步阻塞式【单个请求必须处理响应完成后才能发起下一个请求】的,建立起可复用的连接通道以后,可以在连接上并发发起很多请求,以时间回调的机制来区分返回的数据;这个参数经常被调优的文章提起,但是增大了不会起到很明显的作用,因为是针对浏览器单一的可复用连接同时发起的请求个数
send_timeout:两次向客户端写操作间的时间间隔大于设置的时间连接通道会被强制关闭,默认值是60s,可以将keepalive_timeout看成请求的间隔时间,send_timeout看成响应数据的间隔时间;这个send_timeout有时候比较坑,比如后台服务器准备数据时间比较长,需要两分钟,此时用户是同步请求,正在等待数据返回,一旦准备数据的时间超过两次响应数据的时间,连接会被强制关闭,准备的数据就返回不回去了,这个对文件下载没影响,如果在下载文件,连接不会断;注意send_timeout时间设置不能设置的太小,如果系统中有耗时操作超过send_timeout的设定时间会直接强制断开连接,而数据还在准备过程中,中间没有数据传输,数据将永远无法响应给用户,表现为用户请求了,但是响应不了数据,一定不能设置的过小,而且有耗时操作还要将该参数适当调大
keepalive time:限制keepalive的连接最大时长,即一个连接创建时长达到设置的最大连接时长连接会被强制失效【后面解释说不是强制把TCP连接断开,而是让keepalive的保持时间失效】,默认是一小时,避免因为一些专门消耗nginx连接资源的攻击导致对nginx资源的浪费
keepalive_timeout:指的是再次点击和上次点击即任意两次请求间的时长超过65秒才会关闭连接[超过65秒没反应就把链接关掉],即两次客户端活跃的时间间隔高于该设置值就关闭连接【后面也解释会让keepalive失效,但是没说keepalive失效和断开TCP连接是什么关系】,理解成请求间隔时间大于设定值就关闭连接,这个值不能设置的过大[过大消耗资源,因为连接数多],也不能设置的过小[过小建立连接的次数多];keepalive_timeout可以配置一个参数也可以配置两个参数,配置两个参数会多出一个
keep-Alive:timeout=65,这和HTTP协议的版本有关系,HTTP1.0版本需要在请求头添加该参数,1.1版本以后就不需要该配置了;而且1.0和1.1版本的HTTP协议在keepalive的实现上也有差异,经可能使用1.1版本以后得HTTP协议
上述所有配置客户端keepalive的设置都在nginx代理服务器的http模块下,上述配置都可以单独进行追加
【nginx反向代理服务器对客户端的keepalive设置】
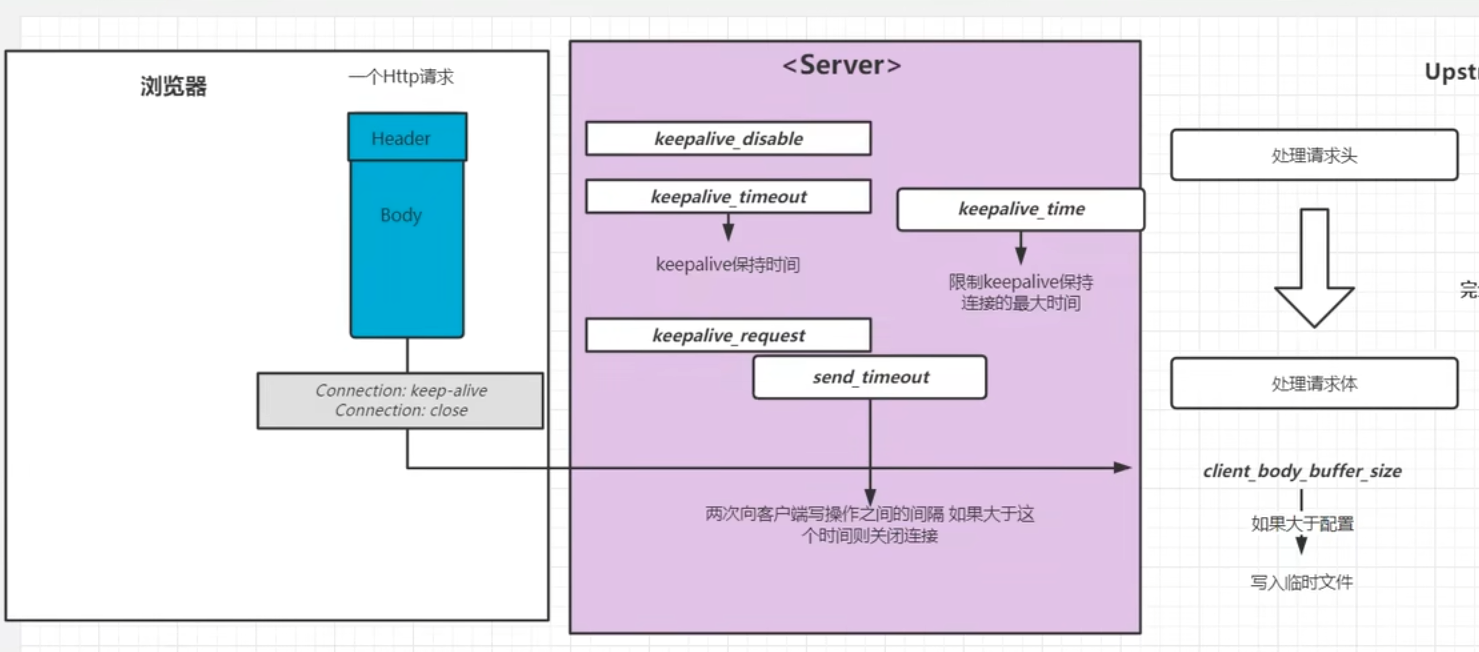
对浏览器的keepalive配置
在很多场景下还会要求避免使用长连接,只想建立短连接【比如高频访问的接口,压根对同一个用户就不可能产生第二次请求,同时对用户的数据也不需要进行缓存;针对很多客户端,每个客户端都只请求一次或者请求间隔比较长,比如开一台时间同步的服务器,有两千台服务器都需要隔段时间更新同步一下时间】,此时可以将keepalive关闭掉,
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;#这是nginx默认的对keepalive的配置,意思是当浏览器与nginx建立了一次连接之后,这个连接最长能存在多长时间不会被关闭掉,时间单位是秒,也不是建立连接后65秒就将连接关掉,指的是再次点击和上次点击即任意两次请求间的时长超过65秒才会关闭连接[超过65秒没反应就把链接关掉],这个值不能设置的过大[过大消耗资源,因为连接数多],也不能设置的过小[过小建立连接的次数多]keepalive_timeout 65;upstream stickytest{sticky;server 192.168.200.134:8080;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}keepalive_timeout=0
该配置表示禁用keepalive功能
【代理服务器的nginx.conf】
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 0;upstream stickytest{sticky;server 192.168.200.134:8080;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {proxy_pass http://stickytest;#root html;#index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【禁用keepalive的效果】
Connection为close的时候说明服务器没有启用keepalive
有时候可能服务器配置了keepalive禁用,但是实际还是在响应头中显示保持链接的情况,可以借助第三方的工具如charles来抓包观察是否还是显示长连接
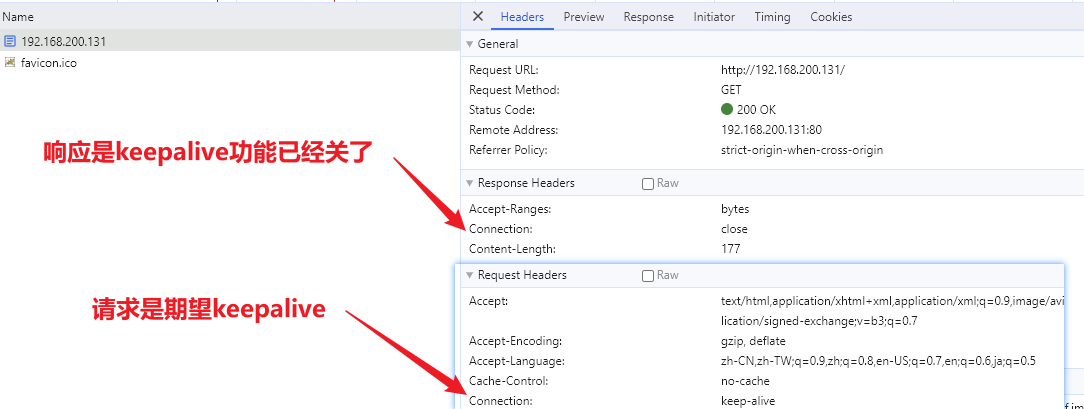
用charles抓包显示实际连接状态
charles【青花瓷】是一款测试工具,charles是由mac系统迁移到windows和linux系统上的,可以实现拦截请求和模拟请求,可以用于模拟简单的并发测试,收费的,免费版也能凑合用,抓包用windows版本的就行
下载地址:https://www.charlesproxy.com/assets/release/4.6.2/charles-proxy-4.6.2-win64.msi?k=fc1457e312
官网:https://www.charlesproxy.com
这玩意儿可以用来抓数据包看大公司的数据封装格式,看大公司是怎么封装数据的,http请求可以直接抓取到,https请求数据包抓取需要去系统中安装SSL伪证书【视频又说安装charles的根证书,看到charles再深入学习】,没有安装证书https协议的数据包是经过加密看不到内容的【又说https协议的数据也能通过charles拦截请求伪造证书来破解密文,以后学一学,这儿没听懂,为什么在不知道第三方...好像懂了,应该是拦截本机的请求,封装以后由charles来代替用户向目标发起请求,获取到数据以后由charles解析接口数据并将数据展现给用户接口数据的组织形式,应该是在浏览器无法看到响应的接口数据格式】
使用说明
红色按钮表示当前正在录制记录当前系统发出的所有请求【包括除了浏览器发起的其他请求】,打开应用就是默认开启监控功能的
小扫把表示清理掉之前的所有监控记录
监控的请求根据一个站点来进行分组【ip和端口】,对同一个站点访问的请求归档在一个组下
没有使用keepalive的请求点开会显示keepalive为No,浏览器可能因为各种问题显示错误,此时就可以使用这种抓包工具来看;使用了keepalive会显示keepalive为yes
可以在请求详情中的Timing可以看到各种延迟信息:DNS延迟、连接的延迟、请求耗时、响应耗时、连接的速度等信息
对记录的请求可以右击选择
repeat重复发起一次请求,点击选择Advanced Repeat可以设置重复发起多次请求,请求间的时间间隔【可以发起并发请求】,但是一般不用这个来做压力测试点击window--Active Connections可以看到当前系统开并维持了多少连接【似乎也是被记录的连接而不是实时的连接,而且右键重复发起请求不会显示在Active Connections中,即charles发起的请求不会被连接窗口记录】,在开启keepalive的前提下单个连接中的transactions字段会显示一个连接中发起了多少次请求,在关闭keepalive的前提下浏览器重复发起一次请求会创建一次新的连接
在代理服务器nginx中对上游服务器做配置
上游服务器和nginx之间使用keepalive一定是使用nginx做的七层代理,且代理的上游服务器是基于HTTP协议的
nginx对上游服务器keepalive的可配置参数
Upstream中的配置【一组服务器集群中的配置】
keepalive 100:nginx与上游服务器间使用的保持会话的连接池的保留连接个数【线程池也有保留的线程个数】,这里其实还是没有讲清楚,应该是空闲时保留的连接个数最大可以是100个;使用LRU算法对连接数进行管理,不需要配置的过大,因为一个连接可以复用发起N多个请求
keepalive_timeout 65:连接保留超时时间,不知道这个超时时间是指向上游服务器连续两次发起请求的间隔时间还是上游服务器连续两次响应的超时时间间隔
keepalive_request 1000:一个TCP复用连接通道中,可以同时并发发起的请求个数为1000
【配置示例】
xxxxxxxxxxupstream stickytest{keepalive 100;keepalive_request 1000;keepalive_timeout 65;server 192.168.200.134:8080;server 192.168.200.135:8080;}server中的location配置【单个站点的配置】
proxy_http_version 1.1:配置上游服务器的http协议版本号,默认使用的HTTP1.0协议,默认是每次发起请求后会将连接关闭,配置keepalive能很有效的减少连接上的开销,但是1.0版本的HTTP协议需要在request的请求头中增加参数
Connection: keep-alive才能支持keepalive,而HTTP1.1协议默认就支持,且实现keepalive方式的效率相对于1.0版本更高;每次建立连接都需要进行三次握手,每次消耗的时间对比数据传输来说消耗的时间很长proxy_set_header Connection "":将nginx代理的请求中的请求头参数设置为空串,改成keepalive也可以【设置成这两个参数都可以【1.1版本是这样,1.0版本要求参数必须写成
Connection: keep-alive】,改成空串1.1版本就默认使用长连接】,因为默认是将该Connection参数改成closenginx做反向代理服务器代理用户的请求,转发请求过程中会把请求的头信息全部清理掉【像客户端信息,客户端ip等信息】,然后再转发给后端服务器【后端服务器实际上不知道用户的具体信息,但是为啥之前用sticky来生成cookie做负载均衡会话管理的时候,上游服务器能够把jsessionid改成正确的值呢,说明还是知道用户来自于那个ip下的嘛】,而且浏览器和nginx建立起长连接后,nginx默认情况下会将请求头中的Connection参数改成close
Connection:close,明确告诉上游服务器和nginx之间不要使用长连接,每次nginx和上游服务器之间的通讯都单独建立连接
【配置示例】
xxxxxxxxxxserver {listen 80;server_name localhost;location / {#配置示例proxy_http_version 1.1;proxy_set_header Connection "";proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}【nginx服务器对上游服务器的keepalive配置】
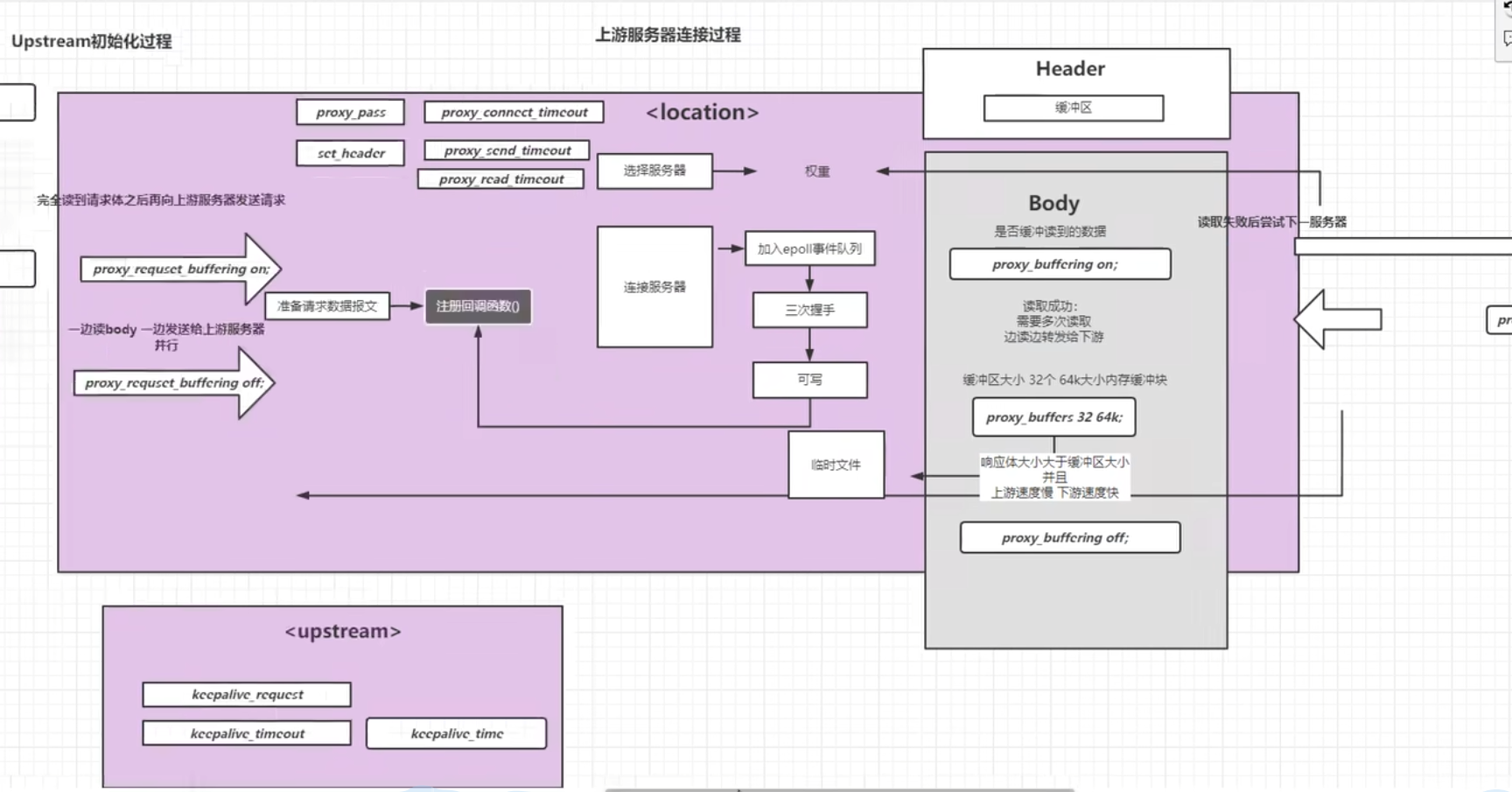
【上游服务器】
AB压测工具
AB测试工具是apache基金会下的,全称apache benchmark,通常简称为AB Test,清量简单的小工具,适合机器配置不高的时候使用,这最早是apache httpd服务器中内嵌工具包的一个工具
随便找一台虚拟机安装进行测试,安装在tomcat服务器上对不含该tomcat的后台系统进行压测,本次安装在134上
安装AB工具
安装步骤
使用命令
yum install httpd-tools安装ab工具
AB工具的命令
命令参数说明
完整命令行:
ab [options] [http[s]://]hostname[:port]/path一般用
-n和-c两个参数就足够了,使用ab命令就能调出以下的参数说明,用options代指,深度使用需要专门学习一下
-n
即requests,用于指定压力测试总共的执行次数。
-c
即concurrency,用于指定的并发数。
-t
即timelimit,等待响应的最大时间(单位:秒)。
-b
即windowsize,TCP发送/接收的缓冲大小(单位:字节)。
-p
即postfile,发送POST请求时需要上传的文件,此外还必须设置-T参数。
-u
即putfile,发送PUT请求时需要上传的文件,此外还必须设置-T参数。
-T
即content-type,用于设置Content-Type请求头信息,例如:application/x-www-form-urlencoded,默认值为text/plain。
-v 即verbosity,指定打印帮助信息的冗余级别。
-w 以HTML表格形式打印结果。
-i 使用HEAD请求代替GET请求。
-x 插入字符串作为table标签的属性。
-y 插入字符串作为tr标签的属性。
-z 插入字符串作为td标签的属性。
-C 添加cookie信息,例如:"Apache=1234"(可以重复该参数选项以添加多个)。
-H 添加任意的请求头,例如:"Accept-Encoding: gzip",请求头将会添加在现有的多个请求头之后(可以重复该参数选项以添加多个)。
-A 添加一个基本的网络认证信息,用户名和密码之间用英文冒号隔开。
-P 添加一个基本的代理认证信息,用户名和密码之间用英文冒号隔开。
-X 指定使用的ip和端口号,例如:"126.10.10.3:88"。
-V 打印版本号并退出。
-k 使用HTTP的KeepAlive特性。
-d 不显示百分比。
-S 不显示预估和警告信息。
-g 输出结果信息到gnuplot格式的文件中。
-e 输出结果信息到CSV格式的文件中。
-r 指定接收到错误信息时不退出程序。
-h 显示用法信息,其实就是ab -help。
测试
实际测试的时候最好不要测试和服务运行都在同一台电脑上,因为发送请求也是非常消耗资源的,在本机上测试自己只能对比几种配置的性能,没法模拟系统真实的性能表现
nginx即使只代理一台服务器也是有意义的,第一有更多的方法来对上游服务器进行统一管理【负载均衡,健康检查,安全管理】,第二是做外网和内网的隔离【只要把代理服务器保护好,黑客就无法通过代理服务器入侵内网中的上游服务器,让系统更安全】,第三是节省ip,每个服务器都要在公网能被访问需要很多的公网ip,第四可以把在每台上游服务器都要处理的业务抽取到nginx、代理服务器上进行前置处理再转发,实现逻辑解耦【比如Kong网关、API six网关就是通过nginx扩展来的,可以把鉴权、网络防火墙WAF等共性功能全部抽取到nginx服务器上】
压测不要设置的请求太少,太少了看不出问题,一般至少都是连续请求五分钟以上,这里100000是很少的,连续跑100000一直跑半个小时系统就很可能崩了,此时才是真正考验代码健壮性【对系统内存的管理】的时候
注意ABtest自身不带keepalive,只是发送请求;发送请求给nginx还是tomcat都没有使用keepalive;nginx和tomcat间有keepalive
测试直连nginx服务器
直连的nginx服务器是nginx的keepalive的默认配置
使用命令
ab -n 100000 -c 30 http://192.168.200.132/并发十万个请求,此前并发过一个一万个请求的测试,注释中有的数据是1万并发量的数据
必须要添加/,否则请求会失效
【测试结果】
xxxxxxxxxx[root@node3 ~]# ab -n 100000 -c 30 http://192.168.200.132/This is ApacheBench, Version 2.3 <$Revision: 1430300 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 192.168.200.132 (be patient)Completed 10000 requestsCompleted 20000 requestsCompleted 30000 requestsCompleted 40000 requestsCompleted 50000 requestsCompleted 60000 requestsCompleted 70000 requestsCompleted 80000 requestsCompleted 90000 requestsCompleted 100000 requests#显示一共发了100000个请求Finished 100000 requestsServer Software: nginx/1.20.2Server Hostname: 192.168.200.132Server Port: 80Document Path: /Document Length: 491 bytesConcurrency Level: 30Time taken for tests: 22.487 secondsComplete requests: 100000Failed requests: 0Write errors: 0#Total transferred是总共传输的数据量Total transferred: 72400000 bytesHTML transferred: 49100000 bytes#Requests per second这个就是目标服务器的QPS,简单压测了10000个请求,每秒能够处理的请求是2307.55个,这里改成100000个请求相较于之前的QPS涨了一倍,7000已经是很高的QPS了,因为本机是虚拟机,虚拟机的性能本来就不高,分配的资源也不高,单核2g【为什么我的单核两g比老师的单核1g还要慢这么多?老师是7000】,7000并没有达到真实nginx的性能瓶颈,还要结合系统的复杂度和网络带宽,如果系统复杂度很高QPS也高不了,QPS和网络带宽也有关系,注意老师演示网络还是走的内网,QPS是一个综合因素,和硬件、网络带宽、系统复杂程度都有关系Requests per second: 4447.05 [#/sec] (mean)#这是响应延迟时间Time per request: 6.746 [ms] (mean)Time per request: 0.225 [ms] (mean, across all concurrent requests)#吞吐量,所有请求全部打到目标服务器总体的下载响应数据的速率,这个速率并没有跑满网络带宽,一个是因为请求量少,还有一个原因是响应的数据少,现在只响应一个很简单的html页面,传输数据的过程很快,但是建立连接返回请求的速度相对较慢,所以速度很难跑满Transfer rate: 3144.20 [Kbytes/sec] receivedConnection Times (ms)min mean[+/-sd] median maxConnect: 0 2 1.5 1 16Processing: 1 5 4.4 3 26Waiting: 0 4 4.3 3 24Total: 2 7 4.8 5 28Percentage of the requests served within a certain time (ms)50% 566% 575% 680% 790% 1695% 1998% 2099% 21100% 28 (longest request)
测试用反向代理服务器代理后端服务器
代理服务器配置去掉对上游服务器的keepalive配置,同时只代理一台服务器
【131的nginx.conf】
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65 65;keepalive_time 1h;keepalive_requests 1000;send_timeout 60;upstream stickytest{server 192.168.200.132;}server {listen 80;server_name localhost;location / {proxy_http_version 1.1;proxy_set_header Connection "";proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【测试结果】
在配置反向代理服务器,代理服务器和客户端有keepalive,代理服务器和上游服务器间没有keepalive的情况下吞吐量和QPS都直线下降【几乎一半还要多一些】
xxxxxxxxxx[root@node3 ~]# ab -n 100000 -c 30 http://192.168.200.131/This is ApacheBench, Version 2.3 <$Revision: 1430300 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 192.168.200.131 (be patient)Completed 10000 requestsCompleted 20000 requestsCompleted 30000 requestsCompleted 40000 requestsCompleted 50000 requestsCompleted 60000 requestsCompleted 70000 requestsCompleted 80000 requestsCompleted 90000 requestsCompleted 100000 requestsFinished 100000 requestsServer Software: nginx/1.20.2Server Hostname: 192.168.200.131Server Port: 80Document Path: /Document Length: 491 bytesConcurrency Level: 30Time taken for tests: 58.312 secondsComplete requests: 100000Failed requests: 0Write errors: 0Total transferred: 72400000 bytesHTML transferred: 49100000 bytes#QPS由4447变成了1714Requests per second: 1714.93 [#/sec] (mean)Time per request: 17.493 [ms] (mean)Time per request: 0.583 [ms] (mean, across all concurrent requests)#吞吐量由原来的3000变成1200了Transfer rate: 1212.51 [Kbytes/sec] receivedConnection Times (ms)min mean[+/-sd] median maxConnect: 0 3 2.2 2 18Processing: 3 14 7.2 12 67Waiting: 1 13 7.2 10 65Total: 6 17 6.9 16 68Percentage of the requests served within a certain time (ms)50% 1666% 1975% 2080% 2190% 2895% 3498% 3799% 38100% 68 (longest request)测试用反向代理服务器代理后端nginx服务器并开启反向代理服务器与后端服务器的keepalive
【nginx.conf】
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65 65;keepalive_time 1h;keepalive_requests 1000;send_timeout 60;upstream stickytest{keepalive 100;keepalive_requests 1000;keepalive_timeout 65;server 192.168.200.132;}server {listen 80;server_name localhost;location / {proxy_http_version 1.1;proxy_set_header Connection "";proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【测试结果】
当代理服务器和上游服务器间开启keepalive功能,QPS和吞吐量都极大提升,我这上面逼近测试请求直连nginx服务器的3/5,演示中只达到了直连时的3/4,响应延迟也提升了非常多,但和直连还是有一定差距;
在实际生产中,增加配置代理服务器和上游服务器间的keepalive一般对系统性能的提升能接近40%左右甚至更多
xxxxxxxxxx[root@node3 ~]# ab -n 100000 -c 30 http://192.168.200.131/This is ApacheBench, Version 2.3 <$Revision: 1430300 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 192.168.200.131 (be patient)Completed 10000 requestsCompleted 20000 requestsCompleted 30000 requestsCompleted 40000 requestsCompleted 50000 requestsCompleted 60000 requestsCompleted 70000 requestsCompleted 80000 requestsCompleted 90000 requestsCompleted 100000 requestsFinished 100000 requestsServer Software: nginx/1.20.2Server Hostname: 192.168.200.131Server Port: 80Document Path: /Document Length: 491 bytesConcurrency Level: 30Time taken for tests: 35.746 secondsComplete requests: 100000Failed requests: 0Write errors: 0Total transferred: 72400000 bytesHTML transferred: 49100000 bytesRequests per second: 2797.50 [#/sec] (mean)Time per request: 10.724 [ms] (mean)Time per request: 0.357 [ms] (mean, across all concurrent requests)Transfer rate: 1977.92 [Kbytes/sec] receivedConnection Times (ms)min mean[+/-sd] median maxConnect: 0 2 1.0 1 11Processing: 2 9 4.6 8 37Waiting: 2 9 4.6 7 37Total: 3 11 4.5 9 38Percentage of the requests served within a certain time (ms)50% 966% 1075% 1180% 1290% 1795% 2398% 2599% 25100% 38 (longest request)测试直连tomcat服务器
一般来说从业人员对tomcat的性能不是特别乐观,讲师说今天的测试要推翻大家常规的认识,实际上tomcat还是比nginx差,一般的服务器配置nginx能跑QPS两万左右,tomcat能跑七千左右,不像传闻的tomcat只能跑几百
linux上安装的tomcat【直接解压的tomcat】,默认应该是以APR的形式运行的网络接口,APR的形式是使用在本机C语言实现的网络接口,极大的优化了tomcat的性能,也可以利用java的nio解决的这个问题【windows上安装的tomcat默认的启动方式是bio的】,有的版本tomcat默认配置的就是APR启动方式,性能会更高

测试直连访问tomcat服务器的jsp页面
【测试效果】
除了测试直连jsp页面,还测试了以下访问tomcat的静态页面,访问jsp竟然快的多,而且jsp页面的内容更多,html只有一句话;
jsp的qps是4000左右,好的时候能上4700,但是html只有3000左右
xxxxxxxxxx[root@node3 ~]# ab -n 100000 -c 30 http://192.168.200.135/index.jspThis is ApacheBench, Version 2.3 <$Revision: 1430300 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 192.168.200.135 (be patient)Completed 10000 requestsCompleted 20000 requestsCompleted 30000 requestsCompleted 40000 requestsCompleted 50000 requestsCompleted 60000 requestsCompleted 70000 requestsCompleted 80000 requestsCompleted 90000 requestsCompleted 100000 requestsFinished 100000 requestsServer Software: nginx/1.20.2Server Hostname: 192.168.200.135Server Port: 80Document Path: /index.jspDocument Length: 153 bytesConcurrency Level: 30Time taken for tests: 27.013 secondsComplete requests: 100000Failed requests: 0Write errors: 0Non-2xx responses: 100000Total transferred: 30300000 bytesHTML transferred: 15300000 bytes#单机直连在本机上QPS是3000多,基本性能比nginx略差,真实的水平对于一般的服务器配置,nginx的QPS能跑到2万左右,tomcat大概能跑到七八千,Requests per second: 3701.86 [#/sec] (mean)Time per request: 8.104 [ms] (mean)#最小延迟Time per request: 0.270 [ms] (mean, across all concurrent requests)#返回结果数据大了这个会大一些Transfer rate: 1095.37 [Kbytes/sec] receivedConnection Times (ms)min mean[+/-sd] median maxConnect: 0 2 1.5 1 12Processing: 1 6 6.5 3 31Waiting: 0 6 6.5 3 30Total: 2 8 6.4 5 31Percentage of the requests served within a certain time (ms)50% 566% 675% 980% 1490% 2195% 2298% 2399% 24#最长延迟有31个100% 31 (longest request)测试用反向代理服务器代理后端tomcat服务器并开启反向代理服务器与后端服务器的keepalive
用了反向代理吞吐量和QPS还提升了,这是因为nginx的并发性能比tomcat好,只用ab直连tomcat,由于没有keepalive,性能最差;用ab直连nginx,期间没有keepalive但是nginx性能高,但是nginx连接tomcat有keepalive,总体的性能就高于ab直连tomcat,但是这不是实际情况,只是因为ab没有keepalive功能,把nginx和tomcat服务器的keepalive功能关了,演示结果的QPS直接从4000降成了3000,比ab直连的3200稍低【因为中转了】,随着硬件性能的提升这个比例还会放大
当 不支持keepalive的时候在tomcat前置nginx才会是系统的性能明显提升【nginx性能高,nginx和tomcat间能keepalive】,一般都是很特殊的场景【客户端不是浏览器或者一些浏览器没有keepalive】,正常情况都会努力的让客户端支持keepalive
【代理服务器配置】
对客户端请求的keepalive配置在http模块中,对上游服务器的keepalive配置在upstream中
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65 65;keepalive_time 1h;keepalive_requests 1000;send_timeout 60;upstream stickytest{keepalive 100;keepalive_requests 1000;keepalive_timeout 65;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {proxy_http_version 1.1;proxy_set_header Connection "";proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【测试效果】
关掉nginx和tomcat的keepalive就不试了
xxxxxxxxxx[root@node3 ~]# ab -n 100000 -c 30 http://192.168.200.131/This is ApacheBench, Version 2.3 <$Revision: 1430300 $>Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/Licensed to The Apache Software Foundation, http://www.apache.org/Benchmarking 192.168.200.131 (be patient)Completed 10000 requestsCompleted 20000 requestsCompleted 30000 requestsCompleted 40000 requestsCompleted 50000 requestsCompleted 60000 requestsCompleted 70000 requestsCompleted 80000 requestsCompleted 90000 requestsCompleted 100000 requestsFinished 100000 requestsServer Software: nginx/1.20.2Server Hostname: 192.168.200.131Server Port: 80Document Path: /Document Length: 177 bytesConcurrency Level: 30Time taken for tests: 42.820 secondsComplete requests: 100000Failed requests: 0Write errors: 0Total transferred: 41500000 bytesHTML transferred: 17700000 bytesRequests per second: 2335.35 [#/sec] (mean)Time per request: 12.846 [ms] (mean)Time per request: 0.428 [ms] (mean, across all concurrent requests)Transfer rate: 946.45 [Kbytes/sec] receivedConnection Times (ms)min mean[+/-sd] median maxConnect: 0 2 1.3 2 14Processing: 2 11 6.7 8 206Waiting: 2 10 6.7 8 206Total: 4 13 6.5 10 212Percentage of the requests served within a certain time (ms)50% 1066% 1275% 1580% 1890% 2395% 2498% 2699% 29100% 212 (longest request)
Nginx反向代理流程
可以在简历中体现对nginx理解的部分了,这部分在网络编程中详细有讲解
nginx是多进程同时运行业务逻辑,worker进程处理业务,worker进程中又设置多个线程并发地处理请求的读写操作
Nginx代理请求流程
请求流程和相关配置
浏览器发起的请求一定是http请求,即使https请求也是http请求的进一层封装
【Http1.x协议报文组成】
所有发送的请求都会先转换成按一定规则排列的文本,再将文本转换成二进制形式
请求行:第一行请求行中记录了请求方法、请求URL和HTTP协议的版本;并使用空格分隔,以回车符和换行符作为一行的结束标记;
请求的头部:请求头是以
key:value的方式一行一行的记录,比如Connection:keepalive,每个参数都独占行,以回车符和换行符结尾,请求头结束以单独的回车符+换行符结尾;请求数据:也叫请求体,只有post方法和put方法才有请求体,请求体中的参数;get方法的参数是直接写在请求行的URL中的,URL中是以英文问号打头,以&连接参数;
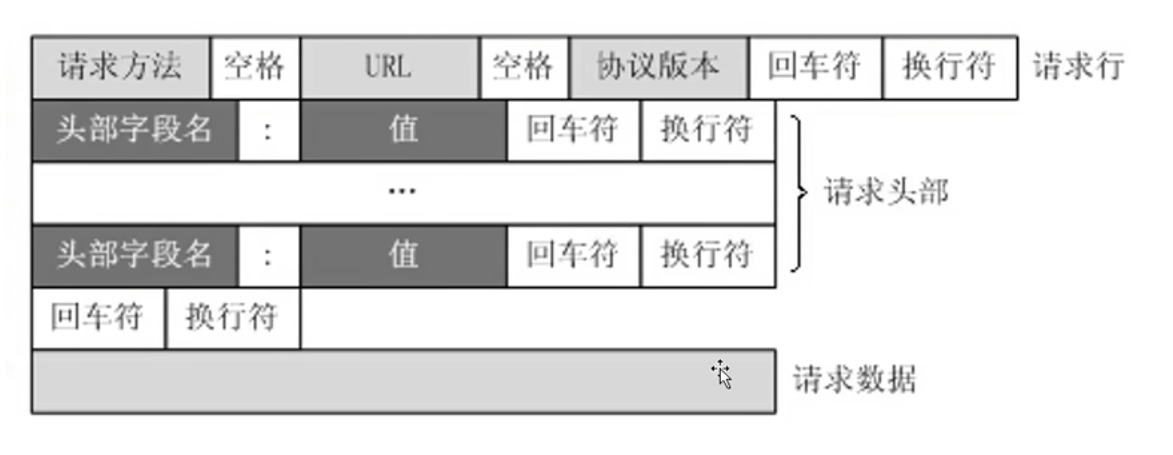
【请求报文】
General就是请求行的内容【又补充说General不是原始的报文,还有包装的信息】
nginx请求处理流程
nginx会接收到请求的二进制报文,nginx会将该报文反序列化的可读文本,逐行解析请求报文的内容,nginx解析完请求行的内容,会先去解析请求头,去获取请求希望使用的请求协议、想不想使用keepalive等其他请求参数;当请求头处理完以后处理请求体,由于用户可能上传比较大的文件,在读取请求体的同时设置一层缓冲区,缓冲区用于缓冲【缓冲不是缓存,但是没有解释,缓冲的过程中可以一点一点地读取用户提交的数据,后面解释了一下,缓冲是内存中一块区域,操作结束数据就清除了;缓存不一样,缓存中的数据会长期存在并且会被复用,缓冲更多含义临时中转的意味】客户端提交的已经读取到的内容,配置nginx的参数
client_body_buffer_size可以配置缓冲区的可使用空间;读取的过程中会根据nginx的配置
proxy_request_buffering决定nginx是否在读取的过程中就向上游服务器发起请求,如果该参数设置为proxy_request_buffering off,就会一边读取请求体一边并行向上游服务器发起请求;如果proxy_request_buffering on,会完全读取到请求体后再向上游服务器发起请求
nginx向上游服务器发起请求流程
nginx会先从用户配置的upstream服务器列表中选择一台服务器,默认情况下是以链表的形式轮询去选择服务器【即服务器列表会被nginx读取配置成一个链表】,nginx会用全异步的形式去发起请求,nginx先向操作系统的epoll事件队列中注册一个要连接请求的事件,然后经过TCP三次握手建立与上游服务器的连接,在nginx准备请求数据报文的同时会注册回调函数【怎么听着感觉回调函数是在事件注册到epoll的同时就注册的,在建立好TCP连接的时候触发,这里不清楚回调函数注册和调用的时机,或许学习计算机网络的时候会进一步学习,注意回调函数注册就是连接事件注册在epoll队列的时候,回调是连接建立完成触发可写事件的时候】,【在epoll或者java的nio中所有数据读取、网络连接建立和断开都是以事件的形式触发的,一旦触发就会去执行回调方法/函数中的内容】,当连接建立完成后会触发一个可写的事件,事件触发同时系统向nginx表明连接建立完成,可以向上游服务器执行写入数据的操作【建立连接触发可写事件是异步操作】,nginx此时才会去调取回调函数,回调函数执行的过程中向上游服务器转发客户端请求,转发客户端请求的时候nginx可以设置转发请求请求头的内容,将新的HTTP协议打包成二进制报文的格式发送给上游服务器【以上所有的操作都是异步的】,
上游服务器处理完请求后会返回响应结果给nginx,nginx还是通过epoll事件列表触发回调函数处理上游服务器返回的数据【说netty也会讲,epoll也有专门的课程】,nginx处理上游服务器返回的数据时会根据配置
proxy_buffering来判断是否对上游服务器返回的数据进行缓冲,由于上下游服务器网络传输速率的问题,如果上游服务器响应的文件过大,此时就要考虑文件怎么处理的问题,不可能上游服务器传输一部20G的电影全部加载到nginx服务器的内存中;在nginx中有一个proxy_buffering的配置,如果proxy_buffering off,那么nginx将不使用缓冲功能【理解成缓冲区域非常小,几乎忽略不计,确认了proxy_buffering off就是不会使用内存缓冲区】,此时客户端读取多少nginx就从上游服务器获取多少,这种方式最大的问题是nginx中读取上游服务器数据的线程一直处于占用状态,和上游服务器的网络连接一直终断不了【比如20G的电影传递到nginx只要20s,但是传递给用户需要20h,没有缓冲区该nginx与上游服务器的连接就会持续20h无法终断,nginx的读取线程也会一直处于被占用的状态,夸张手法】;一般都将nginx的缓冲参数设置成proxy_buffering on,让上游服务器的数据缓冲到缓冲区,从而断开网络连接和释放读取线程,当缓冲区的数据全部传递给客户端后再次建立或者复用连接再次读取数据到缓冲区直至数据完全传递给客户端,nginx通过参数proxy_buffers对缓冲区进行配置,proxy_buffers 32 64K表示在内存中分配的缓冲区大小为32个64K大小的内存缓冲块【2M,一般来说传递的数据就只有几百k或者几M大小,20G是非常极端的情况】注意不论是否使用请求体的缓冲功能,请求头的缓冲功能是一直开启的,配置请求头缓冲区的参数是
proxy_buffer size确定的,如果把请求体的缓冲功能关闭即proxy_buffering off,nginx会直接利用请求头缓冲区来简单缓冲数据,即上面理解成的缓冲区域非常小,其实就是在请求头缓冲区开辟出的小缓冲区【除了简单请求,一般请求头缓冲区的大小都是不够的,也不会向磁盘缓冲区缓存数据,此时不会断开与上游服务器的连接,会一直等待读取上游服务器数据】如果内存缓冲区的容量用光了【内存缓冲区够用不会使用磁盘缓冲区】,此时会继续接收上游服务器的数据,将数据写入磁盘【磁盘缓冲区】,磁盘的临时文件总大小【所有的临时文件】由参数
proxy_max_temp_file_size 1024m确定,默认情况下一个1G大小【再次听解释好像还是说这个1G和一次性从上游服务器读取的大小有关,并不一定是每个文件只能写8k,只是每次只能写8k,这里的1G大小到底是指磁盘划分出临时文件最大总大小还是单次从上游服务器读取文件的大小上限,以及单次写8k是一个文件只能写8k,文件数据写成多个文件的形式还是文件数据每次只能写8k,但是文件数据都写在一个文件中需要明确】;临时文件的位置由参数proxy_temp_path /spool/nginx/proxy_temp 1 2,1 2表示在/spool/nginx/proxy_temp目录下在创建一个2级目录【建立两级目录的目的是当并发量太大的情况下如果不分级存储那么一个目录下的文件数量可能会非常高,此时的检索效率就会降低】,实际的临时文件路径可能是/spool/nginx/proxy_temp/7/45/00000123457;临时文件每次写入数据时写入数据量的大小由参数proxy_temp_file_write_size 8k确定,这里设置的是8k,不能设置的太大,解释的原因是写的太多占资源,没听懂啥意思;【小了和不缓存有啥区别,内存缓冲区2M,磁盘缓冲区8k,那直接把内存缓冲区加8k影响也不大啊?难道后续数据是分多个文件存入磁盘缓冲区,每个文件最大8k吗】上下游服务器速率问题:nginx向客户端【手机、浏览器】响应数据要通过公网,公网的网络不稳定,数据传输速率极有可能跑不满网络带宽;上游服务器和nginx间的网络一般是局域网,局域网中的速度是非常快的,非常容易就把网络带宽跑满,数据瞬间就能传递到nginx;导致数据没法不积压在nginx就直接传递到客户端
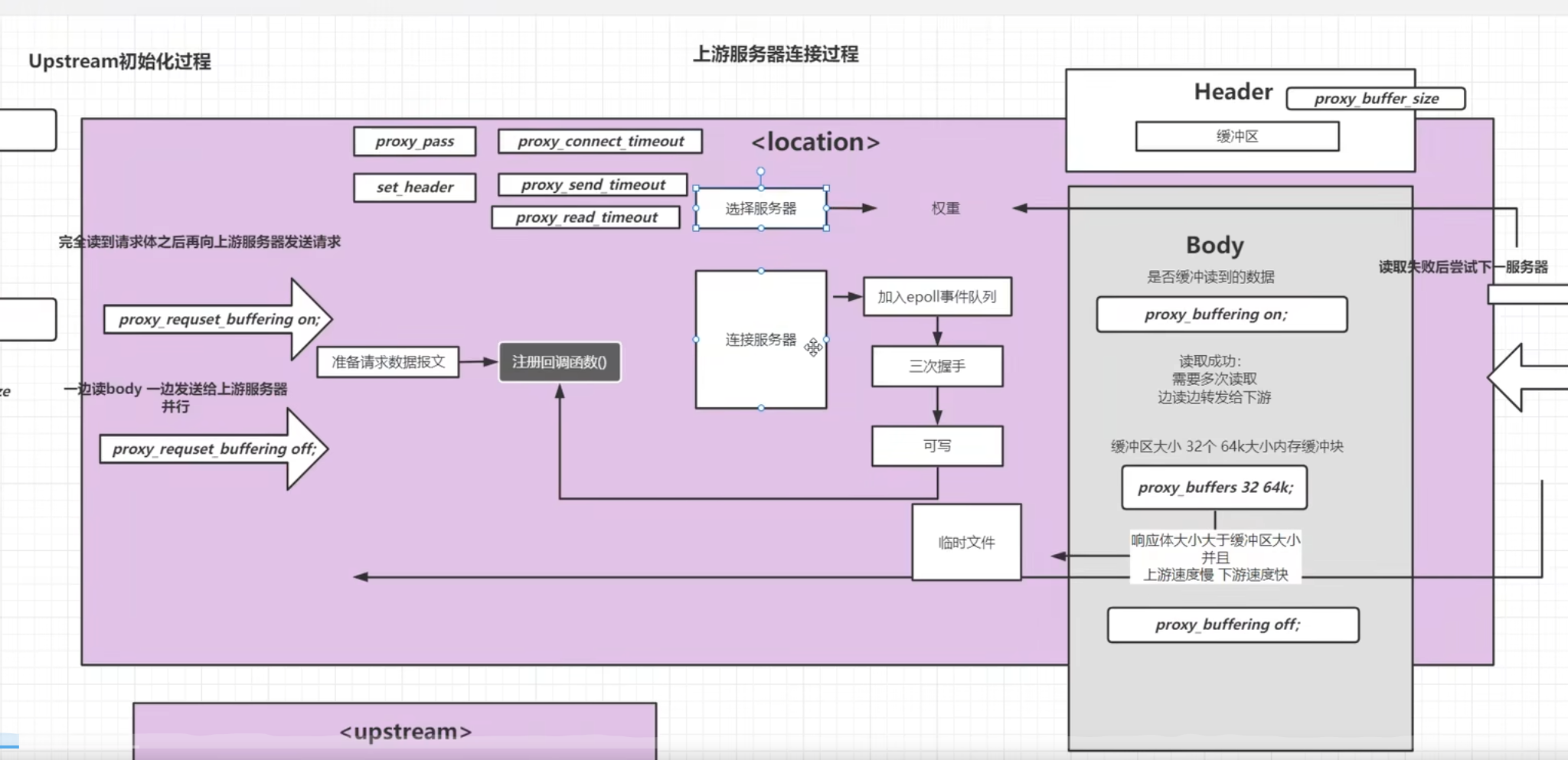
请求流程涉及参数总览
这个是配置在location中吗?没有看到有配置演示,但是图上写的是location,使用的时候查询一下配置地方,配置图片就不截取了,配置参数都是以下列出的这些,配置位置图上显示location,自己再研究一下
set_header
设置header
proxy_connect_timeout
与上游服务器连接超时时间、快速失败
proxy_send_timeout
定义nginx向后端服务发送请求的间隔时间(不是耗时)。默认60秒,超过这个时间会关闭连接
proxy_read_timeout
后端服务给nginx响应的时间,规定时间内后端服务没有给nginx响应,连接会被关闭,nginx返回504 Gateway Time-out。默认60秒
【缓冲区】
proxy_requset_buffering
是否完全读到请求体之后再向上游服务器发送请求
proxy_buffering
是否缓冲上游服务器数据
proxy_buffers 32 64k;
缓冲区大小 32个 64k大小内存缓冲块
proxy_buffer_size
header缓冲区大小
xxxxxxxxxxproxy_requset_buffering on;proxy_buffering on;proxy_buffer_size 64k;proxy_buffers 32 128k;proxy_busy_buffers_size 8k;proxy_max_temp_file_size 1024m;proxy_temp_file_write_size 8k
当启用从代理服务器到临时文件的响应的缓冲时,一次限制写入临时文件的数据的大小。 默认情况下,大小由proxy_buffer_size和proxy_buffers指令设置的两个缓冲区限制。 临时文件的最大大小由proxy_max_temp_file_size指令设置。
proxy_max_temp_file_size 1024m;
临时文件最大值
proxy_temp_path
xxxxxxxxxxproxy_temp_path /spool/nginx/proxy_temp 1 2;a temporary file might look like this:
xxxxxxxxxx/spool/nginx/proxy_temp/7/45/00000123457
nginx对接收客户端请求的配置
nginx对客户端配置可以配置在http模块、也可以配置在server模块,还可以配置在location模块;三者的关系有点像maven的依赖管理,http中配置了会被子模块server和location继承,server中配置的会覆盖http中的配置并同时被location继承,location是最小配置;对客户端整体的配置可以配置在http模块下,对服务器与客户端之间可以在server和location中进行更个性化的配置
常用的对客户端配置参数
nginx服务器在对客户请求进行代理前,需要对客户端请求进行一些校验工作和预处理
一般来说这些配置都不用动,在特殊需求下需要进行调整
client_body_buffer_size
对客户端请求体设置内存缓冲区大小, 默认32位操作系统分配8K。 64位操作系统默认是16K,如果请求体大于配置缓冲区大小,则将整个请求体或仅将其部分写入临时文件。
这个可以适当调整,如果请求都是get请求,请求体都没啥,这个默认配置完全就够用了;如果有提交数据,需要分辨是否表单提交【表单提交16k也是完全够用的,一般1k就够用了】,如果是上传文件的需求,这个缓冲区大小需要考虑文件大于缓冲区会写入临时文件的问题,此外这个配置可以针对不同的server和location进行更改,对于专门处理文件上传的location站点可以将内存缓冲区配置的更大一些
client_header_buffer_size
设置读取客户端请求头的内存缓冲区大小 ,如果一个请求行或者一个请求头字段不能放入这个缓冲区【请求头数据非常大,一般都是url特别长的情况下,其次是特殊需求下header的配置属性比较多】,那么就会使用名为large_client_header_buffers的另外一块缓冲区,正常情况下都是够用的
client_max_body_size 1000M;
对请求体的文件大小进行限制,而且是在文件接收之前就对文件大小进行检测以决定是否对文件进行接收,不会等待接收文件的中途才会去检验文件的大小;检测原理是请求的请求头中有一个content-length的属性,该属性标记了请求体数据的大小【但是前面不是说请求报文生成以后转成二进制吗?难道请求头和请求体的数据是分开传递的吗】;这个需要根据实际情况进行调整,因为默认是1MB大小,连图片都不一定能上传上来,如果一个请求的大小超过配置的值,会返回413 (request Entity Too Large)错误给客户端,将size设置为0将禁用对客户端请求正文大小的检查。
client_body_temp_path path
[level1[level2[level3`]]]当内存缓冲区的空间满了就会将数据存入磁盘缓冲区,该参数设置缓存路径,最多可以设置3层目录,避免并发请求情况下的单层目录文件过多
client_body_timeout
指定客户端与服务端建立连接后发送 request body 【nginx读取请求体等了设置的时间没有读到请求体就报错并返回408,是指一直没有读取到请求体数据,请求体数据读取过程中是不计入这个时间的,如果数据读取到一半读不到数据了,这个时间从0算起,到了设置时间还没再次接收到数据就提示超时,简单的说请求体获取期间不活跃时间超过设置时间】的超时时间。如果客户端在指定时间内没有发送任何内容,Nginx 返回 HTTP 408(Request Timed Out),避免请求过程中网络中断浪费服务器网络带宽和连接资源;从这里可以看出请求体和请求头的读取很可能是分开的
client_header_timeout
客户端向服务端发送一个完整的 request header 的超时时间。如果客户端在指定时间内没有发送一个完整的 request header,Nginx 返回 HTTP 408(Request Timed Out)
client_body_in_file_only on;
一般不咋用这个,把body写入磁盘文件,请求结束也不会删除;一般用来做数据分析上的操作,比如想看看用户请求上传的东西是什么或者需要对这些数据做额外的处理需要设置该参数,设置以后nginx会完整的把请求体的数据写入磁盘缓冲区,即使请求没有请求体,也会记录一个0字节大小的文件,这个在线上服务器千万不要配,很容易就把服务器给撑炸了
client_body_in_single_buffer
常用于二次开发,不做二次开发一般不太配置该参数;意思是尽量缓冲body的时候在内存中使用连续单一缓冲区,在二次开发时使用
$request_body读取数据时性能会有所提高【request_body是nginx中的一个系统变量,通过该变量就可以读取到用户请求体中的具体内容】,如果请求体数据分布在多块区域,读取请求体的速度会慢一些,如果开辟连续的缓存区来缓冲请求体,读取时的速度会快一些。large_client_header_buffers
默认是8K大小
上游服务器获取用户IP
使用java获取用户IP地址的代码
正常java代码从HttpServletRequest对象中可以获取用户的主机,端口和IP地址,还有获取其他信息的,记不住没关系,打个断点看看request中有啥属性对应获取
因为java应用一般在上游,可能涉及将用户IP加入黑白名单的情况,此时需要获取用户的ip地址
xxxxxxxxxxEnumeration<String> headerNames=request.getheaderNames();//获取用户的请求头信息String remoteHost=request.getRemoteHost();int remotePort=request.getRemotePort();String remoteAddr=request.getRemoteAddr();String ipAddress=requrest.getHeader("x-forwarded-for");【没有经过代理的java直接获取用户IP信息】
127.0.0.1是IPV4的IP地址,浏览器访问IPV4的地址,后端接受到的才会是IPV4的IP;如果是访问localhost,IP则会显示0:0:0:0:0:0:0:1
上游服务器tomcat部署java程序
将写了获取用户请求IP地址的java程序打成jar包,直接传到tomcat的root目录,直接用java -jar命令启动,这貌似不是用linux上的tomcat运行的,有点像用SpringBoot内置的tomcat运行的,因为我windows上的jar包不需要再配置在tomcat中就能运行;
【访问效果】
这是在linux上直接访问该服务器对应接口的效果
IP地址变成192.168.44.1了,浏览器发送请求会随机的选择一个端口号,不需要管端口号

使用反向代理服务器代理用户请求原先的代码无法获取到用户的IP地址
【windows上的IP地址】
无线网的地址是192.168.31.180【这个是和外网相连的IP地址】,虚拟的网络适配器【VMWare新加的IP地址】是192.168.176.1和192.168.44.1【44.1不是网关,是为了能和虚拟机通信设置的第二个网卡,必须和虚拟机在同一网段。配置虚拟机的时候,vmware默认的网关的ip是44.2。在新版linux有详细介绍】
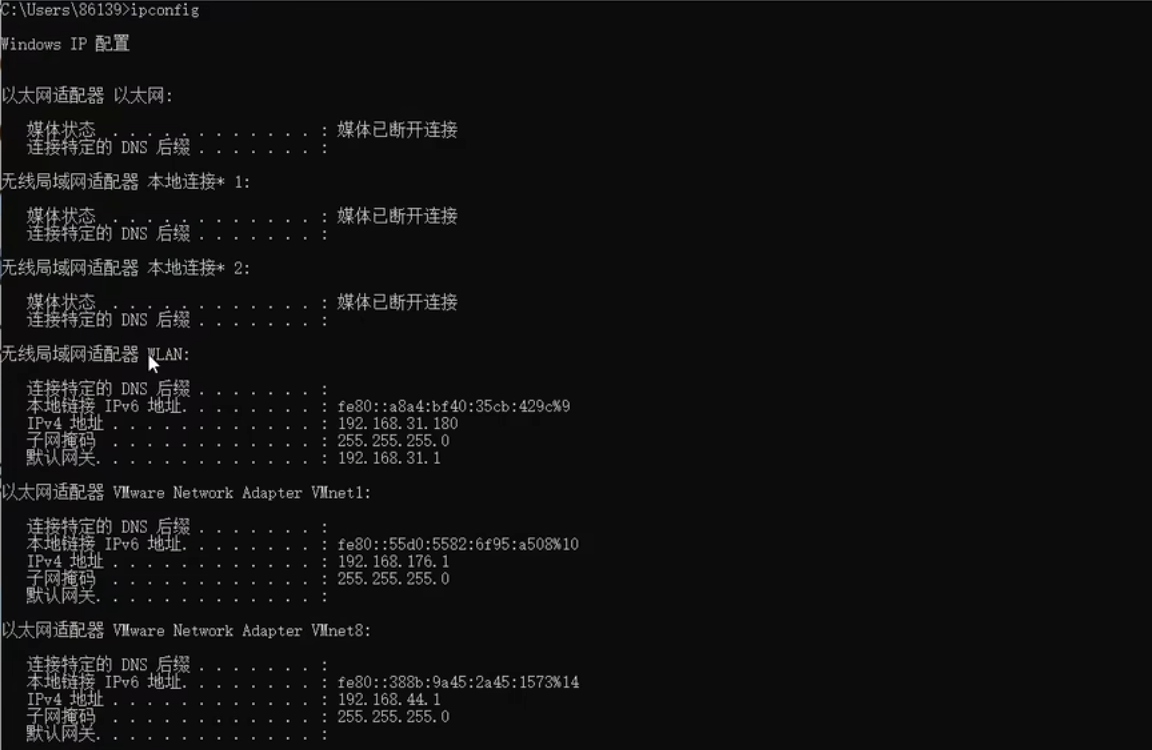
【宿主主机访问虚拟机的原理】
宿主主机的无线网络IP是180,宿主主机【windows】需要额外的一个网卡才能访问到内部的虚拟机,宿主主机通过虚拟网卡【虚拟网卡就是44.1】才能访问到虚拟机的网卡【这个就是跑java程序的虚拟机】,虚拟机能够读到的是虚拟网卡的IP
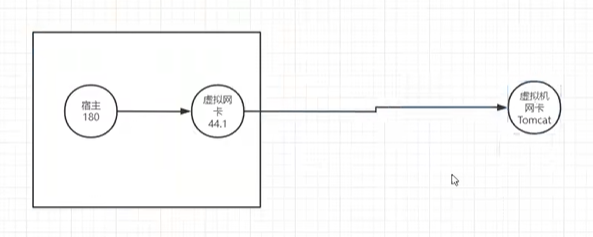
【添加一层反向代理服务器】
如果在虚拟网卡和java程序所在服务器之间再加一台IP101的反向代理服务器,虚拟机只能获取反向代理服务器的地址,无法获取到真正客户端的IP地址

【反向代理服务器访问效果】
并没有获取到真正的ip地址44.1【虚拟机访问才是44.1,公网访问是180】,实际上上游服务器获取的IP地址是反向代理服务器的
这个
ipAddress:null实际上是还没有在反向代理服务器中配置X-Forwarded-For属性,所以读取不到对应的属性值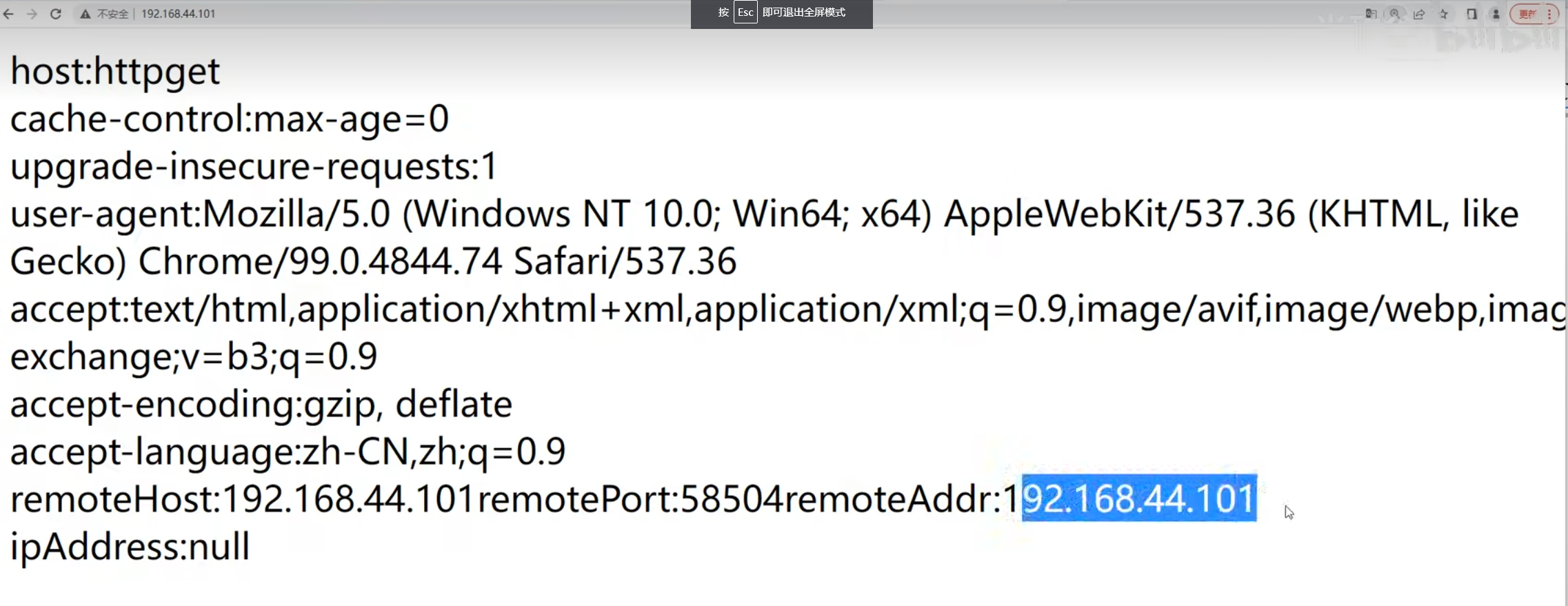
使用
x-forwarded-for获取用户真实IPX-Forwarded-For是一个扩展的Header,并不在HTTP1.1的协议中,可以在反向代理服务器中通过以下配置即客户端发起请求的请求头中的
remote_addr属性将客户端IP写到该Header额外的X-Forwarded-For属性中【反向代理服务器中完成】,此时不在java程序中通过默认的请求头remote_addr找到相应的客户端IP地址,因为remote_addr是记录真实物理TCP连接的下游服务器IP地址,是无法篡改和伪造的,通过remote_addr是拿不到客户端的IP地址的,此时需要获取请求头中nginx封装的X-Forwarded-For属性【后端程序获取该属性值并展示在ipAddress:中】来获取nginx反向代理服务器像请求头中封装的客户端IP地址【?但是网关服务器多层中转过程中应该也会涉及到这个问题,但是网关服务器应该有对用户IP独特的一套解决方案和处理,可以理解成网关已经解决了该问题,传递到目标服务器上的地址就是客户端IP】proxy_set_header是向请求的请求头中添加属性和属性值【k-v键值对】,
$remote_addr是引用接收到的请求的真实TCP物理连接的IP地址,此前对反向代理服务器和上游服务器使用keepalive也用到了向请求头添加或者修改参数的信息proxy_set_header Connection "";,该属性配置在location中由此也引发出一个问题,在经过中转代理服务器或者使用postman发送请求能够向请求头编辑
X-Forwarded-For属性信息来达到伪造客户端IP地址的效果;实际上是无法实现的,因为经过nginx代理服务器,所有的请求头信息会被nginx重置,nginx会根据真实的$remote_addr来重新为X-Forwarded-For属性赋值【?还是有疑问,$remote_addr在多层网关服务器中是怎么处理的】,还可能存在系统越来越大,一个nginx反向代理服务器后还可能存在其他的反向代理服务器【小系统一般是不会有两层nginx服务器的,但是可能存在nginx前面有一层lvs的情况,此时只有lvs能获取到物理连接上的$remote_addr完成赋值,但是到了第二层反向代理服务器上,$remote_addr是lvs和反向代理服务器的TCP连接的lvs的IP地址,此时第二层反向代理服务器无法完成对额外属性X-Forwarded-For进行客户端的IP地址赋值】,这些nginx服务器可能还会承担一些逻辑上的工作:鉴权、URL的重写等业务工作xxxxxxxxxxproxy_set_header X-Forwarded-For $remote_addr;【配置示例】
xxxxxxxxxxserver {listen 80;server_name localhost;location / {#配置示例proxy_http_version 1.1;proxy_set_header Connection "";proxy_set_header X-Forwarded-For $remote_addr;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}【配置效果】
此时ipAddress已经变成了客户端的ip地址了,如果java程序还是读取
remoteHost或者remoteAddr,仍然会读到反向代理服务器的地址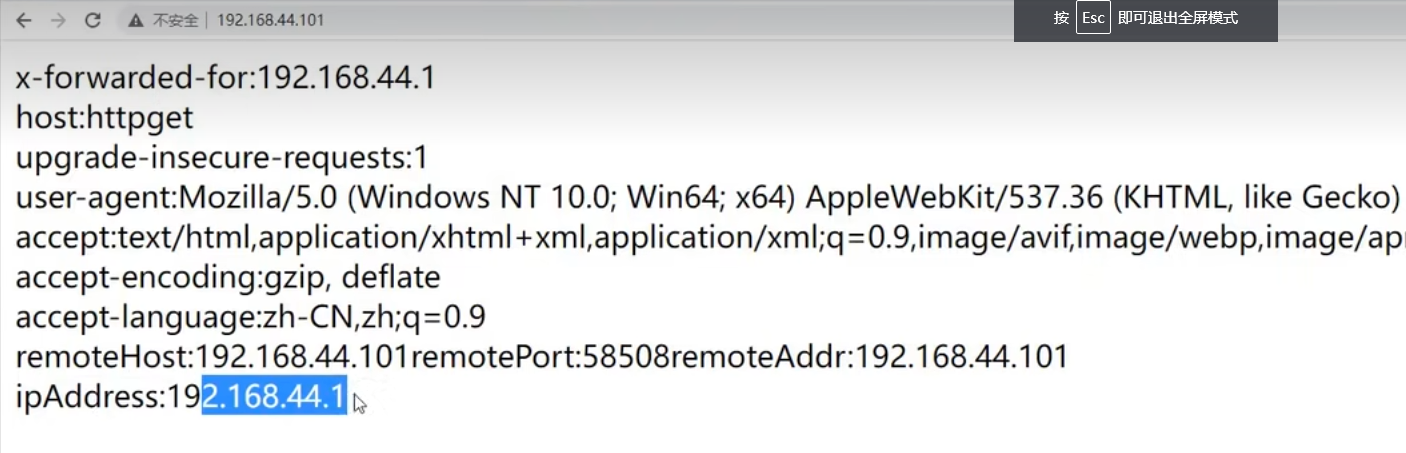
两层反向代理服务器获取客户端IP的方式
简单系统lvs+nginx构成两层;复杂系统可能本身就存在多层nginx的情况;这种情况最大的问题是第二层反向代理服务器无法通过
$remote_addr获取到客户端的IP地址来给X-Forwarded-For赋值,对于这种情况一般有两种解决方式【这是两种最简单的方案,还有很多第三方的工具和module也提供相关解决方案】以下两种方式都建立在在nginx代理服务器中能够随意操作被接收请求的请求头信息,并没有对配置进行演示,盲猜可以通过配置
proxy_set_header x-forwarded-for $x-forwarded-for和proxy_set_header x-forwarded-for $x-forwarded-for,$remote_addr对两种情况分别进行配置第一种方式
在第二层和后续反向代理服务器不再使用
$remote_addr来为X-Forwarded-For赋值,而是直接传递上级代理服务器传递过来的X-Forwarded-For属性直到传递到上游服务器
第二种方式
在第二层和后续反向代理服务器中追加前一个反向代理服务器的IP地址形成
X-Forwarded-For:客户端ip1,第一层反向代理服务器ip2
【两层代理服务器结构图】
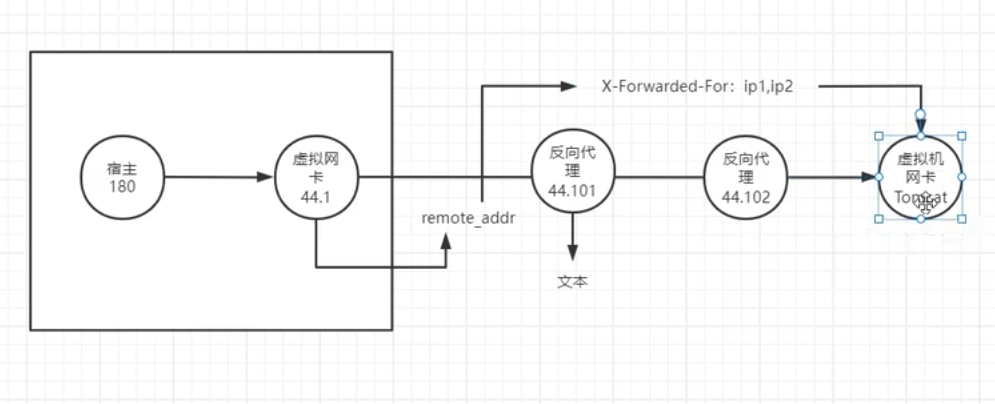
Http协议中比较有用的请求头信息
浏览器最原始的请求头报文中的第一行实际上是请求行的内容
显示出来的头信息中没有设置端口ip等信息,这些信息存在哪儿的,还是一些默认的请求头配置,只是这里没讲
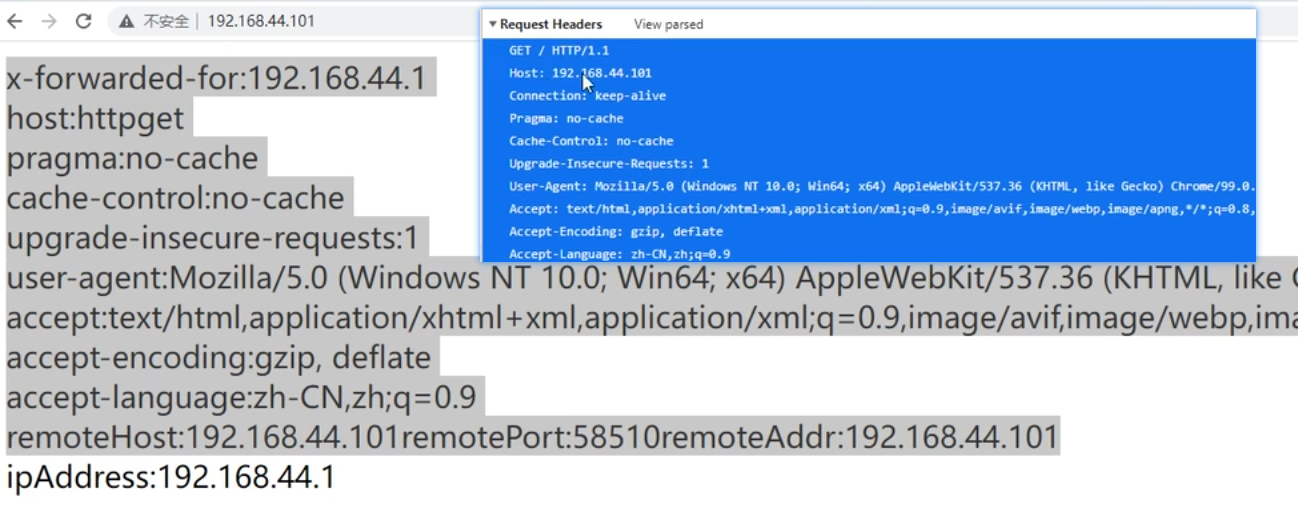
x-forwarded-for:是nginx反向代理服务器中手动设置的用以表示用户IP地址的属性
host:是请求的目标地址,nginx反向代理服务器会将upstream的名称自动覆盖掉最初的请求头Host信息
Pragma:是和缓存相关的配置,表示可以利用浏览器的缓存存储一些请求的结果,主要是一些不会经常变化的静态资源,能极大地提高目标服务器的并发量
cache-control:也是和缓存相关的配置
upgrade-insecure-requests:Chrome浏览器会默认添加该信息,表示当前请求使用的是Http协议,浏览器也会显示不安全;这个头信息可以看做chrome浏览器告诉服务器端可以升级成https协议
User-Agent:能够表明当前系统使用的浏览器的操作内核,系统版本等客户端信息;有这个就可以判断请求来自于PC、手机还是笔记本;是windows系统还是mac;根据这个信息就可以自动响应给用户对应平台的资源如安装包【这个还可以深入研究一下细节,比如如何进行平台判断等等】
accept:accept是浏览器能够接受的一些响应数据类型【text/html是MIME的类型的一种,是客户端能够正常展示和处理的数据类型】
accept-encoding:gzip意思是服务器端数据在传输的过程中可以将数据进行压缩,打成一个压缩包响应给浏览器,浏览器再将压缩包解压开,用户感知不到这个过程,但是实际数据传输过程很有可能使用了gzip对数据进行压缩,能够提升网络传输数据包的效率【传输文本的时候压缩效率比较高,但是传输图片时效率并不高】
accept-language:浏览器能够接受的语言,比如此处是期望语言使用中文
Gzip动态压缩
Gzip动态压缩:所有的请求到服务端返回数据都会进行一次Gzip压缩,就是以下所有配置的方式就是动态压缩,这种压缩方式有一个致命的缺点,所有的文件无法再使用nginx的sendfile高级特性,sendfile针对本地磁盘文件,开启sendfile数据零拷贝,直接发送信号给系统内核,内核直接从磁盘上找到对应的文件,不加载到nginx内存中直接通过网卡驱动将数据传递给用户,sendfile开了因为少了一次内存拷贝,数据响应速度是非常快的,一旦开了Gzip动态压缩功能,sendfile就自动无效了;但是现在大多网站都在用gzip,也在用sendfile,是因为还有一种gzip静态压缩方式
Gzip压缩原理
Gzip是针对网络数据传输过程进行数据压缩,该功能需要客户端和服务器端都支持gzip,主要的原理是客户端和服务器端在协议请求头上增加一个参数
accept-encoding:gzip表明客户端如浏览器支持gzip,服务器端看见请求头中有客户端支持gzip的信息,就会把数据包压缩成压缩包【还是.zip的格式】发给客户端,可以在服务器端设置压缩的等级,压缩等级越高,压缩比就越高,压缩出来的文件也越小,传输效率越高,同时压缩和解压时对CPU资源的消耗也越高,解压的时候速度就会显得慢一些;对于zip解压缩操作来说,电脑性能一般都是过剩的,对客户端没什么压力,但是对于服务器来说,在频繁高并发情况下这种压缩还是比较消耗CPU性能的,一般构建网站都会配置Gzip来稍微压缩一下响应数据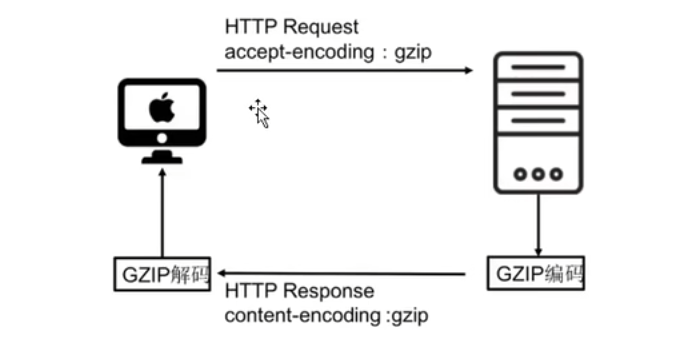
京东的Gzip压缩示例
第一个请求jd.com是用户输入域名的请求过程,general中显示301内部重定向到www.jd.com,此时www.jd.com的响应码是200,表示响应成功;在响应头中有Content-Encoding:gzip就表示数据包使用了gzip,Content-length是文档的大小,Server显示的是nginx【京东就使用的nginx】,除了主页用了gzip,在引用的请求中,jquery.js也用的gzip进行压缩;gzip在国内网站是非常流行的一种方式了
【谷歌的数据压缩格式】
chrome也是谷歌开发的,内置了对br算法的支持,如果浏览器不支持br算法,浏览器是打不开google返回的数据的,就好比rar无法解压缩zip文件,因为压缩算法和协议就不一样,br算法现在主流浏览器都是支持的;此外还有很多基于Chrome内核在外面套了一层构建的第三方浏览器,实际上使用的还是谷歌浏览器,使用的还是谷歌浏览器的加密算法、压缩算法等,所以br压缩算法在国内基本也是通用的
谷歌用的是br,br是另外一种压缩算法,这是谷歌自己开发出来的
Gzip相关配置参数
Gzip的配置也可以写在
http,server,location模块下,gzip on;
开启Gzip压缩功能,默认是关闭的
gzip_buffers 16 8k;
nginx对响应数据压缩的过程中使用多少的内存缓冲,这里配置的是16个大小为8K的内存缓冲块,这个主要根据操作系统和CPU是32位还是64位进行配置,32位操作系统和CPU建议配置成32个4k的内存缓冲区,64位建议配置成16个8k的内存缓冲区
gzip_comp_level 6;
选择gzip压缩算法的压缩等级,数字1-9都可以配置,1基本上就是不压缩,压缩等级越低,压缩解压速度就越快,压缩比也越小;同一个压缩等级对不同的文件类型压缩出来的压缩比也是不一样的,压缩比高的情况1M可能压成200KB,但是对CPU的消耗比较高,一般都配置成1-6,别搞得太高,CPU受不了
gzip_http_version 1.1;
配置gzip压缩能够支持的最低的HTTP协议版本号,现在主流浏览器上都默认支持1.1版本以上的Http协议,也支持2.0版本,少部分的实验版本浏览器支持3.0的HTTP协议,可配可不配,因为基本上浏览器默认就是1.1以上的协议版本
gzip_min_length 256;
设置是否对文件进行压缩的文件大小阈值,小于256K的文件不进行压缩,直接传输;大于256K的文件进行压缩;一般配置成1-5K都可以,不能配置的特别小
gzip_proxied any;
这个配置官方文档和网上的文章都解释的不清楚
这个是nginx作为反向代理服务器的时候可以根据上游服务器响应的头信息配置一些额外的压缩条件【只有nginx作为反向代理服务器该配置才生效,制作静态文件存储时这个选项是没有用的,配置了也没有效果】,off和any两种配置比较常见,off相当于不做任何配置,相当于该选项被关闭;any表示不根据上游服务器的头信息进行判断,所有请求满足其他配置条件的全部被压缩【没有说,说的是无条件启用压缩,这里我是猜的】;any和off的效果是一样的【不一样,从中文官方文档上显示的是off是关闭所有的代理结果数据的压缩,但是官网的默认值就是off,那岂不是只对nginx上的静态资源进行压缩,这里需要留意一下到底是什么意思,暂时就用any】;
其他的配置参数针对的是上游服务器响应的头信息中带有缓存相关的header【一般来说被cache的数据都是准备缓存在浏览器上的,一般来说需要启动cache的数据都已经被压缩过了,不需要再进行压缩了】或者是权限相关的Header来决定是否对上游服务器响应的数据启用压缩
完整配置参数:
off - 为不做限制【有两条弹幕说官方文档上该选项是禁止使用压缩,经查证,官方中文文档上确实说的是关闭所有的代理结果数据的压缩,但是官网的默认值就是off,那岂不是只对nginx上的静态资源进行压缩,这里需要留意一下到底是什么意思】
expired - 启用压缩,如果header头中包含 "Expires" 头信息
no-cache - 启用压缩,如果header头中包含 "Cache-Control:no-cache" 头信息
no-store - 启用压缩,如果header头中包含 "Cache-Control:no-store" 头信息
private - 启用压缩,如果header头中包含 "Cache-Control:private" 头信息
no_last_modified - 启用压缩,如果header头中不包含 "Last-Modified" 头信息
no_etag - 启用压缩 ,如果header头中不包含 "ETag" 头信息
auth - 启用压缩 , 如果header头中包含 "Authorization" 头信息
any - 无条件启用压缩
gzip_vary on;
一般来说不需要配置,一般是配置给比较老的浏览器使用的,配置上无所谓,只是多出来一个头信息
Vary:Accept-Encoding而已gzip_types text/plain application/x-javascript text/css application/xml;
两个gzip_types任意选一个,针对项目情况选择使用,后面的参数值用空格分隔开,意思是针对哪些mime类型的文档做gzip压缩;text/plain是一般的文本文档、application/x-javascript是针对javascript相关的、text/css针对CSS相关的、application/xml针对xml相关的
gzip_types text/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xml text/javascript application/javascript application/x-javascript text/x-json application/json application/x-web-app-manifest+json text/css text/plain text/x-component font/opentype application/x-font-ttf application/vnd.ms-fontobject image/x-icon;
这是比较全的配置了,第一行是和文本文档和xml相关的,第二行是和JavaScript相关的,第三行是和json相关的,第四行时css以及文本文档相关的,第五行是对字体相关的【服务器可能会向浏览器下发一些字体来展示响应页面的效果】,第六行是对图标做压缩【视频特指网站页面左侧的小图标】
建议是针对自己的系统冗余配置,少配置会导致有些文件不进行压缩了
gzip_disable "MSIE [1-6].(?!.*SV1)";
这个参数表示针对哪些浏览器关闭gzip这个功能,这个也是默认配置,针对IE6版本以下的浏览器就关闭Gzip功能,建议这个参数不要配置,因为每个请求差不多都会检验gzip,而这个参数值是正则表达式,都去匹配该正则表达式对服务器的性能消耗是指数级别上升的,正则写的越复杂,性能消耗就越大【包括location中的其他配置,净量不要出现正则表达式,直接最小匹配直接匹配上,千万尽量少用正则,很影响性能】
配置Gzip压缩
【未开启Gzip情况下的效果】
gzip能在请求报文的ResponseHeader信息中体现出来,未开启gzip情况下的请求头信息
Content-Length表示当前页面一共有多大,这里是7832个字节
【nginx中配置gzip】
xxxxxxxxxxserver {listen 80;server_name localhost;location / {gzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 256;gzip_proxied any;gzip_vary on;gzip_types text/plain application/x-javascript text/css application/xml;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";#配置示例proxy_http_version 1.1;proxy_set_header Connection "";proxy_set_header X-Forwarded-For $remote_addr;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}【配置gzip后的访问效果】
多出来三个响应头信息,
Content-Encoding:gzip:当前页面内容压缩的格式是gzipTransfer-Encoding:chunked:传输的压缩格式,chunked表示将数据包以一个一个的包的形式发送给客户端,每个包发送过来单独的解压缩,直到最后一个大小为0的包表示数据传输完成;这个参数就是替代之前数据大小的作用,没有数据大小信息的情况下需要判断数据传输完成的标志,该参数由nginx生成响应头时写入,但是nginx生成响应头的同时响应数据还没有准备好【异步响应式操作】,此时还不知道压缩数据到底有多大,先把头信息准备好以后再去请求上游服务器读数据,最后将头信息和响应体合并一起发给客户端【有些文件比较大压缩比较慢,先把头信息发送给nginx先进行处理】Vary:Accept-Encoding:该参数由配置gzip_vary on;添加的头信息,一般来说不需要配置,一般是配置给比较老的浏览器使用的,配置上无所谓,只是多出来一个头信息而已少了原来的内容大小信息
【chrome浏览器的一些参数】
Accepted Content:可接受的内容压缩格式,取消浏览器默认设置可以选择不支持下列三种内容压缩算法【deflate压缩算法最早出现在apache httpd上,现在使用nginx基本上看不到这种压缩算法,默认是三种都支持】,不支持某种压缩算法,但是服务器上没有原件,服务器会直接返回404
Network throtting:该选项卡可以模拟不同的网络情况,可以选择3G网络【访问请求响应到页面上的速度会明显变慢】,还可以直接选择offline让浏览器离线
Gzip静态压缩
Gzip静态压缩可以看做动态压缩的一个扩展功能,Gzip静态压缩就完美解决了动态压缩无法使用sendfile功能的问题,原理是预先将静态文件打包成一个压缩包,动态压缩指去磁盘上找一个文件,文件找到后用Gzip压缩,压缩完以后发送给客户端;静态压缩指磁盘上有一个文件,该文件还配置了一个对应的压缩包【如index.html,此外还有一个index.html.gz,这是提前用gzip方式压缩好的压缩包】,Gzip静态压缩开启后会优先去读取gz文件,读取到直接就用sendfile的方式发送给客户端,而不再进行压缩的操作【理解成不压缩就可以使用sendfile】,压缩文件就是linux上的哪个压缩命令,还可以使用命令
gzip -9 example.txt设置对应的压缩等级为9因为sendfile针对的是nginx上的资源,一般nginx都作为静态资源前置服务器,上面一般都是静态资源,静态压缩功能是在动态压缩功能基础上开启的【一般这种权限都掌控在架构师和技术经理手上,有天全权接手项目就能考虑这个事情了】
官方文档上Gzip相关的模块:
ngx_http_gzip_module:动态Gzip压缩模块;ngx_http_gzip_static_module:Gzip静态压缩模块;静态压缩模块默认情况下没在预编译的包中,需要手动添加--with-http_gzip_static_module参数到./configure命令下
为反向代理服务器131安装静态Gzip压缩模块
使用命令
./configure --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module在nginx的解压目录下进行预编译配置经过测试没问题,内置模块用with,外置模块用add
没有报错使用make命令进行安装
不要用make install,make install执行原来的nginx会被重置
停止nginx的运行,使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old2,使用命令cp nginx /usr/local/nginx/sbin/将objs/nginx.sh复制到nginx的sbin目录
Gzip静态压缩的参数配置
gzip_static on|off|always,作用域还是http,server,location配置成on会去检查客户端是否支持gzip,如果客户端不支持gzip,就不会去给客户端发送gzip这个压缩包了,用户支持gzip就发送gzip文件,不支持就去找原文件,如果找不到原件就会直接报404;off相当于直接把gzip这个模块给直接关闭了;always是不管客户端是否支持gzip,都将gzip压缩包发送给客户端【此时如果客户端不支持gzip,压缩包就解不开,此时还需要配合另外一个模块
ngx_http_gunzip_moudle来进行使用,该模块也不在预编译的包下,需要手动添加--with-http_gunzip_moudle参数到./configure命令下【./configure --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module】,该模块的作用是发送数据给客户端前将压缩包给解压开,有这个就可以把磁盘上的所有原文件删除,只保留压缩文件,任何时候都不需要专门去访问原文件】Gzip静态压缩模块和gunzip模块配合可以实现当用户可以使用gzip的方式就直接访问压缩包,如果用户不支持gzip就在数据响应给用户前在nginx中奖压缩包解压缩为原文件再响应给客户端;大多数情况下不需要这个配置,基本上浏览器都支持gzip,gunzip模块大多数情况下都是用来节省磁盘空间的,注意
gzip_static on在使用gunzip的时候一般是没有原文件的,对于不支持gzip的客户端,使用gzip_static on会导致nginx去找原文件,找不到直接报404;不会再去用gunzip模块解压得到原文件并响应给用户,需要将该参数配置成gzip_static always,找不找的到原件都必须给客户端发送压缩包,发送压缩包发现用户不支持解gzip解压缩就在服务器使用gunzip解压缩,而且此时响应头中也不会有gzip的信息,显示内容是text/html类型,但是传输编码还是显示的chunked,没有显示响应内容的大小【原因还是磁盘上本身没有对应的原文件,需要解压缩,没有对应的原文件大小信息】
总体的配置演示
开启动态压缩和静态压缩的配置
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65 65;keepalive_time 1h;keepalive_requests 1000;send_timeout 60;upstream stickytest{keepalive 100;keepalive_requests 1000;keepalive_timeout 65;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {gunzip on;gzip_static on;gzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 256;gzip_proxied any;gzip_vary on;gzip_types text/plain application/x-javascript text/css application/xml;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";#配置示例proxy_http_version 1.1;proxy_set_header Connection "";proxy_set_header X-Forwarded-For $remote_addr;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}
gunzip模块的参数配置
作用域同样
http,server,location
gunzip on|off:开启或者关闭gunzip模块的功能gunzip_buffers number size:内存缓冲区大小,number是内存缓冲块个数,size是每个内存缓冲块大小;默认值32位操作系统和CPU默认配置成32个4k的内存缓冲区,64位默认配置成16个8k的内存缓冲区
静态压缩的使用场景
图片和音视频不适合使用gzip进行压缩,现在看到的视频在传输过程已经经过一层压缩了,现在使用的最多的格式是h264的格式,服务器对视频的处理会先压缩一遍,再次进行压缩处理效果极低,除非提高很高的压缩等级,但是文件又大,压缩和解压过程中CPU的消耗都非常高
图片和音频资源也是经过提前压缩处理的,png、gif、jpg都是已经被压缩过的格式
总结图片、音视频资源本身的格式都是已经被压缩过的格式,再去压缩得到的压缩比不会太高,要把压缩比弄的很高代价特别高昂;比较适合实用gzip的就是访问频次很高的文本文件【html,css,js等】
响应头信息中有gzip也有内容大小信息【Content-length,但是之前有静态压缩还是chunked不知道这个内容长度是怎么实现的】说明访问站点使用了静态压缩的方式,资源文件都是经过预压缩的,传输快,节省资源
nginx服务器做为cdn服务器的上游服务器【数据存储服务器】,把数据文件全部压缩【使用linux上的压缩命令
gzip -r my_directory可以递归压缩整个目录的文件】极为高频被访问到的页面或者一些CSS、JS静态资源文件可以提前压缩使用静态压缩的方式,
第三方Brotli压缩
Brotli是google搞出来的,其性能远高于gzip,也有大量站点使用这种压缩方式,但是使用这种方式必须在https协议下,默认情况下浏览器没有
accept-encoding:br这个头信息,该压缩算法效率高是因为内置了大概一万多个字典文件,这些字典文件包含的都是常见的html、css、js文件文本,比如对标签进行归类,生成序号字典文件代替这些标签,就可以用序号代替标签进行压缩和解压缩,尤其对文本文档的压缩效率极高,Brotli的压缩效率比Gzip大概高20%左右这个Brotli第三方压缩模块和Gzip可以在nginx中共存,浏览器支持Brotli的话会优先使用brotli,浏览器不支持就会降级使用gzip
Brotli官网:https://github.com/google/ngx_brotli
安装Brotli
安装步骤
安装ngx_brotli和brotli稍微麻烦一点,因为有子项目依赖
从下载地址
https://github.com/google/ngx_brotli下载brolti在nginx上的插件ngx_brotlingx_brotli下载地址有文档,配置使用官方推荐的动态模块的方式,动态加载模块是nginx在1.9版本以后才支持的,禁用模块无需重新进行编译,直接在配置文件中进行配置要使用的模块就可以直接使用了【就是安装是安装,需要使用要在配置文件进行配置,不配置对应的模块就会禁用】
ngx_brotli下载点击release下载,只能下载到源码,需要自己在本地进行编译和安装;或者从git直接拉取到本地进行编译和安装;稳定版本现在只有1.0.0,linux系统下载tar.gz版本
从下载地址
https://codeload.github.com/google/brotli/tar.gz/refs/tags/v1.0.9下载brotli单独的算法仓库地址:https://github.com/google/brotli,也可以直接从对应仓库的release下载tar.gz的源码压缩包
使用命令
tar -zxvf ngx_brotli-1.0.0rc.tar.gz解压ngx_brotli的压缩包使用命令
tar -zxvf brotli-1.0.9.tar.gz解压brolti的压缩包进入brolti的解压目录,使用命令
mv ./* /opt/nginx/ngx_brotli-1.0.0rc/deps/brotli将brotli算法的压缩包移动到ngx_brotli解压目录下的ngx_brotli-1.0.0rc/deps/brolti目录【注意不要把解压目录brotli-1.0.9也拷贝过去了,只拷贝该目录下的文件,目录层级不对预编译检查会报错】在nginx的解压目录使用命令
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module以动态化模块的方式【传统的方式模块无法禁用模块】对ngx_brolti进行编译,传统的编译可以在./configure中使用--add-dynamic-module=brotli目录在nginx的解压目录使用命令
make进行编译没报错就是成功的,上述步骤经测试没问题
使用命令
mkdir /usr/local/nginx/modules在nginx安装目录下创建一个modules模块专门来放置第三方模块,默认是没有的在
nginx解压目录进入objs目录,使用命令cp ngx_http_brotli_filter_module.so /usr/local/nginx/modules/以及cp ngx_http_brotli_static_module.so /usr/local/nginx/modules/将模块ngx_http_brotli_filter_module.so和ngx_http_brotli_static_module.so拷贝到nginx安装目录的modules目录下,以后就可以在nginx配置文件动态的加载brotli模块了停止nginx的运行,使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old3,使用命令cp nginx /usr/local/nginx/sbin/将objs/nginx.sh复制到nginx的sbin目录只要进行了编译就要将新的主程序nginx拷贝到nginx的安装目录,否则即使之前的步骤都没问题模块也是用不了的
每次预编译都要带上之前添加的完整的模块,否则可能由于对某些模块有配置但是没有安装相应的模块,会导致服务启动不起来
可以在拷贝完成后再重启nginx服务
在
nginx.conf配置文件中的最外层【与worker_processes同一层】添加以下配置开启Brolti的相关模块xxxxxxxxxxload_module "/usr/local/nginx/modules/ngx_http_brotli_filter_module.so";load_module "/usr/local/nginx/modules/ngx_http_brotli_static_module.so";
配置Brolti
Brolti的配置和Gzip很像,
配置参数详解
brotli_static参数值:
brotli_static on|off|always默认值:
off作用域:
http,server,location
静态压缩功能配置
属性值为on,会优先去查找以br为后缀的文件,如果找不到br为后缀的文件就去查找原文件;
属性值为always,压根就不读取原文件,和gzip的静态压缩是一样的,不支持也会返回压缩包【那自动降级gzip和这个冲突吗】;
属性值为off,表示不使用brotli进行静态压缩
brotli参数值:
brotli on|off默认值:
off作用域:
http,server,location,if
是否使用brolti对响应文件进行动态压缩
brotli_types参数值:
brotli_types <mime_type> [..]默认值:
text/html作用域:
http,server,location
指定需要brolti压缩的MIME类型,
*表示匹配任意响应的MIME类型,文本类型压缩效果特别好,对图片、音视频的压缩效果没什么作用【压缩效果好是因为brolti有强大的内置字典】brotli_buffers参数值:
brotli_buffers <number> <size>默认值:
32 4k|16 8k作用域:
http,server,location
进行压缩的内存缓冲区,和gzip是一样的,默认32位系统是32个4k内存缓冲块,64位系统是16个8k内存缓冲块,但是官方文档显示已经过时可忽略Deprecated, ignored.
brotli_comp_level参数值:
brotli_comp_level <level>默认值:
6作用域:
http,server,location
压缩等级,默认第6级,和gzip不一样的是一共有11级【1-11】
brotli_window参数值:
brotli_window <size>默认值:
512k作用域:
http,server,location
窗口值是压缩软件中通用的一个概念,相当于用来摆放数据的桌子,桌子越大,相同的标志性数据查找效率越高,也不是设置的越大越好,因为比较占用内存,默认情况下是512k,可以以2的倍数进行设置
brotli_min_length参数值:
brotli_min_length <length>默认值:
20作用域:
http,server,location
设置响应会被压缩的最小长度,响应体的长度取响应头中的
Content-Length属性值
Brotli和Gzip完整配置演示
Gzip和Brolti是完全可以共存的,两者的配置完全没有冲突
注意Chrome浏览器默认情况下没有开启对br压缩格式的支持的【http协议没有对br相应的头信息的支持,可以使用curl自定义头信息发送http请求来使用br】,只有在https下才支持br【需要https服务器客户端才能发送https的URL】
课堂演示表明浏览器不支持br格式会自动使用gzip来响应请求
xxxxxxxxxx#只有使用新编译完的nginx主程序才能支持加载这些模块,否则也是不认识的load_module "/usr/local/nginx/modules/ngx_http_brotli_filter_module.so";load_module "/usr/local/nginx/modules/ngx_http_brotli_static_module.so";worker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65 65;keepalive_time 1h;keepalive_requests 1000;send_timeout 60;upstream stickytest{keepalive 100;keepalive_requests 1000;keepalive_timeout 65;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {#gzip和gunzip配置gunzip on;gzip_static on;gzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 256;gzip_proxied any;gzip_vary on;gzip_types text/plain application/x-javascript text/css application/xml;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";#Brolti配置brotli on;brotli_static on;brotli_comp_level 6;brotli_buffers 16 8k;brotli_min_length 20;brotli_types text/plain text/css text/javascript application/javascript text/xml application/xml application/xml+rss application/json image/jpeg image/gif image/png;#配置示例proxy_http_version 1.1;proxy_set_header Connection "";proxy_set_header X-Forwarded-For $remote_addr;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【效果演示】
浏览器使用http协议不能添加支持br的头信息,必须https协议才能使用支持br的头信息,这里为了方便,直接使用命令
curl -H 'accept-encoding:br' -I http://192.168.200.131自定义头信息为br来让服务器自动使用br的压缩方式来压缩传输数据【感觉课上说的启用静态压缩会自动停用动态压缩的知识是错误的,这里配置文件开启了静态压缩功能,客户端根本没有br为后缀的文件,返回的响应头中还是br,感觉理解成静态压缩和动态压缩同时开启,浏览器不支持br就自动使用gzip;不确定这儿,因为开启了gzip的动态压缩,浏览器也支持gzip,但是返回的是上游服务器的原件,可能是没到压缩阈值,测试了一下确实是没到阈值,爷屌不屌;这里没问题,就按之前的理解,遇到了再修正】
合并请求
请求一个主页,会因为引用发情N多个请求,请求类型分为文本类:js、css;多媒体类型:png;
可以使用Concat模块把客户端发起的多个CSS资源请求、js资源请求合并成一个请求,目的是为了减少并发请求,让服务器可以承载更高的并发量
原理是前端发起请求的连接不能像以前一样每个文本资源文件都写一个herf,而要采用类似于定义接口形式,将要请求的静态资源文本文件的对应标志以参数的形式拼接在uri的后面发送给服务器,服务器解析请求的参数,读取对应的资源,并将这些资源合并之后以一个文件的形式响应给客户端【这里目前演示的是同一种后缀的文件合并在一起,衍生出一个问题,为什么不把这些相同类型的文件如css全部写成一个文件一次请求一次响应呢?给出的解释是在研发阶段如果只写成一个css文件会特别地麻烦,情况变得错综复杂,因此选择牺牲一些性能,在响应的时候将这些css等文本文件使用合并操作成一个文件响应给客户端,弹幕补充:主要原因是你不拆分文件,那就无法实现按需引入,所以每次请求的css都会有冗余的,没有使用的信息,单个文件太大就会影响响应速度,页面渲染,所以就要拆分在这个过程中内存中会存在这些文件的内容,即内核态到用户态的复制,这种情况下sendfile也是无法使用的】,消耗计算性能减少并发请求数量;很多的大型网站都在使用这个技术,且Concat模块就是淘宝研发出来的
【请求合并示意图】
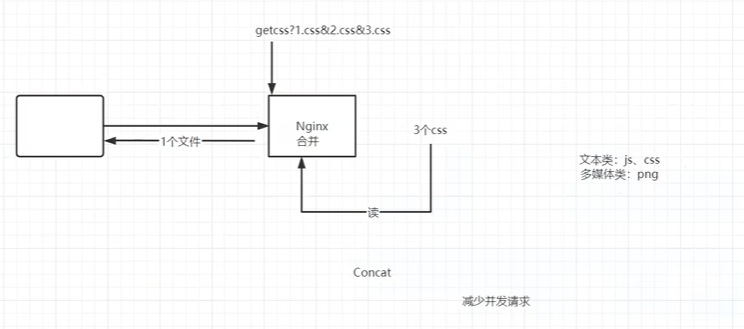
淘宝的请求合并实例
这也不是减少高并发请求的唯一方式,只是一种,还可以利用浏览器缓存来减少并发请求的数量,以后会讲
css和js文件的请求都能合并,凡是淘宝页面有两个问号的开头的css和js请求都走了concat模块【这是Concat的规范】
做架构师最初就是从现有成功的项目中学习人家是怎么做的,因为别人有这么大的并发量,有试验场景;不知名项目可能根本就没有经过如此大高并发请求的访问【亿级流量也就几大家真正经历过】
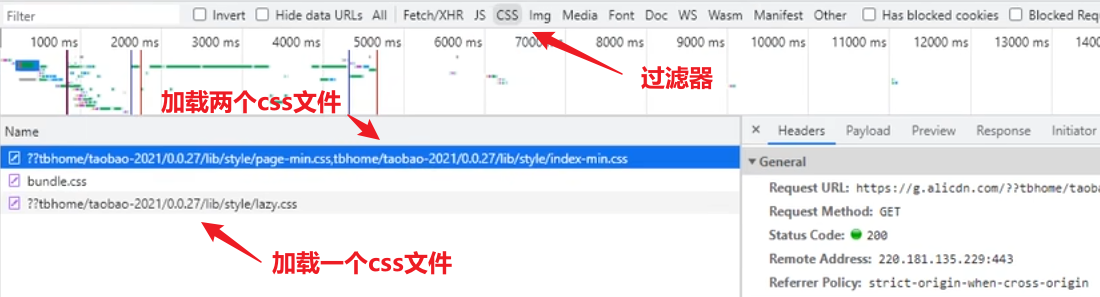
安装Concat模块
官网地址:https://github.com/alibaba/nginx-http-concat
nginx官网对Concat的介绍:https://www.nginx.com/resources/wiki/modules/concat/
Tengine的官网也有介绍,该模块最早是tengine发布的,tengine已经被捐献给apache开源组织,tengine是基于nginx开源版基础上再源码层面做了很多的修改,不只是增加了模块和功能,大部分的tengine的模块直接拿到nginx中是用不了的,但是Concat模块是能直接拿过来使用的,Concat虽然很久没用了,但是比较简单,就一个C源文件,而且release中没有发行版,只能通过git clone进行安装或者点击code通过
download zip将压缩包nginx-http-concat-master.zip下载下来
安装步骤
将压缩包
nginx-http-concat-master.zip拷贝到/opt/nginx目录下这里有个坑,大家用git指令下载的文件是和直接下载的文件是不一样的,git下载的文件名没有-master
xxxxxxxxxx[root@nginx1 nginx]# unzip nginx-http-concat-master.zipArchive: nginx-http-concat-master.zipb8d3e7ec511724a6900ba3915df6b504337891a9creating: nginx-http-concat-master/inflating: nginx-http-concat-master/README.mdinflating: nginx-http-concat-master/configinflating: nginx-http-concat-master/ngx_http_concat_module.c在nginx的解压目录中使用命令
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master进行预编译,然后使用make命令编译这里面为了nginx的课程连续性,添加了很多其他模块,自己根据需要选择,预编译检查的命令不是固定的,对nginx.sh使用命令
./nginx -V能够查看当前nginx的版本,gcc版本和安装的模块xxxxxxxxxx[root@nginx1 objs]# ./nginx -Vnginx version: nginx/1.20.2built by gcc 8.3.1 20190311 (Red Hat 8.3.1-3) (GCC)configure arguments: --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master使用命令
systemctl stop nginx停掉nginx,在/objs目录下使用命令cp nginx /usr/local/nginx/sbin/将编译好的nginx运行文件替换掉老的nginx.sh,然后重启nginx一般来说各个模块包括第三方模块之间不会有冲突性问题
Concat合并文本请求
Concat只能合并文本请求
图片请求也能合并,但是是前端的技术,作为开发需要对这些技术进行了解,比如当前页面有N多图片,图片比较小,以icon【以按钮为代表的简单图表实例】为后缀;还可以把几张图合并成一张大图,在前端展示时使用css样式中的position属性来控制图片展示的范围
【图表合并图】
用css样式中的position属性来切割图片,这种图片合并使用与logo和icon这种,处理高并发较为取巧也常用的方式

Concat配置
Concat只能合并同一台服务器上的css、js文件,如果文件分布在不同的服务器上,concat无法合并这些文件
xxxxxxxxxxlocation / {concat on; #开启concat模块的使用concat_max_files 20; #配置一个请求最多能包含多少个文件,最好不要在一个请求中包含太多的文件}【完整配置】
xxxxxxxxxx#只有使用新编译完的nginx主程序才能支持加载这些模块,否则也是不认识的load_module "/usr/local/nginx/modules/ngx_http_brotli_filter_module.so";load_module "/usr/local/nginx/modules/ngx_http_brotli_static_module.so";worker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65 65;keepalive_time 1h;keepalive_requests 1000;send_timeout 60;upstream stickytest{keepalive 100;keepalive_requests 1000;keepalive_timeout 65;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {#concat的配置concat on; #开启concat模块的使用concat_max_files 20; #配置一个请求最多能包含多少个文件,最好不要在一个请求中包含太多的文件#gzip和gunzip配置gunzip on;gzip_static on;gzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 256;gzip_proxied any;gzip_vary on;gzip_types text/plain application/x-javascript text/css application/xml;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";#Brolti配置brotli on;brotli_static on;brotli_comp_level 6;brotli_buffers 16 8k;brotli_min_length 20;brotli_types text/plain text/css text/javascript application/javascript text/xml application/xml application/xml+rss application/json image/jpeg image/gif image/png;#配置示例proxy_http_version 1.1;proxy_set_header Connection "";proxy_set_header X-Forwarded-For $remote_addr;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}配置上游服务器tomcat的欢迎页
【给页面添加样式】
h最多到h6生效 ,把css文件的背景和字体颜色拆分两个css文件,在主文件中对两个css文件进行引用
xxxxxxxxxx<html><head><meta charset="utf-8"><title>tomcat</title></head><body><h1>welcome to tomcat!I'm 192.168.200.135</h1><h2>welcome to tomcat!I'm 192.168.200.135</h2><h3>welcome to tomcat!I'm 192.168.200.135</h3><h4>welcome to tomcat!I'm 192.168.200.135</h4><h5>welcome to tomcat!I'm 192.168.200.135</h5><h6>welcome to tomcat!I'm 192.168.200.135</h6><h7>welcome to tomcat!I'm 192.168.200.135</h7><h8>welcome to tomcat!I'm 192.168.200.135</h8><h9>welcome to tomcat!I'm 192.168.200.135</h9><h10>welcome to tomcat!I'm 192.168.200.135</h10><h11>welcome to tomcat!I'm 192.168.200.135</h11><h12>welcome to tomcat!I'm 192.168.200.135</h12><h13>welcome to tomcat!I'm 192.168.200.135</h13><h14>welcome to tomcat!I'm 192.168.200.135</h14><h15>welcome to tomcat!I'm 192.168.200.135</h15><h16>welcome to tomcat!I'm 192.168.200.135</h16></body></html><style>body{background-color:#000;color:#fff;}</style>【样式效果】
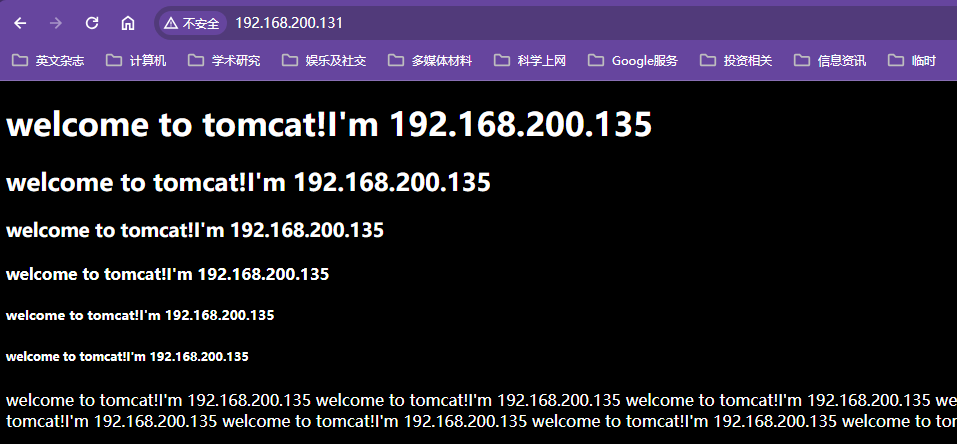
对css样式分别拆成两个文件并在欢迎页中进行引用
【欢迎页】
css文件的根目录就是欢迎页所在的root目录
xxxxxxxxxx<html><head><meta charset="utf-8"><title>tomcat</title><!-- 这个link不一定必须要加在标签内,直接找个标签外的地方写都行,但是外部css样式文件必须要通过link引入 --><link rel="stylesheet" type="text/css" href="font.css"/><link rel="stylesheet" type="text/css" href="page.css"/></head><body><h1>welcome to tomcat!I'm 192.168.200.135</h1><h2>welcome to tomcat!I'm 192.168.200.135</h2><h3>welcome to tomcat!I'm 192.168.200.135</h3><h4>welcome to tomcat!I'm 192.168.200.135</h4><h5>welcome to tomcat!I'm 192.168.200.135</h5><h6>welcome to tomcat!I'm 192.168.200.135</h6><h7>welcome to tomcat!I'm 192.168.200.135</h7><h8>welcome to tomcat!I'm 192.168.200.135</h8><h9>welcome to tomcat!I'm 192.168.200.135</h9><h10>welcome to tomcat!I'm 192.168.200.135</h10><h11>welcome to tomcat!I'm 192.168.200.135</h11><h12>welcome to tomcat!I'm 192.168.200.135</h12><h13>welcome to tomcat!I'm 192.168.200.135</h13><h14>welcome to tomcat!I'm 192.168.200.135</h14><h15>welcome to tomcat!I'm 192.168.200.135</h15><h16>welcome to tomcat!I'm 192.168.200.135</h16></body></html>【font.css】
tomcat的webapps下的root目录
xxxxxxxxxxbody{color:#fff;}【page.css】
xxxxxxxxxxbody{background-color:#000;}【请求效果】
只有清空缓存进行请求的时候才会出现
content-encoding:gzip,浏览器有缓存不会显示content-encoding属性
使用comcat模块,在主页修改href让一个请求获取多个css文件
【主页】
此时服务器端的css文件没有任何变动
xxxxxxxxxx<html><head><meta charset="utf-8"><title>tomcat</title><!-- 这个link不一定必须要加在标签内,直接找个标签外的地方写都行,但是外部css样式文件必须要通过link引入,不需要type属性都行,但是不能没有rel属性 --><!-- 直接在href写对应的请求文件格式就能获取到对应的文件,不知道合并的具体过程,但是返回的应该是同一个文件,只是在服务端多个文件被合并了,浏览器也能解析返回的这个文件 --><link rel="stylesheet" type="text/css" href="??font.css,page.css"/></head><body><h1>welcome to tomcat!I'm 192.168.200.135</h1><h2>welcome to tomcat!I'm 192.168.200.135</h2><h3>welcome to tomcat!I'm 192.168.200.135</h3><h4>welcome to tomcat!I'm 192.168.200.135</h4><h5>welcome to tomcat!I'm 192.168.200.135</h5><h6>welcome to tomcat!I'm 192.168.200.135</h6><h7>welcome to tomcat!I'm 192.168.200.135</h7><h8>welcome to tomcat!I'm 192.168.200.135</h8><h9>welcome to tomcat!I'm 192.168.200.135</h9><h10>welcome to tomcat!I'm 192.168.200.135</h10><h11>welcome to tomcat!I'm 192.168.200.135</h11><h12>welcome to tomcat!I'm 192.168.200.135</h12><h13>welcome to tomcat!I'm 192.168.200.135</h13><h14>welcome to tomcat!I'm 192.168.200.135</h14><h15>welcome to tomcat!I'm 192.168.200.135</h15><h16>welcome to tomcat!I'm 192.168.200.135</h16></body></html>【访问效果】
注意:如果合并请求的css文件不在nginx服务器上,结果响应回来是错误的,并不会实现css的样式效果
请求合并的css文件必须在装了concat模块的nginx服务器上
【合并文件效果】
实际上css文件在tomcat上并没有实现样式效果
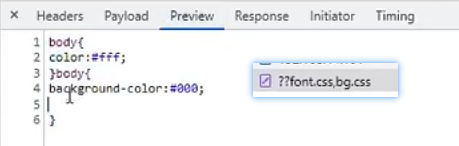
将项目迁移到nginx服务器上的试验效果
此时整个项目都在131nginx服务器上,css样式效果出现了
【只要nginx服务器上有合并请求的css文件,即使内容在tomcat上也能正常响应】
错了走的静态文件的根目录都不一样,即使有css文件也找不到,经过测试,下面这张图是因为走了浏览器缓存的原因,清除缓存再次发送请求就变成没有样式的效果了,所以还是原来的规则,合并请求的css文件、js文件必须在装了concat模块的nginx代理服务器上
资源静态化
资源静态化是处理高并发请求的利器,处理高并发的手段无非就是做缓存、资源静态化、把服务器的节点拉入云用户
资源静态化相当于把原来需要后端处理的响应数据缓存下来,通过缓存的方式极大地减少后端服务器的计算工作
从合并文件输出和集群文件同步讲资源静态化,静态页面资源生成和管理的方案自己查找资料学习
资源静态化的解决方案还有很多,自己学习
资源静态化原理
现在的项目nginx一般都作为反向代理服务器,将用户请求转发到上游服务器做一些计算,比如查看账户余额、登录功能,订外卖,资源静态化在这种系统中非常频繁的出现,尤其是高并发的电商系统,资源静态化能够将原本需要上游服务器计算的内容以文件的形式缓存在nginx代理服务器中,比如外卖的商家列表,这些商家信息并不是每次都去数据库中进行查询的, 这些信息都可以缓存在nginx中,像get请求获取的结果很多都可以进行资源静态化处理【电商系统并发量最高的是商品的详情页,其次是列表页,然后是首页和广告页面】;只有当涉及到列表信息变动时才会涉及到数据一致性的问题;
传统的架构是用户发起请求,经过nginx转发到上游服务器,上游服务器从数据库查询到详情页数据响应给nginx服务器再被响应给客户端;
资源静态化将动态获取的数据转化成静态页面【这种方式特别适合页面中数据只会少量变化的情况】,动态资源转换成静态页面可以通过java中的Themeleaf、JSP、Enjoy、Freemarker、Velocity,模板引擎的工作原理是模仿html标签,将动态查询出的数据以标签的形式写入特殊后缀的文件,这些文件在服务器端会被渲染解析成html页面并以流的形式输出静态页面【out.write()】给客户端,一般的模板引擎都有拦截输出流的作用,可以选择将渲染出来的静态页面输出给客户端还是输出到文件中,通过这种方式就可以直接把一个商品的详情页查出来动态的生成静态页面文件,此时可以直接将生成的这个静态页面文件直接前置到nginx反向代理服务器中,这个过程就叫资源静态化;
下次相同请求直接从nginx取该静态文件即可;并且结合OpenResty可以实现客户端发起请求去请求静态资源如item100.html,此时就可以使用OpenResty对nginx做二次开发,设置如果nginx自身找不到对应的静态资源,OpenResty可以直接连接数据库通过内置的模板引擎跨过【不经过】tomcat服务器直接从数据库把数据读取到OpenResty经过模板引擎渲染后直接响应给客户端并且同时将生成的静态文件直接缓存在nginx服务器本地的磁盘中,下次还有相同请求打到nginx直接一个sendfile就把数据响应过去了,速度极快【小型系统直接使用最早的架构技术也不会有问题,高并发系统下这是非常大的一个优化点,能极大地提高系统的效率,也有很多现成的组件和开源项目都可以使用】
高并发的系统架构还会引入更多的技术,现在讲的只是冰山一角
同时,nginx代理服务器一般还是高可用的配置,会配置多台nginx,此时还会涉及到多台nginx反向代理服务器上静态资源同步的问题【因为一个nginx服务器中生成了新的静态资源文件但是别的nginx服务器上没有,客户端请求也会出现问题,再请求缓存一次消耗也不是特别大,会不会是其他的原因呢】,同步操作可以通过额外一些手段实现【比如在linux上有一款非常好用的工具叫rsync,这个工具就能将一台nginx上的文件同步到另外一台nginx服务器上,此时就可以专门在一台nginx服务器上生成静态资源文件然后同步给其他nginx服务器,为了系统的稳定性和高效,一般把这个用于生成静态资源的nginx服务器独立出来,不再进行代理请求和响应资源的工作,而是专门负责生成静态资源然后同步给其他nginx服务器,让客户端去请求其他的nginx服务器】
【资源静态化架构图】
这个图比较随意,只讲了个大概
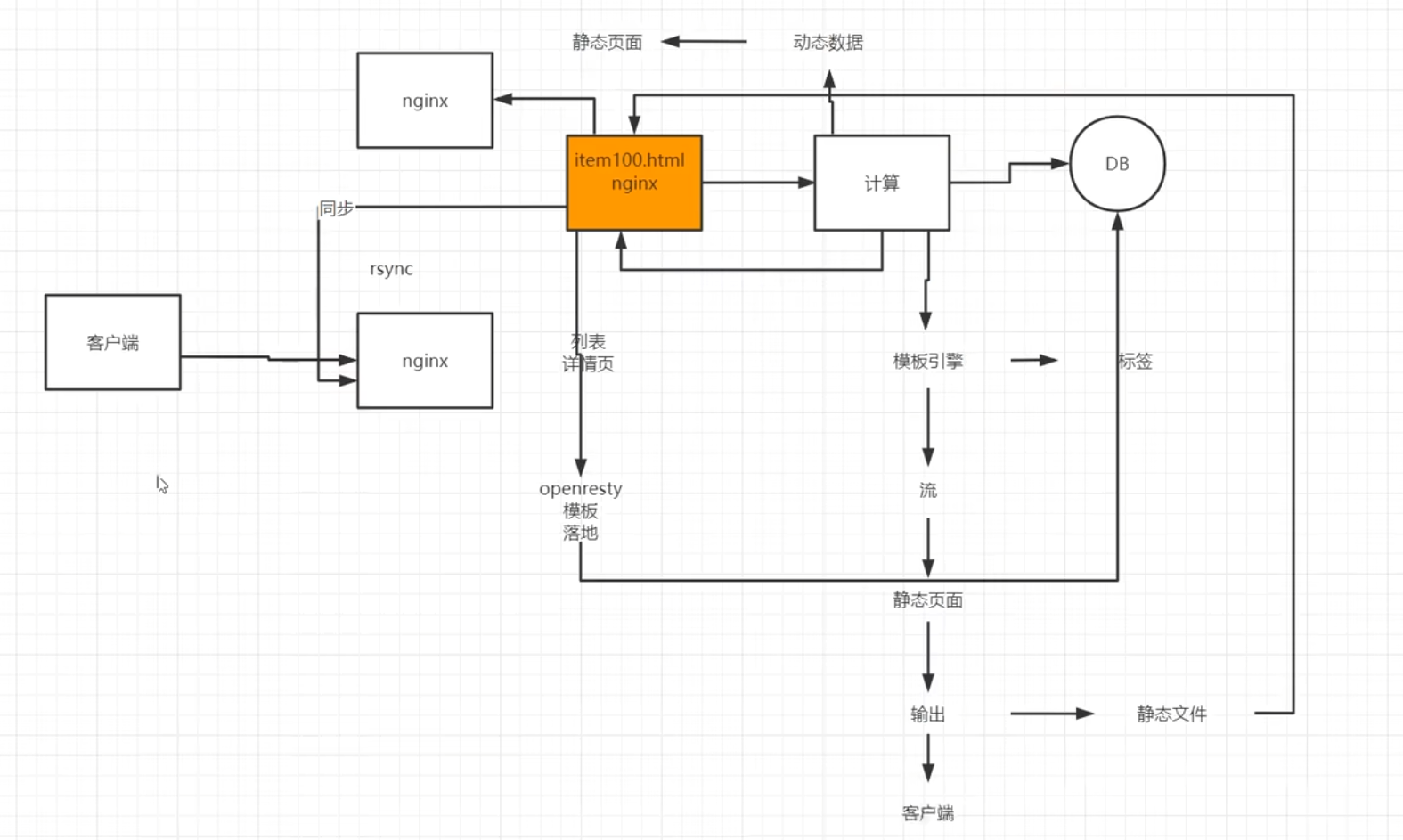
一个静态页面包含的几个部分
页面内容【商品详情介绍】
像价格这种容易变化的内容一般都不生成在静态页面中,或者时常变化的数据都不放在静态页面中,以异步请求的方式【页面渲染前进行请求,或者js来发起异步请求】将这些资源加载进来参与最终页面的生成,比如我的购物车也经常变化,也不能直接生成静态资源,像京东这种网站的首页【首页对每个人的推荐肯定不一样】,可以只生成一个骨架,再配合CDN、异步加载来展现整个效果;原则上就是不要把动态变化的数据和资源直接生成在静态页面中
容易变化的数据和静态资源之间的区别也是一种一致性问题,多个nginx服务器之间的静态资源同步也是一种一致性问题
如果动态的数据必须写入静态资源页面,此时和一致性问题无法避开,可以使用两步提交的方式来解决这个问题,【这里举例举的不好,意会一下,就是用户展示的还是静态页面的价格,但是一旦涉及到使用该数据进行操作比如结算时,一定要再次请求数据库对数据进行验证和更新,即展示数据用老数据,但是涉及到使用数据进行更改操作时需要查询验证更新数据,还有其他方案,以后再学习】,我有个问题,课上没讲,这种展示老数据的行为不会影响到业务吗?客户对这种行为肯定有意见啊
关联的内容【比如广告或者商品推荐,没法做成静态的,这部分需要进行动态的请求,还有点击操作发送的异步请求】
固定页面【固定共用的页面头和页面尾,没必要每个页面都生成一份,这样资源消耗大而且一旦发生修改波及面特别广,比如@CopyRight2023更新成@CopyRight2024,如果每个页面一份,那波及面就特别广了,此时一般都单独抽取出来作为独立的静态页面】
把固定共用的部分和其他两个页面内容组合合并的方法一般有两个:
前端合并:比如用js的innerHtml把另外一个资源给包含进来,使用iframe或者html的方式来合并【谷粒学院的default.vue】,这种方式节约服务器端的计算资源,但是消耗请求数【请求数举例说的是前端有5个iframe,就会额外再向服务器发起五次请求,但是之前的谷粒学院不是这样的,谷粒学院是使用一个独立的头和脚页面拼接的】
后端合并:通过nginx,将固定共用的资源和其他两个内容直接在服务器合并好【有点像concat,该技术叫SSI,可以合并静态页面,SSI是nginx的官方模块,和Concat模块没有关系】
合并文件输出
nginx自带的合并静态资源的模块为Module ngx_http_ssi_module
SSI模块配置参数
ssi参数值:
ssi on|off默认值:
off作用域:
http,server,location,if in location
开启nginx的ssi模块功能,
if in location指的是可以在location作用域的if逻辑判断中使用ssi_last_modified参数值:
ssi_last_modified on|off默认值:
off作用域:
http,server,location
将该属性设置为on会让合并的新文件的最后修改时间为主文件【非使用标签参与合并的文件】的最后修改时间,即不使用文件合并的时间而使用主文件在磁盘上存储的最后时间,这样是为了在浏览器使用缓存时会去根据文件的最后修改时间为依据去检验服务器上的文件是否发生修改,一旦最后修改的时间不一致,浏览器就会认为缓存已经过时;因此这个last_modified对浏览器缓存至关重要,默认是采用合并文件的当前时间作为响应文件的最后修改时间
ssi_min_file_chunk参数值:
ssi_min_file_chunk size默认值:
1k作用域:
http,server,location
该属性的作用是在合并文件时当文件大小大于设置值1k时可以将合并出来的文件存储在磁盘上,如果不满足大于1k的情况文件就不会存储在磁盘上,文件不存储在磁盘上就不能使用sendfile功能
ssi_silent_errors参数值:
ssi_silent_errors on | off默认值:
off作用域:
http,server,location
该属性配置成on的作用是配置模板引擎SSI在指令出现错误时对指令错误进行隐藏,文件错误不会进行隐藏
错误有两种:一种是模板引擎的语法命令出错,第二种是要合并的文件没有
ssi_types参数值:
ssi_types mime-type默认值:
text/html作用域:
http,server,location
该属性的作用是指定ssi能合并的mime类型,默认是html文件,如果需要合并一些xhtml,xml需要在参数后面声明相应的类型,没有配置示例。自己搜一下;此外
*表示匹配任意MIME类型【0.8.29版本以后支持】ssi_value_length参数值:
ssi_value_length length默认值:
256作用域:
http,server,location
该属性的作用是使用
<!--# include file="top.html"-->这类模板引擎命令【SSI命令】时可以传递参数,ssi_value_length属性限制这些参数的长度大小,不是限制合并文件的大小
SSI模块的语法
这个模块的功能就很像模板引擎了
这些命令在主文件的任意位置都可以使用,不建议将SSI命令设置的过于复杂,过于复杂就变成应用级别的服务器了,做模板的内容填充和渲染会消耗更多的服务器内存和计算资源,更多的时候nginx都去前端抗住流量,将计算分发到上游服务器做;当然也有用nginx做应用服务器的情况,但是SSI模块的业务场景实际生产中是比较单一的,基本上就是做文件引用和合并,更复杂的模版引擎还有其他的解决方案,比如java和PHP都有很多模板引擎,即便是nginx也有更高效强大的模板引擎OpenResty,动态渲染用OpenResty会更多一些
命令一般格式:
<!--# command parameter1=value1 parameter2=value2 ... -->以下的都是命令
<!--# include file="top.html"-->file属性使用的是相对路径,发现
# include file就会去本地磁盘找top.html,使用的是相对路径,会从当前目录开始找,还可以写子目录,也可以写绝对路径;即便静态文件都位于tomcat上也没问题,nginx也能自动从上游服务器获取文件并合并在一起,而且合并的方式是读取top.html的完整内容并在标签处对标签进行替换此外,模板引擎对该标签一般不敏感,可以直接把这个标签写在模板引擎中
block命令语法如下
xxxxxxxxxx<!--# block name="one" -->替代输出的内容<!--# endblock -->block命令是定义一个块,这个块中可以写其他的SSI命令并作为include命令的一部分【stub可以作为include命令中的一部分】,应用实例没说,遇到再补充
讲include命令的时候遇到了,stub一般配合block一起使用,通过stub的属性值找name属性为对应属性值的block标签,block标签中夹住的内容作为include命令执行出问题响应的数据为空或者请求处理过程中错误发生后的替代输出,也可以在block中写其他的SSI命令
【应用举例】
虚拟远程请求出问题,请求结果响应不回来,就用name为one的block替代输出
xxxxxxxxxx<!--# block name="one" --> <!--# endblock --><!--# include virtual="/remote/body.php?argument=value" stub="one" -->config可以设置SSI命令使用过程中用到的参数,应用实例没说,遇到再补充
message默认值是[an error occurred while processing the directive],即该参数的作用是设置SSI命令发生错误时的提示信息,参数类型是字符串
timefmt配置当使用日期相关的函数
strftime()【这个是nginx内部的函数】去输出日期和时间显示的格式,默认值是"%A, %d-%b-%Y %H:%M:%S %Z",%s是将时间以秒的格式进行输出
echo可以通过该命令去输出一些变量值,输出变量时有以下三个参数可供选择
var指定变量的名称,nginx有很多内置的变量,比如请求中的一些值和nginx内部系统的变量,可以拿出来用
encoding编码方式。可能的值包括
none、url和entity。默认值为entity。这个解释不清楚,遇到再补充【w3schools上提到是html的编码方式,默认的html编码方式是entity,相当于直接将文本给输出出来】,w3schools的nginx文档貌似对官网做了补充,mark一下Nginx 伪动态SSI服务器 (w3schools.cn)default命令实例:
<!--# echo var="name" default="no" -->,该命令相当于命令<!--# if expr="$name" --><!--# echo var="name" --><!--#else -->no<!--# endif -->当要去输出一个名为name的参数的参数值,但是发现该参数没有值,此时就使用default中定义的默认值进行输出,默认值的默认值为no,no表示啥都不输出
ifif的功能就有点像模版引擎了,但SSI远远没有模板引擎功能强大,通过 if 命令进行条件控制,if能做的逻辑判断也算比较完整,且 if 命令支持正则判断
判断的参数expr一般是布尔值,一般是通过$取的参数值,实际上引号中写的是正则表达式,高性能服务器中最好少使用正则,判断也少做;正则带指数级别的运算复杂度增加,每次请求都要来一遍,如果正则写不好会特别的消耗性能
【格式总览】
一共有四个标签,三个点表示可以配合其他的SSI命令一起使用,演示中只看到配合echo的情况
xxxxxxxxxx<!--# if expr="..." -->...<!--# elif expr="..." -->...<!--# else -->...<!--# endif --><!--# if expr="..." --><!--# elif expr="..." --><!--# else --><!--# endif -->【比较简单的格式举例】
xxxxxxxxxx<!--这个是如果name属性有值就为true--><!--# if expr="$name" --><!--# if expr="$name = text" --><!--# if expr="$name != text" --><!--# if expr="$name = /text/" --><!--# if expr="$name != /text/" -->【复杂格式举例】
正则表达式和配合echo做输出
xxxxxxxxxx<!--# if expr="$name = /(.+)@(?P<domain>.+)/" --><!--# echo var="1" --><!--# echo var="domain" --><!--# endif -->
include注意发起include virtual请求上游服务器文件的时候可以使用
subrequest_output_buffer_size来设置响应内容的最大长度【1.13.10版本以后,这里老师说的是内存缓冲区的大小,看文档的时候再说吧】<!--# include file="footer.html" -->include file是直接读取磁盘文件并将其合并到使用SSI命令的文件,找的是真实的文件
<!--# include virtual="/remote/body.php?argument=value" -->include file可以取加载虚拟的路径,没讲清楚啥意思,补充了一下可以写上游服务器的地址,或许是根据地址去请求文件吧,remote可以认为是一个location即站点,可以对应一个根目录,请求的uri为
body.php?argument=value,这个过程涉及到模板引擎渲染和异步操作的问题,如果像上游服务器请求数据,数据还没有响应回来,但是模板引擎已经渲染完毕而且已经将数据发送出去了,这是很有可能的;这种情况下会出现问题,此时常常配合wait参数把异步操作变成同步操作,让渲染过程阻塞一下,等请求数据拉回来完以后再进行渲染,避免渲染完结果数据还没返回的情况stubstub一般配合block一起使用,通过stub的属性值找name属性为对应属性值的block标签,block标签中夹住的内容作为include命令执行出问题响应的数据为空或者请求处理过程中错误发生后的替代输出
【应用举例】
xxxxxxxxxx<!--# block name="one" --> <!--# endblock --><!--# include virtual="/remote/body.php?argument=value" stub="one" -->wait<!--# include virtual="/remote/body.php?argument=value" wait="yes" -->当请求上游服务器文件的时候,阻塞渲染过程,让渲染过程变成同步操作,等待请求数据返回set<!--# include virtual="/remote/body.php?argument=value" set="one" -->将set指定的变量写入请求上游服务器的请求参数的参数值value中,来向上游服务器发起动态请求
set设置变量的值,有以下两个属性
var变量名
value给对应变量名的变量赋值的变量值
测试使用ssi模块合并公共页面【头尾文件】与内容页面
在135的tomcat的webapps的root目录下创建以下文件并配合index文件合并成一个文件
top.html
页面头
xxxxxxxxxxtop...<p>bottom.html
页面底
xxxxxxxxxx<p>bottom...index.html
在主页中使用SSI模块的命令对top和bottom页面进行引入
file属性使用的是相对路径,发现
# include file就会去本地磁盘找top.html,使用的是相对路径,会从当前目录开始找,还可以写子目录,也可以写绝对路径xxxxxxxxxx<html><head><meta charset="utf-8"><title>tomcat</title><!----><!--# include file="top.html"--><!-- 这个link不一定必须要加在标签内,直接找个标签外的地方写都行,但是外部css样式文件必须要通过link引入,不需要type属性都行,但是不能没有rel属性 --><!-- 直接在href写对应的请求文件格式就能获取到对应的文件,不知道合并的具体过程,但是返回的应该是同一个文件,只是在服务端多个文件被合并了,浏览器也能解析返回的这个文件 --><link rel="stylesheet" type="text/css" href="??font.css,page.css"/></head><body><h1>welcome to tomcat!I'm 192.168.200.135</h1><h2>welcome to tomcat!I'm 192.168.200.135</h2><h3>welcome to tomcat!I'm 192.168.200.135</h3><h4>welcome to tomcat!I'm 192.168.200.135</h4><h5>welcome to tomcat!I'm 192.168.200.135</h5><h6>welcome to tomcat!I'm 192.168.200.135</h6><!--# include file="bottom.html"--></body></html>测试效果
合并文件即使所有的文件都不在nginx服务器上,都需要从上游服务器获取,文件的合并也没有任何问题
【响应回来的内容】
xxxxxxxxxx<html><head><meta charset="utf-8"><title>tomcat</title><!--html标签在头标签中也能渲染,这里合并文件的标签自动被nginx替换了,所有的文件都来自于上游服务器-->top...<p><!-- 这个link不一定必须要加在标签内,直接找个标签外的地方写都行,但是外部css样式文件必须要通过link引入,不需要type属性都行,但是不能没有rel属性 --><!-- 直接在href写对应的请求文件格式就能获取到对应的文件,不知道合并的具体过程,但是返回的应该是同一个文件,只是在服务端多个文件被合并了,浏览器也能解析返回的这个文件 --><link rel="stylesheet" type="text/css" href="??font.css,page.css"/></head><body><h1>welcome to tomcat!I'm 192.168.200.135</h1><h2>welcome to tomcat!I'm 192.168.200.135</h2><h3>welcome to tomcat!I'm 192.168.200.135</h3><h4>welcome to tomcat!I'm 192.168.200.135</h4><h5>welcome to tomcat!I'm 192.168.200.135</h5><h6>welcome to tomcat!I'm 192.168.200.135</h6><p>bottom...</body></html>
开启
ssi_silent_errors测试合并语法出错和文件找不着的错误提示信息主文件代码
top.html合并是合并语法错误;bottom.html是文件找不着错误
xxxxxxxxxx<html><head><meta charset="utf-8"><title>tomcat</title><!--语法错误include1--><!--# include1 file="top.html"--><!-- 这个link不一定必须要加在标签内,直接找个标签外的地方写都行,但是外部css样式文件必须要通过link引入,不需要type属性都行,但是不能没有rel属性 --><!-- 直接在href写对应的请求文件格式就能获取到对应的文件,不知道合并的具体过程,但是返回的应该是同一个文件,只是在服务端多个文件被合并了,浏览器也能解析返回的这个文件 --><link rel="stylesheet" type="text/css" href="??font.css,page.css"/></head><body><h1>welcome to tomcat!I'm 192.168.200.135</h1><h2>welcome to tomcat!I'm 192.168.200.135</h2><h3>welcome to tomcat!I'm 192.168.200.135</h3><h4>welcome to tomcat!I'm 192.168.200.135</h4><h5>welcome to tomcat!I'm 192.168.200.135</h5><h6>welcome to tomcat!I'm 192.168.200.135</h6><!--没有bottom1.html这个文件--><!--# include file="bottom1.html"--></body></html>未开启
ssi_silent_errors的提示信息
开启
ssi_silent_errors的提示信息的提示信息模板引擎合并时的语法错误导致的错误提示信息直接被隐藏了,但是文件找不到的错误提示还在
上来直接welcome,但是文件找不着404的错误没有被处理,这种错误需要去nginx中进行额外的配置【nginx错误页面的配置,后边讲】
静态文件同步
静态文件同步有很多种方式和工具,rsync是其中一个比较稳定成熟和成型的工具,在生产运维中选用的工具首要就是安全稳定,而不是追求新版本,同步操作的工具也没有什么额外的功能,只是希望将文件分发同步到不同的服务器上,使用rsync工具能够避免再去开发文件同步的过程,因为这里面涉及到比较多的细节,开发起来比较麻烦
文件同步原理
原服务器,生成静态文件并分发给目标服务器;目标服务器获取文件并响应客户请求
原服务器生成静态文件如index.html,此时希望将该文件推送到目标服务器集群中,推送的操作相对容易实现,除了同步外原服务器中的文件删除也需要通知目标服务器删除,但是目标服务器中可能存在原服务器中没有的文件,此时用原服务器来管理目标服务器可能会出现问题;此外还有文件修改以后原服务器还需要根据文件大小和最后修改时间去判断各个服务器中的数据是否更新,如果目标服务器将文件锁死,原服务器即便检测到文件需要更新,数据也写不进去;细节问题很多,开发起来比较麻烦,借助第三方工具可以节省这部分工作
生成文件依靠一套系统java或者OpenResty,生成的文件同步依靠另一套系统;
rsync文件同步需要原服务器和目标服务器都安装rsync,rsync很像spc命令,只是rsync没有在操作系统中自带,scp命令可以找到目标地址,经过授权认证,将文件直接推送到目标地址;但rsync的功能更加强大,可以监控原服务器某个目录下所有文件的变动,如果原服务器只有一个文件发生了变化,通过远程比对就可以实现只推送一个文件到目标服务器,且传输过程中会自动压缩文件,rsync在系统中的作用主要是复制、推送以及比对
在原服务器上一般还有另外一个工具inotify,这个工具是用来监控服务器指定目录下的文件是否发生变化,监控目录中的文件是否存在增删改操作,一旦有变动,由inotify调用rsync来来推送文件到目标地址,整个文件同步过程由inotify和rsync配合完成的
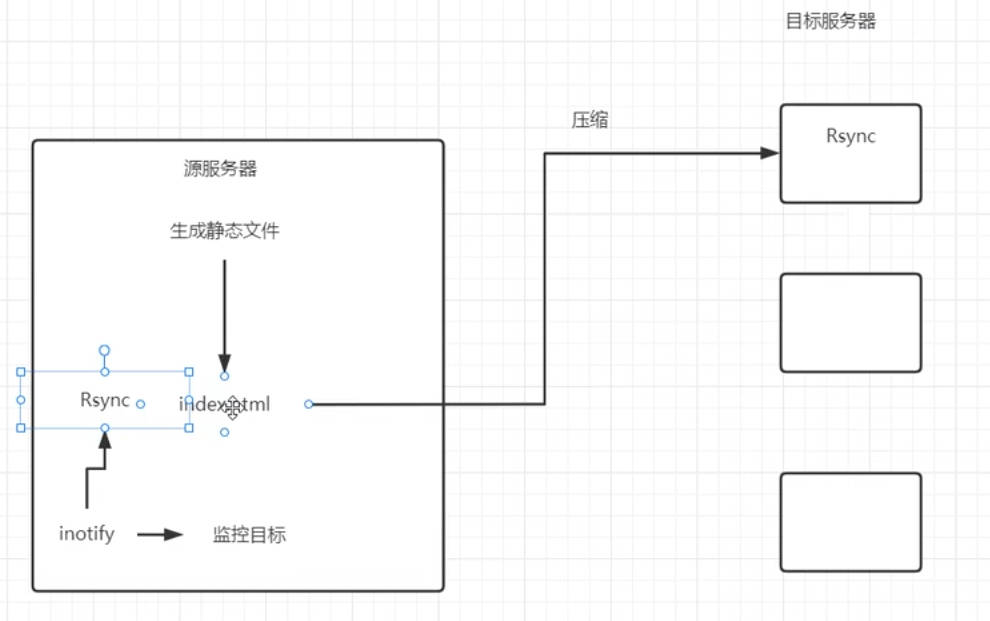
Rsync
rsync【remote synchronize】的官网:https://www.samba.org/ftp/rsync/rsync.html
remote synchronize是一个远程数据同步工具,可通过 LAN/WAN 快速同步多台主机之间的文件。也可以使用 rsync 同步本地硬盘中的不同目录。rsync 是用于替代 rcp 的一个工具,rsync 使用所谓的 rsync算法 进行数据同步,这种算法只传送两个文件的不同部分,而不是每次都整份传送,因此速度相当快。
rsync 基于inotify 开发
安装Rsync
使用命令
yum install -y rsync安装rsync
安装成功测试
配置了源服务器上的
rsyncd.conf,并且两台服务器的rsync都启动后,在目标服务器上使用命令rsync --list-only 192.168.200.131::ftp/查看源服务器上的文件目录是否能显示也可以直接使用
ps -ef|grep rsync查看对应的进程是否存在
Rsync配置
配置Rsync的目标和源
让132服务器实时监控131源服务器的文件变化,一旦文件有变化随时拉取同步
rsync的配置文件的完整文件目录
/etc/rsyncd.conf,初始状态下配置文件中啥也没有,一般简单使用基本配置都不需要改【默认配置文件】
xxxxxxxxxx# /etc/rsyncd: configuration file for rsync daemon mode# See rsyncd.conf man page for more options.# configuration example:# uid = nobody# gid = nobody# use chroot = yes# max connections = 4# pid file = /var/run/rsyncd.pid# exclude = lost+found/# transfer logging = yes# timeout = 900# ignore nonreadable = yes# dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2# ftp指一组资源,path指rsync需要同步的目录,表示一个需要同步的项目# [ftp]# path = /home/ftp# comment = ftp export area【源服务器上的rsync配置】
需要被同步的服务器
xxxxxxxxxx# /etc/rsyncd: configuration file for rsync daemon mode# See rsyncd.conf man page for more options.# configuration example:# uid = nobody# gid = nobody# use chroot = yes# max connections = 4# pid file = /var/run/rsyncd.pid# exclude = lost+found/# transfer logging = yes# timeout = 900# ignore nonreadable = yes# dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2# ftp指一组资源,path指rsync需要同步的目录,表示一个需要同步的项目[ftp]path = /usr/local/nginx/html# comment = ftp export area使用命令
rsync --daemon启动源服务器的rsync,使用命令ps -ef | grep rsync可以查看rsync的运行状态rsync的运行需要源和目标服务器的rsync都进行启动
使用命令
rsync --list-only 192.168.200.131::ftp/在目标服务器上查看源服务器上同步目录的文件🔎ftp就是源服务器上的rsync配置文件中的默认配置组ftp
xxxxxxxxxx[root@nginx2 ~]# rsync --list-only 192.168.200.131::ftp/drwxr-xr-x 107 2023/12/28 21:18:27 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 14 2023/12/28 21:18:27 bottom.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.html使用命令
ll /usr/local/nginx/html/查看目标服务器的本地文件状况注意此时目标服务器的rsync还没有启动
xxxxxxxxxx[root@nginx2 ~]# ll /usr/local/nginx/html/总用量 8-rw-r--r--. 1 root root 494 11月 16 08:39 50x.html-rw-r--r--. 1 root root 491 12月 20 19:29 index.html在目标服务器上使用命令
rsync -avz 192.168.200.131::ftp/ /usr/local/nginx/html/对源服务器的同步目录进行同步,将文件同步到指定目录/usr/local/nginx/html/,只使用命令rsync -avz 192.168.200.131::ftp/只会显示正在接收文件,但是找不到对应的文件同步以后指定目录的文件和远程服务器的对应目录基本一样,连最后修改时间都一样
xxxxxxxxxx[root@nginx2 ~]# rsync -avz 192.168.200.131::ftp/receiving incremental file listdrwxr-xr-x 107 2023/12/28 21:18:27 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 14 2023/12/28 21:18:27 bottom.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.htmlsent 20 bytes received 182 bytes 404.00 bytes/sectotal size is 1,698 speedup is 8.41[root@nginx2 ~]# ll /usr/local/nginx/html/总用量 8-rw-r--r--. 1 root root 494 11月 16 08:39 50x.html-rw-r--r--. 1 root root 491 12月 20 19:29 index.html[root@nginx2 ~]# rsync -avz 192.168.200.131::ftp/ /usr/local/nginx/html/receiving incremental file list./bottom.htmlfont.cssindex.htmlpage.csstop.htmlsent 128 bytes received 1,064 bytes 2,384.00 bytes/sectotal size is 1,698 speedup is 1.42[root@nginx2 ~]# ll /usr/local/nginx/html总用量 24-rw-r--r--. 1 root root 494 11月 16 08:39 50x.html-rw-r--r--. 1 root root 14 12月 28 21:18 bottom.html-rw-r--r--. 1 root root 25 12月 28 21:18 font.css-rw-r--r--. 1 root root 1117 12月 28 21:18 index.html-rw-r--r--. 1 root root 37 12月 28 21:18 page.css-rw-r--r--. 1 root root 11 12月 28 21:18 top.html
同步安全认证
在源服务器上增加安全认证,让服务器更加安全
这个操作让目标服务器在同步的同时需要输入用户名和存储在源服务器上的对应密码
使用命令
echo "earl:123456" >> /etc/rsyncd.pwd将文本"earl:123456"输出到文件
/etc/rsyncd.pwd中,这是创建一个安全认证文件,earl为账号、123456为密码在源服务器上rsync的配置文件
/etc/rsyncd.conf添加安全认证🔎每次重新加载rsync需要重启rsync,rsync是没有重启命令的,rsync的重启需要杀掉rsync的进程,然后再使用命令
rsync --deamon重启xxxxxxxxxx# /etc/rsyncd: configuration file for rsync daemon mode# See rsyncd.conf man page for more options.# configuration example:# uid = nobody# gid = nobody# use chroot = yes# max connections = 4# pid file = /var/run/rsyncd.pid# exclude = lost+found/# transfer logging = yes# timeout = 900# ignore nonreadable = yes# dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2#配置rsync的安全认证,意思是每次目标服务器发起同步请求都需要输入密码,设置用户名为earl,在安全认证文件中其对应的密码是123456auth users = earlsecrets file = /etc/rsyncd.pwd# ftp指一组资源,path指rsync需要同步的目录,表示一个需要同步的项目[ftp]path = /usr/local/nginx/html# comment = ftp export area在目标服务器上使用命令
rsync -avz 192.168.200.131::ftp/ /usr/local/nginx/html/向源服务器发起同步请求,观察此时的运行状态🔎此时发现发起同步请求需要输入密码,即便输入了密码还是提示错误,这是因为源服务器使用了安全认证文件的同时需要将安全认证文件的权限修改的低一点
xxxxxxxxxx[root@nginx2 ~]# rsync -avz 192.168.200.131::ftp/ /usr/local/nginx/html/Password:@ERROR: auth failed on module ftprsync error: error starting client-server protocol (code 5) at main.c(1656) [Receiver=3.1.2]在源服务器上使用命令
chmod 600 /etc/rsyncd.pwd给安全认证文件降低权限,降低权限后重启源服务器rsync💡其实这个权限太高源服务器在使用命令
rsync --daemon后台启动的时候是爆了错的,但是后台运行不会把报错信息显示出来,这个不像nginx配置文件有一点问题服务根本起不来,这个配置文件有问题报错也能起来,但是同步的时候会报错【初始权限】
xxxxxxxxxx[root@nginx1 etc]# ll | grep rsync-rw-r--r--. 1 root root 516 12月 30 16:35 rsyncd.conf-rw-r--r--. 1 root root 12 12月 30 16:36 rsyncd.pwd【修改后的权限】
xxxxxxxxxx[root@nginx1 etc]# ll |grep rsyncd-rw-r--r--. 1 root root 516 12月 30 16:35 rsyncd.conf-rw-------. 1 root root 12 12月 30 16:36 rsyncd.pwd在目标服务器上使用命令
rsync -avz 192.168.200.131::ftp/ /usr/local/nginx/html/再次向源服务器发起同步请求🔎仍然报错,原因是当源服务器开启安全认证后需要在发起同步请求时输入对应密码的用户名
xxxxxxxxxx[root@nginx2 ~]# rsync -avz 192.168.200.131::ftp/ /usr/local/nginx/html/Password:@ERROR: auth failed on module ftprsync error: error starting client-server protocol (code 5) at main.c(1656) [Receiver=3.1.2]在目标服务器上使用命令
rsync -avz earl@192.168.200.131::ftp/ /usr/local/nginx/html/再次向源服务器发起同步请求🔎可以看见命令
rsync -avz earl@192.168.200.131::ftp/ /usr/local/nginx/html/只会显示本次同步发生了修改操作的文件,命令rsync -avz earl@192.168.200.131::ftp/会显示源服务器中对应目录下的所有文件但不会进行同步操作xxxxxxxxxx[root@nginx2 ~]# rsync -avz earl@192.168.200.131::ftp/ /usr/local/nginx/html/Password:receiving incremental file listsent 20 bytes received 182 bytes 44.89 bytes/sectotal size is 1,698 speedup is 8.41[root@nginx2 ~]# rsync -avz earl@192.168.200.131::ftp/Password:receiving incremental file listdrwxr-xr-x 107 2023/12/28 21:18:27 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 14 2023/12/28 21:18:27 bottom.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.htmlsent 20 bytes received 182 bytes 57.71 bytes/sectotal size is 1,698 speedup is 8.41
免密登录
📜使用SSH做SCP的时候可以做免密钥,rsync也可以实现免密钥的操作,在目标服务器上同样可以把密码记录在本机,当目标服务器发起同步请求的时候可以通过命令参数自动读取携带文件中的密钥
🔎同样密钥文件的权限也需要降低至600
使用命令
echo "123456" >> /etc/rsyncd.pwd.client将密钥写入目标服务器的文件中只需要写密钥,用户名在同步命令中指明
使用命令
rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/发起同步请求密码由参数
--password-file=/etc/rsyncd.pwd.client指明 此时仍然显示错误的原因是密钥文件的权限太高xxxxxxxxxx[root@nginx2 ~]# echo "123456" >> /etc/rsyncd.pwd.client[root@nginx2 ~]# rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/ERROR: password file must not be other-accessiblersync error: syntax or usage error (code 1) at authenticate.c(196) [Receiver=3.1.2]使用命令
chmod 600 /etc/rsyncd.pwd.client重新设置密钥文件的权限并再次发起显示同步目录的文件列表请求xxxxxxxxxx[root@nginx2 ~]# chmod 600 /etc/rsyncd.pwd.client[root@nginx2 ~]# rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/drwxr-xr-x 107 2023/12/28 21:18:27 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 14 2023/12/28 21:18:27 bottom.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.html
Rsync的命令参数
命令参数列表
-a打头的参数主要就是arv,其他的大部分是保持原文件的属性信息
-delete是做完全同步的,添加了该参数目标服务器和源服务器上的文件会完全同步,多出来不同的文件或者源服务器上删除的文件目标服务器上也会对应删除
-exclude是将文件名中包含指定字符串的文件过滤掉不进行同步,比如在静态文件合并的过程中可能目录中存在一些临时文件,此时就可以使用-exclude参数排除这些文件被同步,还可以避免同步其他一切文件创建过程中产生的临时文件【一般创建文件的过程中会生成一个临时文件和一个锁文件】
选项 含义 -a a表示跟随其他命令,可跟随-rtplgoD命令 -r r表示要同步整个目录,类似cp时的-r选项 -v v为用户显示同步过程中的一些信息 -l 保留软连接 -L 加上该选项后,同步软链接时会把源文件给同步 -p 保持文件的权限属性 -o 保持文件的属主 -g 保持文件的属组 -D 保持设备文件信息 -t 保持文件的时间属性 –delete 删除目标服务器中对应源服务器中同步目录没有的文件 –exclude 过滤指定文件,如–exclude “logs”会把文件名包含logs的文件或者目录过滤掉,不同步 -P 显示同步过程,比如速率,比-v更加详细 -u 加上该选项后,如果目标服务器中的文件比源服务器上的文件新,则不同步 -z 传输时压缩
近时同步方案
让同步的操作稍微复杂一点点,此前的同步操作实际上都是手动进行同步,此时在源服务器删掉一个文件,不在目标服务器手动同步,目标服务器是不会发生任何变化的
💡注意此前的同步都是增量同步,增加文件能同步过来,在以下试验中测试删文件同步【完全同步】
以下的实时同步用到的脚本、权限和rsync配置文件都是测试粗暴使用的,不能直接用在生产环境,生产环境让运维写专业的
减量同步
🔎此前的同步命令
rsync -avz --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/ /usr/local/nginx/html/只能做增量同步,当源服务器同步目录文件删减目标服务器使用该命令是无法相应的删除文件的,此时需要在同步命令中添加--delete参数删除目标服务器中对应源服务器中同步目录没有的文件删除源服务器上的bottom.html文件,注意此前源服务器和目标服务器因为同步过的原因,两个服务器上的文件是完全相同的
在目标服务器上使用命令
rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/查看源服务器同步目录文件列表可以看见源服务器同步目录中的bottom.html没了
xxxxxxxxxx[root@nginx2 ~]# rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/drwxr-xr-x 88 2023/12/30 17:54:20 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.html在目标服务器上使用命令
rsync -avz --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/ /usr/local/nginx/html/进行一次同步,同步后观察目标服务器同步目录的情况发现目标服务器上的bottom.html文件还在,减量同步没有实现
xxxxxxxxxx[root@nginx2 ~]# rsync -avz --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/ /usr/local/nginx/html/receiving incremental file list./sent 27 bytes received 163 bytes 380.00 bytes/sectotal size is 1,684 speedup is 8.86[root@nginx2 ~]# ll /usr/local/nginx/html/总用量 24-rw-r--r--. 1 root root 494 11月 16 08:39 50x.html-rw-r--r--. 1 root root 14 12月 28 21:18 bottom.html-rw-r--r--. 1 root root 25 12月 28 21:18 font.css-rw-r--r--. 1 root root 1117 12月 28 21:18 index.html-rw-r--r--. 1 root root 37 12月 28 21:18 page.css-rw-r--r--. 1 root root 11 12月 28 21:18 top.html在目标服务器上使用命令
rsync -avz --delete --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/ /usr/local/nginx/html/进行一次减量同步,观察同步情况🔎千万不要在delete和exclude参数前只加一个横线,会报错的
xxxxxxxxxx[root@nginx2 ~]# rsync -avz -delete --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/ /usr/local/nginx/html/rsync: Failed to exec lete: No such file or directory (2)rsync error: error in IPC code (code 14) at pipe.c(85) [Receiver=3.1.2]rsync: did not see server greetingrsync error: error starting client-server protocol (code 5) at main.c(1656) [Receiver=3.1.2][root@nginx2 ~]# rsync -avz --delete --password-file=/etc/rsyncd.pwd.client earl@192.168.200.131::ftp/ /usr/local/nginx/html/receiving incremental file listdeleting bottom.htmlsent 20 bytes received 156 bytes 352.00 bytes/sectotal size is 1,684 speedup is 9.57
近时同步
📜使用脚本完成目标服务器与源服务器的目录同步,有两种方案,这里只介绍第二种实时推送方案,第一种方案就是使用shell命令写个脚本的事情
💡第一种方案的原理是在目标服务器上写一个shell脚本定时去执行一次手动同步的命令,比如每隔两秒钟就去检测一次源服务器的目录情况【这种方案的弊端是所有机器都要配置rsync客户端并编写运行定时同步脚本,最早的聊天室就是这样的,要获取到用户最新的聊天信息,就要写一个定时任务不停地去检查用户的信息是否发送出来,这种方式存在一定资源的浪费,这是比较low的方案,因为用户如果很久都没有发出消息,就会浪费很多网络资源】
💡第二种方案是源服务器同步目录发生变化时,主动将同步文件推给目标服务器,即实时推送,实时推送也叫近时推送,实时推送需要借助另外一个工具inotify
🔎源服务器向目标服务器进行同步推送需要目标服务器以后台运行的方式启动,即目标服务器上需要使用命令
rsync --daemon启动,此前目标服务器手动拉取是不需要以后台运行的方式启动rsync的📻留意一下弹幕中提到的使用nfs共享做文件同步
同样推送也涉及到安全认证的问题,此时需要在目标服务器上创建一个安全认证文件,来供推送方进行身份验证,使用命令
echo "earl:123456" >> /etc/rsync.conf在目标服务器上创建安全认证文件这里的操作本质其实是用源服务器去连接目标服务器的rsync,额外操作是解决安全免密认证的
在目标服务器上修改rsync的配置文件
/etc/rsyncd.conf,并使用命令chmod 600 /etc/rsyncd.pwd修改安全认证文件的权限和源服务器的配置文件是一样的
xxxxxxxxxx# /etc/rsyncd: configuration file for rsync daemon mode# See rsyncd.conf man page for more options.# configuration example:# uid = nobody# gid = nobody# use chroot = yes# max connections = 4# pid file = /var/run/rsyncd.pid# exclude = lost+found/# transfer logging = yes# timeout = 900# ignore nonreadable = yes# dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2#配置rsync的安全认证,意思是每次源服务器发起同步推送都需要输入密码,设置用户名为earl,在安全认证文件中其对应的密码是123456auth users = earlsecrets file = /etc/rsyncd.pwd# ftp指一组资源,path指rsync需要同步的目录,表示一个需要同步的项目[ftp]path = /usr/local/nginx/html# comment = ftp export area在目标服务器上使用命令
rsync --daemon以后台运行的方式启动rsync在源服务器上使用命令
echo "123456" >> /etc/rsyncd.pwd.client创建密钥文件,并使用命令chmod 600 /etc/rsyncd.pwd.client修改密钥文件的权限在源服务器上使用命令
rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.132::ftp/免密访问目标服务器上的同步目录列表xxxxxxxxxx[root@nginx1 ~]# rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.132::ftp/drwxr-xr-x 88 2023/12/30 17:54:20 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.html在源服务器使用命令
rsync -avz --password-file=/etc/rsyncd.pwd.client /usr/local/nginx/html/ earl@192.168.200.132::ftp/进行推送观察文件同步情况,课堂演示命令rsync -avz --password-file=/etc/rsyncd.pwd.client /usr/local/nginx/html/ rsync://earl@192.168.200.132::ftp/和本处使用命令效果是一样的,只是课堂的命令多了一个协议,不加也默认使用该协议🔎推送和拉取的两个区别是,拉取在目标服务器拉,拉取命令原服务器地址在同步目录前面,这个同步目录应该指的是源服务器上的目录,因为ftp那个是目标服务器上rsyncd.conf中的配置本地同步目录
这里我在源服务器上创建了foot.html以观察推送情况
📌推送发现报错网络连接失败,且文件并没有被成功推送到目标服务器;但是此前查看目标服务器的同步目录又是成功的
🔑这是因为目标服务器少了一个配置,因为目标服务器认为远程提交文件到本地是有一定风险的,默认情况下是不接收用户远程提交文件的,需要在
/etc/rsyncd.conf文件下添加配置xxxxxxxxxx[root@nginx1 ~]# rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.132::ftp/drwxr-xr-x 88 2023/12/30 17:54:20 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.html[root@nginx1 ~]# rsync -avz --password-file=/etc/rsyncd.pwd.client /usr/local/nginx/html/ earl@192.168.200.132::ftp/sending incremental file listrsync: read error: Connection reset by peer (104)rsync error: error in socket IO (code 10) at io.c(792) [sender=3.1.2][root@nginx1 ~]# rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.132::ftp/drwxr-xr-x 88 2023/12/30 17:54:20 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.html在目标服务器的rsync配置文件
/etc/rsyncd.conf中添加配置read only=no配置并重启目标服务器上的rsync该配置默认是yes,表示只读,别的机器可以来本机上拉东西,但是不能写;改成no表示可以读也可以写入
xxxxxxxxxx# /etc/rsyncd: configuration file for rsync daemon mode# See rsyncd.conf man page for more options.# configuration example:# uid = nobody# gid = nobody# use chroot = yes# max connections = 4# pid file = /var/run/rsyncd.pid# exclude = lost+found/# transfer logging = yes# timeout = 900# ignore nonreadable = yes# dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2#配置rsync的安全认证,意思是每次源服务器发起同步推送都需要输入密码,设置用户名为earl,在安全认证文件中其对应的密码是123456auth users = earlsecrets file = /etc/rsyncd.pwd#将默认支持只读改成noread only = no# ftp指一组资源,path指rsync需要同步的目录,表示一个需要同步的项目[ftp]path = /usr/local/nginx/html# comment = ftp export area再次在原服务器使用命令
rsync -avz --password-file=/etc/rsyncd.pwd.client /usr/local/nginx/html/ earl@192.168.200.132::ftp/发起推送课堂因为没有真的添加文件所以没报错,我这儿添加了foot.html后报错了,原因查了一下好像是目标服务器的uid和gid的问题,这里目前还没有找到办法解决,问题参考连接【后面发生了该错误,进行了解决;这个报错不影响文件同步,这里应该是没有设置源服务器和目标服务的同步目录
/usr/local/nginx/html/权限为777导致的文件无法同步】老师解释该错误是因为rsync的配置文件配置的过于简单,甚至连当前去操作同步的用户都没有配置【博客中也提到是这个原因】,修改配置文件避免报错看自动化同步的最后配置
xxxxxxxxxx[root@nginx1 ~]# rsync -avz --password-file=/etc/rsyncd.pwd.client /usr/local/nginx/html/ earl@192.168.200.132::ftp/sending incremental file listrsync: failed to set times on "/." (in ftp): Operation not permitted (1)./foot.htmlrsync: mkstemp "/.foot.html.uDyqR5" (in ftp) failed: Permission denied (13)sent 223 bytes received 195 bytes 836.00 bytes/sectotal size is 1,684 speedup is 4.03rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1179) [sender=3.1.2][root@nginx1 ~]# rsync --list-only --password-file=/etc/rsyncd.pwd.client earl@192.168.200.132::ftp/drwxr-xr-x 88 2023/12/30 17:54:20 .-rw-r--r-- 494 2023/11/16 08:39:46 50x.html-rw-r--r-- 25 2023/12/28 21:18:25 font.css-rw-r--r-- 1,117 2023/12/28 21:18:53 index.html-rw-r--r-- 37 2023/12/28 21:18:25 page.css-rw-r--r-- 11 2023/12/28 21:18:26 top.html
配置inotify+rsync做静态资源的自动化同步
目前虽然是源服务器进行推送,但是消息推送是手动的,或者需要定时手动,这样可能消耗网络资源,使用inotify监控同步目录变化自动进行文件同步【inotify的作用就是监控磁盘文件下的某个目录是否发生变化,发生变化可以触发事件让rsync发起命令去同步目录】
🔎这种方式需要原服务器和目标服务器的rsync同时都以后台运行的方式启动
在源服务器安装inotify
以前yum源中有inotify的安装包,现在没了,现在用wget安装【课堂链接失效了,找了另一个下载地址:https://src.fedoraproject.org/repo/pkgs/inotify-tools/inotify-tools-3.14.tar.gz/b43d95a0fa8c45f8bab3aec9672cf30c/】
将安装包拷贝到
/opt/inotify目录下,在当前目录下使用命令tar -zxvf inotify-tools-3.14.tar.gz解压安装包进入解压目录使用命令
./configure --prefix=/usr/local/inotify预编译文件到/usr/local/inotify目录使用命令
make进行编译使用命令
make install进行安装
安装成功测试
如果inotify的安装目录有以下文件说明成功安装
xxxxxxxxxx[root@nginx1 inotify-tools-3.14]# cd /usr/local/inotify[root@nginx1 inotify]# ll总用量 0drwxr-xr-x. 2 root root 45 12月 30 23:20 bindrwxr-xr-x. 3 root root 26 12月 30 23:20 includedrwxr-xr-x. 2 root root 143 12月 30 23:20 libdrwxr-xr-x. 4 root root 28 12月 30 23:20 share
在源服务器的inotify的bin目录中使用命令
./inotifywait -mrq --timefmt '%Y-%m-%d %H:%M:%S' --format '%T %w%f %e' -e close_write,modify,delete,create,attrib,move //usr/local/nginx/html/开启对同步目录的监控参数
--timefmt会显示增删改查的时间日期🔎这个命令是前台启动,此时要操作改服务器需要再启动一个终端
再起一台终端,并在同步目录中创建文件,观察inotify的运行状况
【对同步目录进行操作】
xxxxxxxxxx[root@nginx1 ~]# cd /usr/local/nginx/html[root@nginx1 html]# echo "xxx" >> 1[root@nginx1 html]# ls1 50x.html font.css foot.html index.html page.css top.html【inotify的变化】
🔎显示了监控目录的创建时间、修改时间等信息,同时利用其启动事件的机制运行脚本实现监控目录目标服务器同步
xxxxxxxxxx[root@nginx1 bin]# ./inotifywait -mrq --timefmt '%Y-%m-%d %H:%M:%S' --format '%T %w%f %e' -e close_write,modify,delete,create,attrib,move //usr/local/nginx/html/2023-12-30 23:31:44 //usr/local/nginx/html/1 CREATE2023-12-30 23:31:44 //usr/local/nginx/html/1 MODIFY2023-12-30 23:31:44 //usr/local/nginx/html/1 CLOSE_WRITE,CLOSE在inotify的bin目录下创建rsync自动化同步文件脚本
auto.sh,并使用命令chmod 777 auto.sh给脚本文件执行的权限【试验用的授权很粗暴,生产要降权谨慎思考】,同时在源服务器和目标服务器都使用命令chmod 777 /usr/local/nginx/html/将同步目录的权限给满这个脚本很简单,真正在线上跑的脚本比这个复杂;因为生产环境有很多容错上的操作,一般这活都是运维干的,这个脚本不要直接在线上使用,肯定会出问题;让运维大师好好写一个
脚本可能出现错误也不报错,需要提前将每条命令都跑一下,能跑通再写入脚本
delete参数表示目标和源服务器的文件完全统一【以本机为主】
xxxxxxxxxx/usr/local/inotify/bin/inotifywait -mrq --timefmt '%d/%m/%y %H:%M' --format '%T %w%f %e' -e close_write,modify,delete,create,attrib,move //usr/local/nginx/html/ | while read filedorsync -az --delete --password-file=/etc/rsyncd.pwd.client /usr/local/nginx/html/ earl@192.168.200.132::ftp/done在源服务器的inotify的bin目录下使用命令
./auto.sh运行脚本在源服务器新建文件观察目标服务器是否同步
虽然有报错,但是文件可以同步,之前不能同步应该不是报错的原因,这里报错原因和之前是一样的,之前已经是没有设置双方同步目录777权限导致的
xxxxxxxxxxrsync: failed to set times on "/." (in ftp): Operation not permitted (1)rsync: chgrp "/.1.OfKy1Q" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.2.xGFqgV" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.3.Sx2ivZ" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.4.L3XbK3" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.5.wZT4Y7" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.6.CWsYdc" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.7.GIsSsg" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.New File.sxGMHk" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.foot.html.6SjHWo" (in ftp) failed: Operation not permitted (1)rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1179) [sender=3.1.2]rsync: chgrp "/.1.1XJCO4" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.2.9BZrw9" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.3.UgDhee" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.4.RRT7Vi" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.5.KFcYDn" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.6.7D2Ols" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.7.FelG3w" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.New File.JB7xLB" (in ftp) failed: Operation not permitted (1)rsync: chgrp "/.foot.html.QC6ptG" (in ftp) failed: Operation not permitted (1)rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1179) [sender=3.1.2]【文件同步效果】
在源服务器的rsync的配置文件添加用户来解决文件同步报错问题
🔑老师解释该错误是因为rsync的配置文件配置的过于简单,甚至连当前去操作同步的用户都没有配置【博客中也提到是这个原因】,修改配置文件避免报错
真正生产的时候需要创建一个用户去启动文件同步进程,现在为了方便直接把用户uid和gid全部改成root【gid是用户组】,实际要和去执行文件同步的用户的用户名保持一致
🔑这里只添加源服务器的uid和gid后仍然报错,同时修改了源和目标服务器的uid和gid就不报错了,表现为脚本执行没有一点消息,但是文件正常同步了
xxxxxxxxxx# /etc/rsyncd: configuration file for rsync daemon mode# See rsyncd.conf man page for more options.# configuration example:uid = rootgid = root# use chroot = yes# max connections = 4# pid file = /var/run/rsyncd.pid# exclude = lost+found/# transfer logging = yes# timeout = 900# ignore nonreadable = yes# dont compress = *.gz *.tgz *.zip *.z *.Z *.rpm *.deb *.bz2#配置rsync的安全认证,意思是每次源服务器发起同步推送都需要输入密码,设置用户名为earl,在安全认证文件中其对应的密码是123456auth users = earlsecrets file = /etc/rsyncd.pwd#将默认支持只读改成noread only = no# ftp指一组资源,path指rsync需要同步的目录,表示一个需要同步的项目[ftp]path = /usr/local/nginx/html# comment = ftp export area删除掉此前1-10的测试文件,向源服务器上传一个大一点的文件,观察目标服务器的同步效果
inotify的参数解析
参数列表
参数 说明 含义 -r --recursive 递归监视目录和其子目录 -q --quiet 仅仅打印监控事件信息,不要什么信息都打印 -m --monitor 始终保持目录监听状态 --excludei 排除文件或目录时,不区分大小写 --timefmt #指定事件输出格式 --format #打印使用指定的输出类似格式字符串 -e --event[ -e|--event ... ]accessmodifyattribcloseopenmove_tomove createdeleteumount #通过此参数可以指定要监控的事件 #文件或目录被读取#文件或目录的内容被修改#文件或目录属性被改变#文件或目录封闭,无论读/写模式#文件或目录被打开#文件或目录被移动至另外一个目录#文件或目录被移动另一个目录或从另一个目录移动至当前目录#文件或目录被创建在当前目录#文件或目录被删除#文件系统被卸载
多级缓存
处理高并发最好的手段就是不让请求产生高并发,缓存能很好的配合这个主题
资源静态化相当于将服务器中的动态资源生成了静态资源,相当于上游服务器对动态数据做了一层缓存操作,将本应该动态查询的操作前置化了,做缓存时有个原则是尽可能将数据和缓存内容尽可能向用户靠拢;缓存除了资源静态化前置到nginx反向代理服务器中,还有很多其他方式:如浏览器缓存【浏览器发起请求时并不是真的每次都完整的向服务器发起请求,而是将本地一些之前访问过的数据直接响应给用户,通过nginx可以控制浏览器对哪些文件进行缓存】
业务场景示例
很多时候用户的请求压根就到不了服务器,比如双十一秒杀抢购,可以在客户端预埋一些数据,在大量并发请求到来以前就能预测到大概会有多少并发量,比如商品秒杀,商品页面的购买按钮会由即将开始变成立即抢购;在页面还没有变化以前,就能大致根据一些预埋数据统计出页面大概有多少人关注,此时后端服务器其实能知道大概有哪些商品是热门商品了;此时后端服务器会下发一份热门商品列表给客户端,对于太过热门的商品比如10000个人抢一件商品,此时甚至会直接跳转您来晚了,或者点了也没用,让客户端根本没发起请求;即便让客户端发起请求了也可以直接在nginx把客户端请求拦截住,不再去调用加入购物车和检查库存的操作,直接根据热点数据判断,即使用户点击了立即抢购也会直接显示您来晚了,通过这种方式可以屏蔽掉很多的请求打到服务器上来处理高并发;这是很多电商平台都在使用的方法,预埋数据一般是在app上实现的,因为浏览器很多时候出于安全和功能上的考虑导致其不够灵活
常用的多级缓存
大部分重复无意义的请求通过nginx服务器的资源静态化、动静分离、浏览器缓存和CDN缓存都会被过滤掉,
很多缓存方式其实是混合在一起的,基本分类有:静态资源缓存、浏览器缓存、CDN缓存、正向代理缓存、反向代理缓存、Nginx内存缓存、外置内存缓存、上游服务器应用缓存
缓存学好了就可以做一些大型网站的开发了,只要你的手段够多,就可以层层削减到达上游服务器的请求应对高并发场景,从容地处理高并发的冲击,同时nginx强大的扩容能力还能很好很快的应对系统瓶颈
nginx服务器
💡对动态数据生成的静态页面进行缓存【基于反向代理的缓存】
💡nginx还能做基于本机的proxy_cache缓存【基于正向代理的缓存,这里的正向代理是相对于nginx和上游服务器而言的】,nginx服务器向上游服务器发起请求会收到响应数据,nginx服务器可以将响应数据缓存起来,如果此后还需要向上游服务器发起相同的请求,此时就不会向上游服务器发起请求而直接使用在本机上存储的响应数据【nginx本身的性能是非常高的,但是如果上游服务器的计算比较耗时,此时上游服务器才是系统的瓶颈,这时候就无法发挥nginx服务器的高性能特性】,nginx对一些热点请求即使是动态请求也可以像redis一样缓存起来,比如微博热搜某个演员或者热门事件,搜索请求的url假如是account?uerid=100,此时nginx可以根据请求的完整URL对响应数据做一层缓存,下次相同请求nginx直接把数据返回给用户【这里面有数据的时效性问题,后面再细节探讨】
🔎nginx上的缓存主要都是基于磁盘文件性质的存储,性能上磁盘文件低于内存,但是在一些特殊场景下可能会存在较大的性能差异,对某些情况还可以在nginx上做基于内存的缓存,响应数据会远远高于在磁盘上做的缓存;一般磁盘缓存和内存缓存都会配合使用,磁盘缓存的价格非常低,一般用来做一般热点的缓存;对一些极为热点的数据,如秒杀、秒杀热点商品的详情页都可以放在内存中,非热点商品就可以放在磁盘上;【此外还可以在上游服务器做缓存,上游java或者PHP服务器的缓存方案也非常完善和庞大,不仅可以在本机做缓存,也可以在redis和memacache上做第三方缓存,同时nginx也是可以使用第三方redis、mamecache做缓存,把本应该存在nginx内存中的缓存存在第三方服务器上】
浏览器缓存
浏览器会利用本地的缓存空间来缓存一些之前访问的数据,但是无法做到预埋数据,即提前下发特定数据给浏览器缓存,等到了特定时间再使用该缓存数据,在浏览器上这是无法做到的;浏览器可以缓存一些不怎么发生变化的css和js数据,让缓存数据直接响应;这样浏览器和客户端的压力都会减小
基于CDN的缓存
CDN又称全网内容分发网络,系统可以配置一个上游服务器,该上游服务器连向CDN集群,可以把内容分发到所有的CDN机器上,就像此前讲的静态文件同步,源服务器向目标服务器同步静态资源;区别只是CDN不是在内网集群中分发,即这些CDN集群已经不在同一个机房,基本上已经跨了区域甚至国家;可以在全球的热门城市去部署系统的CDN服务器,把一份静态资源同时分发到这些服务器上,在用户访问的时候解析用户的IP让用户就近去访问对应的静态资源【用户和服务器的距离越近访问速度就越快】,内容全网分发适合静态资源和内容一般不变化的数据;现在也有很多CDN服务商提供动态数据的缓存,比如用户访问某个列表,列表每页展示一些数据,这是动态的数据访问,但是如果每页的数据不咋变化,业务对数据的一致性或者及时性要求没有这么高,比如需要经过审核的新闻或者数据在审核期间会花费一定的时间,此时就可以在审核间隙将上次审核通过的内容批量缓存到CDN集群中;CDN缓存列表数据也不会直接将第一页到第10000页全部缓存,基本上也只是缓存用户点击比较频繁的一些页面;像百度和google搜索结果的前几页都是响应耗时非常短的;因此对于非常热门的数据可以在CDN服务器上缓存下来,过一段时间再去更新
🔑静态文件可以用,一段时间内热门的动态数据也可以用
多级缓存的意义
总的原则是让数据尽可能的靠近用户,同时避免用户真正的请求到最复杂的上游服务器上,用户请求减少了,上游服务器的并发量也就减少了,这种方式也是流量削峰的一种具体实现,将原来集中打到后端服务器的请求分摊到各个节点进行分摊处理;是一种不同于消息队列的削峰实现方式,通过多级缓存打到nginx服务器上的请求本身就会减少非常多,在经过nginx的缓存后直接打到后端服务器上的流量就更少了,此时再在上游服务器应对高并发就能更加从容
多级缓存的整体结构
实际的企业应用缓存有,但是没有这个这么复杂,一般企业随便用缓存搞一搞就能抗住并发请求;对于大型互联网公司需要去继续深入每一个知识点,而且每个知识点都是很大的世界
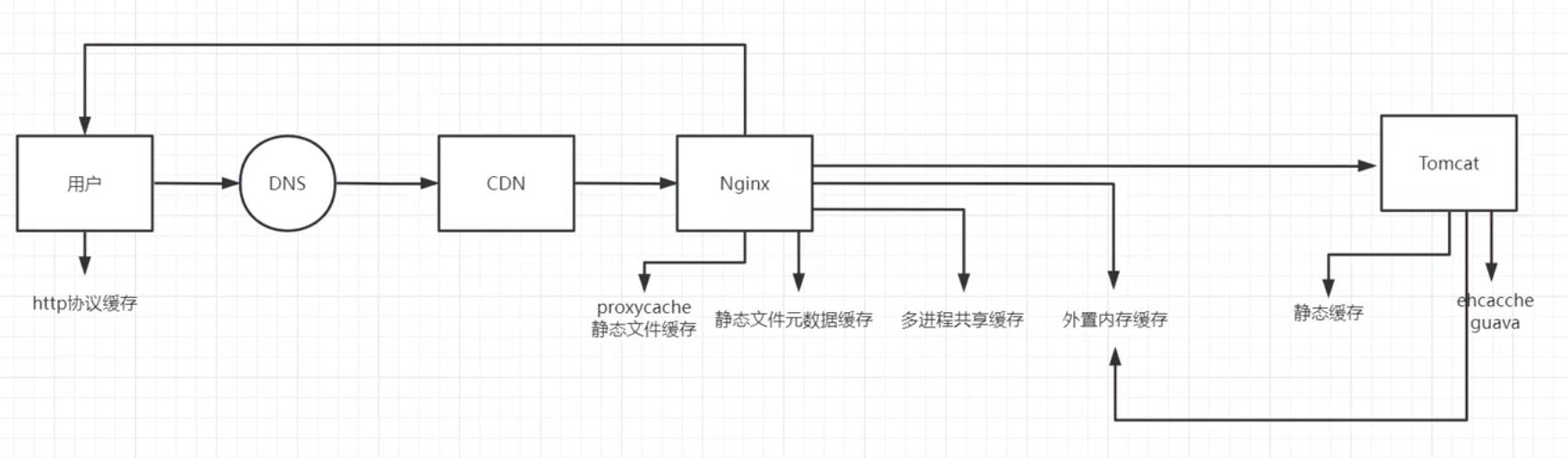
基于浏览器实现的http协议的缓存
DNS缓存,DNS缓存内置到各大操作系统中,不管是移动端还是桌面端的操作系统对DNS都有缓存,DNS服务器不可能对每次请求都去做DNS解析,所以DNS服务器在本机上已经有一层缓存;上游的DNS服务器还会有缓存,层层缓存;浏览器缓存没有就会走本机的DNS缓存实现高效解析域名的目的
下一层缓存是CDN服务器,全网资源分发网络,可以将大量的静态资源直接部署到距离用户最近的机房达到快速访问的目的,CDN服务器基本存储的都是不太变化【不是特殊情况不会改变的东西,三五天就会变更的东西尽量不要存到CDN服务器上】的静态资源,CDN自身缓存没有更新的时候,响应给用户的数据还是老的数据,虽然现在CDN服务器比较先进,支持各种各样的功能,但是总的来说不要过多的去参与其他节点的操作,也不要把性能设计的特别极致,可能费劲脑子想出来的东西花点钱就能很好的弥补【CDN本身解决的问题是跨区域问题】
再远一点是Nginx服务器,可以做proxy_cache静态资源文件的缓存,使用HTTP协议配合浏览器做浏览器静态文件的缓存;利用Nginx的静态文件元数据缓存配合sendfile使请求响应更加高效【这个是Nginx内存缓存,存索引的】;多进程间共享级别缓存,存一些热点数据内容,在磁盘上需要寻址文件并且读取文件,读取性能和内存比起来是天壤之别,缺点就是内存大小受制约,几百G的数据存入内存一般不太好做,成本太高;公司不差钱可以做到几个T的内存共享数据,就算是这样,这些机器也不能挂,即便数据都不丢失,几个T的数据要初始化也是很麻烦的事情
再远就是外置内存缓存,一般都是nginx的内存缓存不够用了,用第三方外置缓存方案redis、memorycache做外置缓存
📓redis可以用nginx直接访问,不要通过上游服务器去返回数据,上游服务器负责向redis存入数据【项目优化】,改进点,但是目前不知道咋实现,数据量少直接放到nginx的进程间共享缓存
上级tomcat应用服务器的缓存,java本身就做了一层缓存,java内存中的对象,静态变量都不需要用户进行管理,这些缓存数据在内存中可以直接用【经典的单例模式就是,把高频访问的数据放在单例中,这是静态缓存,还没聊到JVM这一层】,java内部还可以通过ehcache或者谷歌的guava第三方组件组建JVM级别的内存【JVM堆外内存】,tomcat也可以去访问第三方的缓存中间件
浏览器缓存
Nginx默认就是强制缓存和协商缓存配合的方式
京东的浏览器缓存情况
size字段中凡是有大小的一般都是直接从服务器获取的,显示为XXX cache的一般都是从浏览器缓存获取的
XXX cache分成两类,memory cache【内存缓存】和disk cache【磁盘缓存】;磁盘上存储的内容和其有效期会长一些,内存缓存由于没有持久化,浏览器重启以后,内存缓存就没有了;因为浏览器对内存缓存的管理不太好,清空缓存的方法是关闭页面,网页开多了容易导致浏览器内存占用居高不下;此外内存缓存和磁盘缓存在速度上内存缓存的Time几乎都显示为0ms,微秒量级;磁盘缓存就有1-几十毫秒的延迟;内存上缓存数据的加载速度远远高于磁盘上缓存的加载速度,但是对于客户来说都是难以感知的,相比于真正向服务器发起的请求,延迟动则都是几十、上百毫秒的延迟,像打游戏如果延迟高于300毫秒,游戏体验就很差了
浏览器缓存使用的场景
浏览器缓存基本缓存的都是一些静态资源,比如图片、js文件、css文件,服务器在响应文件的时候可以设置缓存的时间、缓存时间比较短的情况下,浏览器会优先将文件存入内存缓存中;
此外浏览器还会根据文件的类型进行判断,js文件的变化一般都很小,一般都直接存入磁盘缓存【下发js文件的有效期可以设置的长一点】;图片被更换的频率会高一些,一般都是内存缓存【下发图片的有效时间设置的稍微短一些】,浏览器也会自动根据资源的有效时长自动分配使用内存缓存,还是使用磁盘缓存
用户能够设置浏览器使用缓存的空间大小以及设置是否使用缓存
资源有效时间的影响
设置时间过长,客户端可能长期使用本地缓存,不能及时更新服务器的真实数据
浏览器的缓存有效时间不必太较真,因为浏览器的缓存内容一旦影响到用户的正常使用又或者客户使用第三方的软件清理电脑,都很有可能会将浏览器中的缓存数据给清空
浏览器缓存类型
chrome浏览器在市面上的占有率是第一的,大多数浏览器都套用的chrome的内核,这里只讲解nginx对chrome浏览器的缓存配置,其他的浏览器在设计的时候也是向浏览器靠拢的
强制缓存
服务器在响应客户端请求时会给响应文件设置有效时间,意思是有效时间内都可以使用该下发文件而无需再次向服务器发起相同请求,有效时间内直接使用本地缓存,压根就不向服务器发起请求
强制缓存的问题:一旦系统、时间日期发生变化后浏览器缓存就会失效
协商缓存
浏览器即使本机上使用了缓存,但是还会去浏览器去查一下对应的文件是否发生更新,不是一昧的认为浏览器本机上有效时间内的缓存都是可以直接使用的;因为系统的时间只要变动超过服务器设置的有效时间,浏览器缓存就会失效;但是以服务器的文件更新时间作为依据,只要文件没有更新,缓存文件就可以一直使用
具体过程是浏览器第一次去请求服务器资源,服务器响应时会将文件的最后修改时间
last_modify:XXX响应给浏览器,浏览器再次请求时会在请求头中携带该参数last_modify:XXX,服务器会拿着这个时间和磁盘上的文件的最后修改时间比对,如果相同就会直接返回响应头并响应状态码304,不再响应文件,浏览器看到状态码304就会直接使用浏览器的缓存协商缓存虽然会有请求打到服务器上,但是能有效避免用户的缓存不生效或者缓存一直不过期【一种是客户端的系统时间设置混乱导致缓存一直不生效,或者系统时间设置的过前导致缓存一直不过期】
🔎注意ssi的配置
ssi_last_modified开启后每次新合并的文件都会以当前合并时间作为文件的最后修改时间,开启该配置会和浏览器的缓存配置相冲突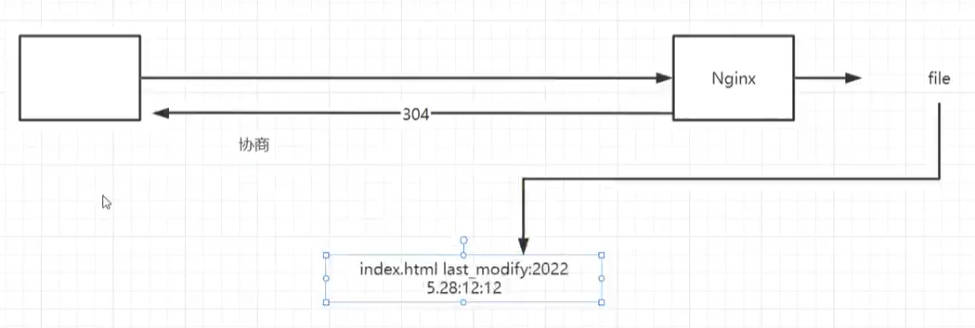
默认协商缓存
🔑nginx在什么也不配置的情况下默认是使用
ETag和Last-Modified实现的协商缓存方式,但是只要开启ssi功能,浏览器的缓存功能会立即直接失效,目前为止的其他配置并不会影响协商缓存功能一般使用默认的协商缓存就可以了,但是nginx还提供了其他浏览器缓存配置方式
nginx对chrome浏览器的缓存配置
默认情况下,即什么都不配置的情况下,nginx会使用协商缓存;但是多次本机尝试,在开启
缓存相关的响应头参数
ETag和Last-Modified属于协商缓存,这两个参数都标记的是文件的时间Last-Modified是文件资源的最后修改时间ETag【Entity Tag】是文件的一个相对精确的哈希值,一旦文件修改了,这个哈希值就会发生变化;可以拿着文件名和ETag去检查文件是否修改过,ETag的哈希值实际是用文件名、文件大小和最后修改时间连起来做的哈希值只要文件内容【哈希值】或者修改时间没变,
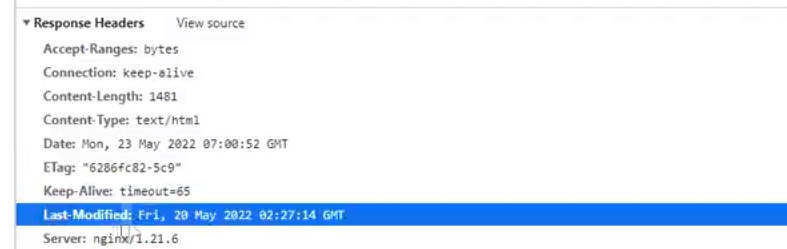
请求信息
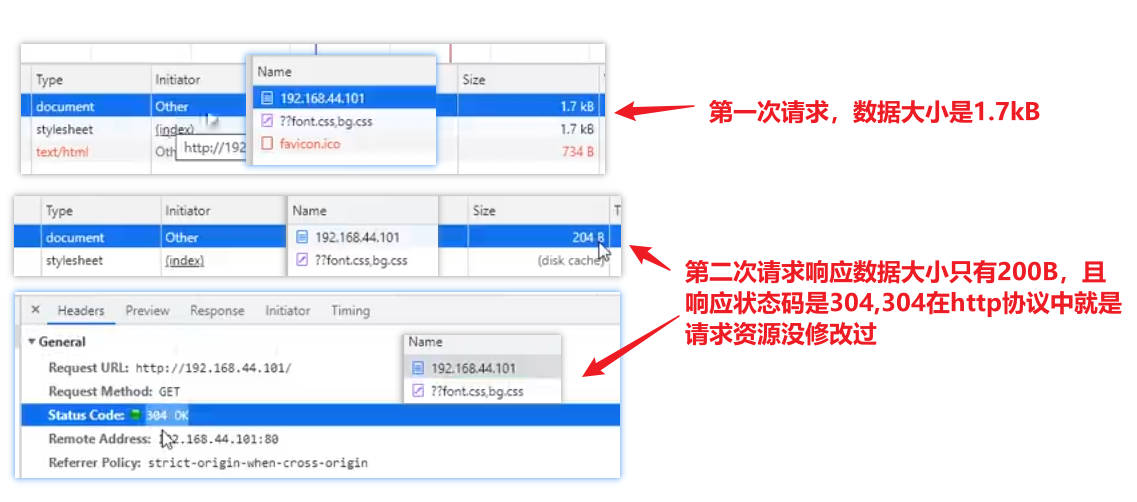
请求参数
浏览器在请求头中添加了
if-Modified-Since参数就说明浏览器在发起请求时已经确认了,这个参数就是本机缓存文件读出来的最后一次修改时间,有这个参数服务器才会去查服务器上的最后修改时间,并响应304。所以返回304浏览器是一定能响应缓存文件的;唯一的可能就是在发起请求后还没响应结果前立即将缓存文件删了if-None-Match:该参数匹配的就是请求资源的ETag请求头有这俩参数就表示本机已经有这两个文件了,首次请求没有缓存会在请求头中添加参数
Pragma:no-cache表示没有缓存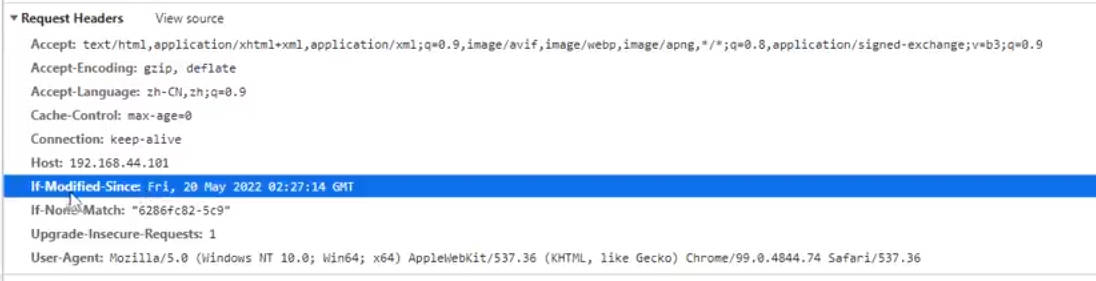
注意,开了nginx的ssi功能,即便没有设置参数
ssi_last_modified,浏览器的缓存就会直接失效,即便配置只有以下简单两行经过测试,即便只是开启ssi功能的一行配置
ssi on,nginx的缓存功能就会直接关闭;当前最完整配置下的其他部分包括gzip等都不会影响缓存请求中有一个未知文件
141.327ce5c7.js的请求URLchrome-extension://cdonnmffkdaoajfknoeeecmchibpmkmg/assets/141.327ce5c7.js永远不会走缓存xxxxxxxxxxssi on;ssi_silent_errors on;
配置关闭ETag
在location下添加参数
etag off即可关闭默认的缓存功能我这儿off的配置关不掉,开新页面、换浏览器、清缓存都没用
xxxxxxxxxxetag off;如果响应头中还有ETag的参数清除浏览器缓存再尝试,再不行尝试多开几个标签页
老师说这里用不用缓存主要是浏览器决定的,配置是对的,但是我尝试了多种方法,请求头还是有ETag参数,而且即便像老师的演示中ETag参数没了,但是还是没有发起请求,走的是磁盘缓存,而且返回的状态码也同样是304,因为老师的参数中还有
Last-Modified参数【我这儿首次请求两个参数都有】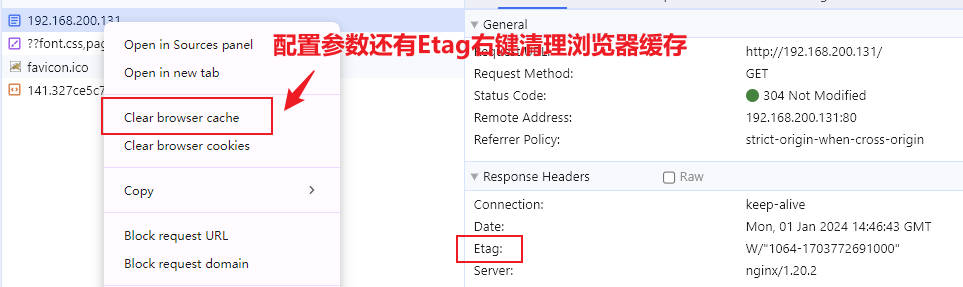
【演示关闭ETag但是走磁盘缓存】

【老师响应头参数】
要完全禁用协商缓存还要同时禁用掉
Last-Modified参数或者让nginx判断即使请求头带了If-Modified-Since参数也不返回304状态码🔑禁用掉
Last-Modified参数🔑nginx判断即使请求头带了
If-Modified-Since参数也不返回304状态码,直接响应数据
在location中将响应头的参数
Last-Modified置空我这儿还是没反应,老师的演示中ETag参数和Last-Modified参数都没了,而且不再走缓存,而且请求头显示no-cache;我的Last-Modified参数消失了,而且请求头不带
If-Modified-Since,但是由于ETag仍然存在,还是走的缓存xxxxxxxxxxadd_header Last-Modified "";在location中关闭对请求头参数
If-Modified-Since的304响应演示中请求头中有
If-Modified-Since参数,但是响应变成200,且不走缓存;但是因为我这儿还有ETag,仍然走的304协商缓存;核心问题是ETag关不掉;实际上我的凡是XXX off的配置压根就没生效,对ETag如此,对if_modified_since off;仍然如此,不知道问题出在哪里ETag响应参数也可以置空,当我
ETag和Last-Modified两个参数都置空以后,终于不走缓存了xxxxxxxxxxif_modified_since off;成功关闭协商缓存的配置
因为
XXX off的配置不起作用,只有将ETag和Last-Modified两个响应参数全部置空才能完全关闭协商缓存,老师的演示中置空和etag off;以及if_modified_since off;都没有问题;换IE浏览器还是如此,火狐也是一样xxxxxxxxxxhttp {sendfile on;send_timeout 60;upstream stickytest{keepalive 100;keepalive_requests 1000;keepalive_timeout 65;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {#if_modified_since off;#etag off;add_header ETag "";add_header Last-Modified "";proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}
强制缓存
关闭协商缓存的前提下开启强制缓存
强制缓存一般只是首次开启标签页从磁盘直接加载,连请求都不会发;一般都是强制缓存和协商缓存混合使用,首次打开从磁盘加载,后续刷新使用ETag和Last-Modified做协商缓存
强制缓存的主要参数
expires
资源的有效时间,单位可以是秒[s]、分钟、小时[h]、天数都可以
像logo和网站图标几乎不会变化,可以把过期时间设置的超长,比如半年、一年
该参数在location中使用,使用后响应头会出现Expires参数,会显示响应的过期时间为当前时间+资源有效期
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {sendfile on;send_timeout 60;upstream stickytest{server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {add_header ETag "";add_header Last-Modified "";#设置强制缓存300s有效期expires 300s;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【强制缓存效果】
响应头中带参数Expires,但是连续刷新可以发现请求除了引用的静态资源走了磁盘缓存,主请求每次都没有走缓存
原因是Expires参数是比较老的参数了,http1.1版本以后主要使用cache-control,而且不同的浏览器对响应头中的Expires参数的处理情况不同,像chrome是只在新开一个标签页的时候会直接使用主页的磁盘缓存,即使是这个新标签页,只要刷新,此后所有的刷新都会发起请求且不走缓存
🔑Chrome浏览器只会在新开标签的时候主请求使用Expires参数设定的强制磁盘缓存,此后该标签页每次刷新主请求都是真正的请求,这是Chrome浏览器的策略
在HTTP1.1以后有一个比Expires优先级更高的参数cache-control
【Chrome浏览器对Expires参数的响应行为】
cache-control
cache-control可以和Expires配合使用,这里为了演示效果先注释掉Expires,cache-control的优先级远远高于Expiresxxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {sendfile on;send_timeout 60;upstream stickytest{server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {add_header ETag "";add_header Last-Modified "";add_header cache-control "max-age:300";#设置强制缓存300s有效期#expires 300s;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【cache-control参数可以配置的参数值】
比较常用的是
no-cache【使用缓存,但是必须发送验证】、no-store【禁用本地缓存】和max-age【这个和Expires是一样的,就是资源可以在浏览器上缓存的最大时间】标记 类型 功能 public 响应头 响应的数据可以被缓存,客户端和代理层都可以缓存 private 响应头 可私有缓存,客户端可以缓存,代理层不能缓存(CDN,proxy_pass) no-cache 请求头 可以使用本地缓存,但是必须发送请求到服务器回源验证 no-store 请求和响应 应禁用缓存 max-age 请求和响应 文件可以在浏览器中缓存的时间以秒为单位 s-maxage 请求和响应 用户代理层缓存,CDN下发,当客户端数据过期时会重新校验 max-stale 请求和响应 缓存最大使用时间,如果缓存过期,但还在这个时间范围内则可以使用缓存数据 min-fresh 请求和响应 缓存最小使用时间, must-revalidate 请求和响应 当缓存过期后,必须回源重新请求资源。比no-cache更严格。因为HTTP 规范是允许客户端在某些特殊情况下直接使用过期缓存的,比如校验请求发送失败的时候。那么带有must-revalidate的缓存必须校验,其他条件全部失效。 proxy-revalidate 请求和响应 和must-revalidate类似,只对CDN这种代理服务器有效,客户端遇到此头,需要回源验证 stale-while-revalidate 响应 表示在指定时间内可以先使用本地缓存,后台进行异步校验 stale-if-error 响应 在指定时间内,重新验证时返回状态码为5XX的时候,可以用本地缓存 only-if-cached 响应 那么只使用缓存内容,如果没有缓存 则504 getway timeout 【响应效果】
【cache control的max-age参数设置效果】
这还没有Expires参数好使呢,Expires参数第一次开标签页的时候主请求也走缓存,后续静态资源走缓存,主请求不走缓存,这样是为了顺应用户刷新页面的目的是看到页面变化,比如等待页面变化为开始抢购,这样的浏览器行为就是为了让用户刷新页面看到变化
老师的演示cache control的max-age:300的效果和Expires完全一样,后续刷新主请求走服务器响应完整数据,静态资源仍然走缓存;但是我这儿不是,我这儿是新开标签页图标走缓存,其他的请求全部发真实请求;后续刷新包括图标也发真实请求【可能是浏览器版本不一样吧,这儿我的后续静态资源不走缓存是因为我把Etag和Last-Modify的参数的值都设置为空了,导致文件没有ETag属性和Last-Modify属性,甚至首次请求都不走磁盘缓存了;不将这两个属性置空的情况下,开启强制缓存,开启新标签页所有请求走磁盘缓存没问题,同时后续请求走协商缓存也没问题;但是因为我的ETag off和if_modified_since off;压根不起作用,两个属性置空虽然关闭了协商缓存但是无法观测到完全的强制缓存效果;这里只能看到同时开启强制缓存和协商缓存的效果和老师的效果是完全一样的,核心问题就是nginx设置的
etag off;和if_modified_since off;对浏览器完全没效果,无法通过这两个设置关闭协商缓存】
一般方案
nginx服务器默认就是使用的强制缓存和协商缓存配合的方式
总结
协商缓存
响应头参数:
ETag、Last-Modified请求头参数:
If-None-Match、If-Modified-Since效果:新标签页首次请求发起全新完整请求,此后发送简单【大小100B左右】请求根据这两个参数独立判断服务器文件是否发生更新,未更新服务器响应304,浏览器使用缓存;发生更新,服务器再次响应完整数据
强制请求
响应头参数:
cache-control、Expires效果:浏览器根据这俩参数在文件有效期还没结束前会在打开新标签页的时候自动从磁盘缓存加载资源文件、后续用户每次刷新主请求都会完整的响应【老师的效果是这样的,但是我的浏览器cache-control不是这样的】
实际使用可以结合强制缓存和协商缓存
实现首次请求根据有效期从磁盘缓存中加载,即强制缓存;此后用户刷新页面使用协商缓存,发送简单请求访问浏览器检查文件是否发生更新,没更新返回304依旧使用缓存,更新了响应完整数据
既不会浪费网络资源,同时也可以展示最新的页面
这个效果我的nginx配置在chrome浏览器上是能生效的,在nginx设置的
etag off;和if_modified_since off;对浏览器完全没效果的情况下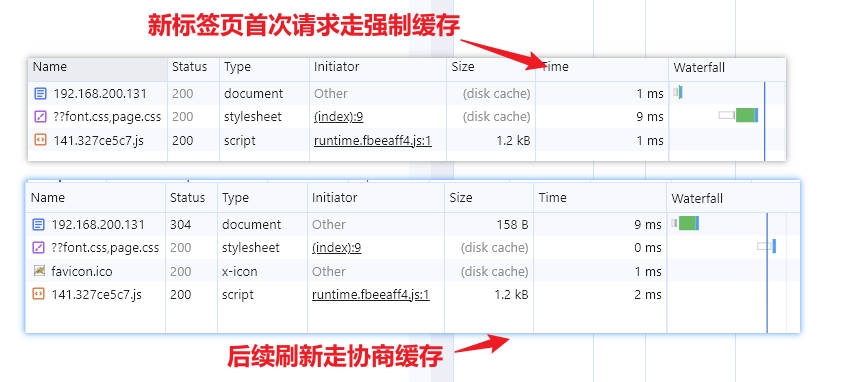
浏览器缓存的使用技巧和经验
多集群负载时要避免修改服务器
ETag和last-modified,要保持服务器各个集群机器上相同文件的这两个参数是一致的,避免某个机器对文件的原数据信息进行修改,某个机器上稍微一改就可能会导致nginx在对集群做反向代理负载均衡时导致客户端的缓存直接失效无法使用服务器很难控制客户端的缓存行为,在一些情景下服务器可能希望禁用浏览器缓存【比如轮询上报数据】,这种禁用缓存很难彻底通过服务器端控制,最方便的办法就是在请求URL后面加版本号、随机数和时间戳等方法,核心原理是让每次请求的URL都不一样,这样的好处是不会影响服务器配置也能实现不走浏览器缓存
不要配置像3XX这样跳转响应的缓存,因为可能瞎配置导致响应码3XX的跳转响应也被缓存了,这样可能会直接跳转老地址,连新数据都请求不到,只缓存响应码200的数据
js、css文件这类可以缓存很久的数据,可以通过加版本号的方式来更新缓存内容,加版本号是为了增量更新,前端脚手架如webpack,vite都是这么做的
对于一些实时展示的数据,但是对时效性又不是特别强的数据,可以配置浏览器缓存设置有效时间几秒钟,来避免发送过多的请求在高并发情况下对服务器产生太大压力,可以有效的提高并发性能
🚁【切面编程的应用场景】
📓 服务器端还可以使用自定义文件的ETag来控制浏览器是否使用缓存的行为,文件的ETag属性一定生成在文件生成之后,因为原始ETag属性由文件大小生成,服务器端可以通过切面编程的方式在响应的最后在响应头中写入自定义ETag属性的值来控制响应文件的ETag属性从而实现通过控制ETag属性值和协商缓存控制用户统一的更新数据【在早期或者程序中即使写入自定义ETag后续生成文件后也会被覆盖,所以要在切面的后期写入该属性值】
可以将服务调用的服务器信息或者服务器标识全部追加写入响应头的Server属性中,像京东的
Server:nginx和淘宝的Server:tengine,出了问题可以去追踪对应的错误信息项目中对手机APP和浏览器客户端,不同平台可能使用的网络协议和对网络协议的实现会存在差异,需要和开发人员沟通平台上的网络协议是否遵循HTTP协议
使用缓存的一些好处
没有联网的状态下也能展示数据
减少流量消耗,节省网络资源
通过提前下发数据,避免在高并发场景下如秒杀同时需要下发大量数据和处理全部请求导致流量短时间暴增压垮服务器;提前下发在APP上用的比较多,浏览器用的比较少
兜底数据,像APP一样当服务器崩溃或者网络不可用的时候,会展示一个基本的服务框架,并且对已经缓存的数据仍然可以访问,不会因为网络中断或者服务器不可用直接返回一个404error页面或者APP压根不能使用全白的情况;此外还有api发送请求的时候,即便没有网络也可以像强制缓存一样响应缓存的内容,不会直接报错,也是一种兜底手段
设置临时缓存能够避免浏览器过多的使用缓存导致数据永远使用不了最新的;对一些比较固定的数据,比如页面框架或者logo、图标等长时间不会变化的数据,可以将有效时间设置的长一些成为固定缓存;但是变化频繁的数据应该禁用缓存来保证加载的数据都是最新的
父子页面,子页面的内容可能除了文字内容发生了变化【比如新闻APP、知乎的界面】,其他的都和父页面是一样的,此时就可以使用父页面相同资源的缓存加载子页面,子页面只需要去请求有差异内容即可
预加载,通过一些逻辑判断可以判定一下用户接下来的操作,比如搜索文章响应文章列表的同时将文章数据同时也响应给客户端,这主要是一些前端的技术,一方面用户点击文章后文章无需加载秒开,另一方面如果用户在高速上或者地库中,因为网络及其不稳定【特别是高铁】,这种方式即使网络不太好用户也可以获取尽可能多的数据
CDN缓存
现在CDN相关的产品有非常多,各大云平台都在提供,现在使用一定是购买相关的产品,开发CDN就不用考虑了,除非是做相关的产品
QUIC是谷歌提出的基于UDP实现的一套web数据传输协议,想要替换掉HTTP协议,因为HTTP协议是基于TCP连接的,TCP连接需要做三次握手操作;DNS是基于UDP连接,DNS本身是一种不可靠的网络,但是QUIC因为约束和限制能够达到数据不丢失,且不需要握手,数据可以直接向目标地址发送过去,DNS开发一般都使用Nginx和OpenResty
CDN介绍
全网资源分发网络,现在主流的CDN产品一般分为三个部分
重点是在Web服务器上做优化,因为CDN服务器面临的一定是比较高的并发量,如何提高网络带宽和提高网络速度;现在主流的Web服务器就是Nginx,用的是最多的;极为牛逼的程序员可以通过Nginx的源码去做一些适用于CDN服务的改造【主要是性能方面的提升,省去一些无效的判断让nginx能够达到更高的运行效率】
DNS系统:负责域名解析
因为CDN的目的就是将资源分发到整个区域,用户访问时将离用户最近的资源响应给用户,此时CDN就需要解析目的站点的域名,寻找CDN系统中哪些机器中有对应客户的资源;同时还需要解析用户的IP,为用户分配就近的服务器站点;比如北京的用户最好访问北京的服务器,伦敦访问伦敦的服务器
高性能Web服务器
这就是离用户最近的服务器,该服务器拥有web服务器的一切操作,比如处理HTTP的头信息、完成gzip或者br的压缩;该web服务器和一般的web服务器没什么区别,只是该web服务器会接受客户服务器的静态文件的分发,只是那个是一个内网中利用小工具进行的分发同步;这里是在不同的地区而且接入的客户很复杂,通过公网连接,这种情况下的分发需要一个专门的IT系统来完成分发工作并决定资源的分发时机和过期时机【用户客户端浏览器的缓存过期时机和与IT系统拉取客户的资源时机】,web服务器负责承载这些资源供用户进行访问
IT系统:该IT系统相当于后端管理系统,做一些增删改查的工作
CDN产品
阿里云的CDN:
购买是通过流量进行购买,自己开发流量小的情况下开发成本是远远高于购买流量的价格的
硬件相比一般服务器更好,硬盘使用SSD,读写速度快,支持自定义缓存时间【指去客户原服务器拉取数据的时机】和请求头
也可以配置动态资源通过CDN去访问,但是一般不建议,就是动态数据的响应结果缓存到CDN上,隔几分钟再去原服务器上重新更新拉取一下
还可以配置防盗链、鉴权、和添加IP黑名单
在性能方面能够移动去除用户静态资源html、js、css中的注释和空白符,减少文件大小、压缩静态文件【gzip、br】,过滤静态资源请求URL后面的参数
日志管理
应用场景
视频点播【B站上的视频也是缓存在不同的服务器上的】,不然相隔很远的视频访问延迟一定是非常高的;视频直播也会使用CDN缓存,直播都会有几秒的延迟,该延迟就是用来同步数据到全网节点上;同步数据的两个节点如果也比较远还可以通过专有网络直连两个节点提高速度,但是这种专线网络方式一般价格都比较昂贵;下载加速;网站加速;移动端加速
GEOIP2
GEOIP是一家商业公司开发的组件,现在升级到版本2,不仅可以使用在nginx,还可以使用在java、python上,提供云API供用户直接调用,IP和地区对应的库该公司也免费开放出来了,免费版比商业版的数据精确度差一点;早期的DNS解析做的不是很好使用比较广泛,现在基本各大云平台都有很强大的DNS解析技术;自己搭建一个DNS解析系统配置和部署比较麻烦,但是现在都是云平台商提供;因此现在的GEOIP的应用场景其实不是很多,主要都是阻断一些用户请求【比如站点不对一个国家开放,或者站点只对一个城市开放,又或者根据用户所属不同区域向用户展示不同的站点,现在也比较少了,用的最多的也就是一些资源只限某个地区的用户使用】
GEOIP2的安装
tcp连接IP是无法造假的,因为tcp造假服务端数据就无法正常响应给用户
GEOIP的安装比较麻烦,需要下载3个资源
GEOIP的Nginx模块配置nginx官方文档:http://nginx.org/en/docs/http/ngx_http_geoip_module.html#geoip_proxy,这个文档是比较完整的,github上对该模块的配置讲的不是很完整
需要前往GEOIP的官网下载ip数据库
要下载需要注册并登录,GEOLite2是免费版的库,GEO2是付费版的库,而且他的库更新频率特别高,线上使用也要频繁的去更新
登录使用邮箱和密码
【下载选项】
country只能检索到国家,City能够检索到城市,ASN能检索到更详细一点的区域;测试下载country版本的就行,数据库越大,检索的效率太低,下载gzip版本;csv版本可以直接导入数据库如mysql或者oracle
测试导入云服务器上,这样能解析我们自己的ip,在自己电脑上部署无法进行访问,导入
/opt/nginx目录下并将数据库解压,等待nginx配置文件配置解压目录地址
前往GEOIP的官方git下载GEOIP模块的相关依赖:https://github.com/maxmind/libmaxminddb
下载1.6.0版本libmaxminddb-1.6.0.tar.gz
安装需要gcc,使用命令
yum install -y gcc安装gcc,解压后在安装目录执行./confugure,使用make进行编译,使用make install进行安装;使用命令echo /usr/local/lib >> /etc/ld.so.conf.d/local.conf配置动态连接库【相当于在系统的动态连接库下额外增加一个目录】,使用命令ldconfig刷新系统的动态链接库前往GEOIP的官方git下载GEOIP的对应Nginx上的模块:https://github.com/leev/ngx_http_geoip2_module
下载3.3版本ngx_http_geoip2_module-3.3.tar.gz
安装GEOIP需要pcre-devel,使用命令
yum install -y pcre pcre-devel安装;安装GEOIP需要zlib,使用命令
yum install -y zlib-devel安装;解压缩GEOIP模块的压缩包,进入nginx的解压目录使用命令
./configure --prefix=/usr/local/nginx/ --add-module=/opt/nginx/ngx_http_geoip2_module进行静态安装【动态安装更好,静态安装只是安装更省事】,使用make进行编译,使用make install进行安装【此时已经安装完毕,只需要在配置文件中进行配置,我云服务器上的nginx是通过oneinstack.com安装的,不知道安装包在哪儿,且那个nginx正在跑博客,这里就不实验了,后续记录老师的演示】
在nginx中对GEOIP进行配置
IP数据库解压目录
GeoLite2-Country.mmdb文件就是IP数据库文件,
在server同级目录中添加IP数据库配置
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {sendfile on;send_timeout 60;upstream stickytest{server 192.168.200.135:8080;}#配置IP数据库文件绝对路径geoip2 /opt/nginx/GeoLite2-Country_20231229/GeoLite2-Country.mmdb {#这个是获取国家的iso_code,后续会在location下使用这个变量写入响应头来观察效果$geoip2_country_code country iso_code;}server {listen 80;server_name localhost;location / {add_header country $geoip2_country_code;#add_header ETag "";#add_header Last-Modified "";add_header cache-control "max-age:300";#设置强制缓存300s有效期#expires 300s;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}配置效果
注意在本机部署测试这个地址是无法得到的,开梯子访问就会变成可能HK等其他地区,那些软件都只是更精确的IP数据库罢了,非常精确的数据需要使用商业版
通过获取用户的IP属地可以在nginx中做一些逻辑判断,将请求直接屏蔽掉并指向其他站点目录
同时在nginx对请求进行proxy_pass的过程中,我们可以将用户的IP属地信息响应给上游服务器,让上游服务器根据不同的用户属地做不同的判断
DNS服务器上对根据用户IP属地分配不同主机的配置
现在GEOIP不是特别的实用,因为现在大多想根据用户不同的ip属地分配到不同的主机上,这种需求其实现在可以在DNS服务器上实现
这里的配置意思:@指啥二级域名都不带的情况,访问来自联通的用户【默认不选就是所有请求,还可以区分国内国外和网络爬虫】被解析的站点【记录值】;如果自己搭建,IP数据库和爬虫服务器会经常变化,十天半个月就要更新一次,很麻烦,最好还是在DNS服务器上去配置IP属地【国内国外,因为这里没看到DNS服务器上有更细腻度的区分,因为这是个人免费版的解析,所以内容少,企业版就能区分国家地区的智能解析,另外DNS服务器也会分布的更广,海外也有,以上的方式其实价格相对于企业也不贵;更牛逼的高贵套餐还可以实现用户觉得官方的IP数据库不好,还可以在DNS服务器上自定义IP解析;只有对各个云服务商提供的DNS解析都不满意的情况下,就只能自己去使用GEOIP去做更深度的开发】和爬虫的相关配置
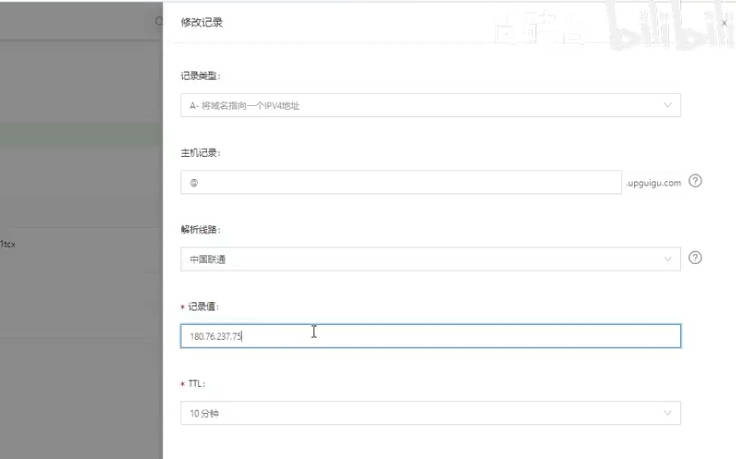
正向代理
📌本来说讲正向代理缓存,结果只讲了正向代理配置,没讲正向代理缓存;在反向代理缓存的最后补充了正向代理也可以像反向代理一样的方式配置正向代理缓存,配置的好处是相同的资源不用再去请求第二次了,可以直接缓存在Nginx正向代理服务器上直接使用。正向代理缓存的配置和反向代理缓存的配置是一模一样的,没有任何区别;很多人老是访问同一个资源,就将请求的资源缓存在nginx服务器本地,不需要再去上游服务器请求对应的资源浪费网络带宽;但是还是反向代理缓存比较常见
nginx的代理本质上不区分正向和反向代理,nginx代理总的来说全是用的proxy_pass关键字,只是像代理自家服务器就是反向代理,比如把自家服务器代理到第三方服务器如百度,就是正向代理【这里存疑,因为这里讲的正向代理是用户自己搭建来汇总自己的请求通过正向代理代替自己发起请求,而不是访问自己的nginx显示到对方的站点页面】
反向代理就是外网无法访问内网机器,用户通过统一的地址通过代理访问内网机器并做负载均衡,用户在使用过程感知不到反向代理服务器的存在,即客户端无需注意代理服务器;
正向代理需要客户端进行感知,比如公司的机器每一台都去配置正向代理服务器,这样就可以知道员工每天都上了什么网站,能够用来控制用户行为,网关服务器就是正向代理服务器,用户所有的请求都会通过网关转发到上游服务器,此外还有比如程序员在家办公,如果在公司的服务器前配置反向代理供程序员使用,此时所有的互联网用户都能访问,但是如果让居家办公的程序员在自己的电脑上配置一个代理服务器,通过该代理服务器连接到内网的机器【现在这些应用场景、跳板机、监控用户行为都有非常成熟的方案,监控网络行为路由器也可以做到,可以屏蔽用户访问某些站点的请求】,通过nginx正向代理服务器可以访问一些网络分段的资源,也有非常成熟的方案,比如shadowsocket【介绍的少是因为现在别的成熟方案很多,没必要使用nginx来做正向代理,而且nginx做正向代理用的很少】
nginx正向代理配置
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {sendfile on;send_timeout 60;server {listen 80;server_name localhost;#如果用户请求输入的是域名,nginx也是无法代理的,需要给nginx配置DNS服务器对域名进行解析获取IPresolver 8.8.8.8;location / {# $scheme是获取用户发起请求使用的协议变量,大部分是http的,像直播网站部分可能不是http的;三个拼接在一起其实就是用户访问的初始URL,这个URL是目标服务器的地址;有个问题,既然这个正向代理服务器配置在用户一侧,他是怎么连接到内网服务器的proxy_pass $scheme://$host$request_uri;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}此时需要访问nginx代理服务器来转发请求
如果使用nginx正向代理服务器的地址访问nginx,这时候nginx的proxy_pass会解析用户浏览器输入的地址,变成代理nginx代理服务器自己,就变成nginx递归访问自己,nginx发现这种情况会直接终止这种程序的执行并生成错误日志
显然通过浏览器地址栏输入nginx代理服务器的地址是不行的
需要在浏览器的配置中添加代理设置【chrome浏览器:设置----系统----打开您计算机的代理设置----设置使用代理服务器】
配置代理nginx正向服务器的IP和端口号,下面的框不用管是内网中的IP,勾选上不在内网【本地】中使用代理服务器
目前这种设置的正向代理服务器只能代理http请求
访问百度可能会转发http请求重定向到https,访问https是会失败的,访问https需要第三方模块,因为https的验证需要第三方参与,网络连接过程比较复杂;nginx开源版本没有实现那种比较复杂的网络连接方式,所以需要第三方模块
ngx_http_proxy_connect_module,官方git:https://github.com/chobits/ngx_http_proxy_connect_module,有兴趣可以配置一下,用的少,企业中的跳板机访问内网资源也不会使用nginx做正向代理服务器,已经有很成熟的产品了【了解一下jumpServer】nginx.conf配置
ngx_http_proxy_connect_modulexxxxxxxxxxserver {listen 3128;# dns resolver used by forward proxyingresolver 8.8.8.8;# forward proxy for CONNECT requestproxy_connect;proxy_connect_allow 443 563;proxy_connect_connect_timeout 10s;proxy_connect_read_timeout 10s;proxy_connect_send_timeout 10s;# forward proxy for non-CONNECT requestlocation / {proxy_pass http://$host;proxy_set_header Host $host;}}
反向代理缓存
起一台nginx服务器,启动一台上游tomcat服务器,nginx服务器中不保存静态资源【即无动静分离】,静态资源和动态资源都在tomcat服务器的根目录下,尝试测试用nginx将上游服务器的静态资源缓存到nginx服务器中
开启反向代理缓存,如果上游服务器实现资源静态化,没有开启反向代理缓存的情况下上游服务器需要整一个文件输出流将文件输出到nginx服务器上做缓存,但是开启反向代理缓存,这个输出流就不再需要了,nginx可以自动地将响应的结果自动缓存在本地磁盘
截至目前的Nginx完整配置
所有的配置前面都解释过,这里只是做一次完整备份
xxxxxxxxxxload_module "/usr/local/nginx/modules/ngx_http_brotli_filter_module.so";load_module "/usr/local/nginx/modules/ngx_http_brotli_static_module.so";worker_processes 1;events {worker_connections 1024;}http {concat on;concat_max_files 20;include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65 65;keepalive_time 1h;keepalive_requests 1000;send_timeout 60;upstream stickytest{keepalive 100;keepalive_requests 1000;keepalive_timeout 65;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {etag off;add_header ETag "";add_header Last-Modified "";expires 300s;add_header cache-control "max-age:300";if_modified_since off;ssi on;ssi_silent_errors on;gunzip on;gzip_static on;gzip on;gzip_buffers 16 8k;gzip_comp_level 6;gzip_http_version 1.1;gzip_min_length 150;gzip_proxied any;gzip_vary on;gzip_types text/plain application/x-javascript text/css application/xml;gzip_typestext/xml application/xml application/atom+xml application/rss+xml application/xhtml+xml image/svg+xmltext/javascript application/javascript application/x-javascripttext/x-json application/json application/x-web-app-manifest+jsontext/css text/plain text/x-componentfont/opentype application/x-font-ttf application/vnd.ms-fontobjectimage/x-icon;gzip_disable "MSIE [1-6]\.(?!.*SV1)";brotli on;brotli_static on;brotli_comp_level 6;brotli_buffers 16 8k;brotli_min_length 20;brotli_types text/plain text/css text/javascript application/javascript text/xml application/xml application/xml+rss application/json image/jpeg image/gif image/png;proxy_http_version 1.1;proxy_set_header Connection "";proxy_set_header X-Forwarded-For $remote_addr;proxy_pass http://stickytest;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}反向代理缓存配置
这个有点像自动化的动静分离,不需要自己再去将文件拷贝到nginx上了
反向代理服务器能根据客户的URL,针对URL对响应的资源做一份缓存,以用户的URL作为key,将上游服务器返回的结果存入nginx自身的磁盘,下次接到相同URL的请求,就直接去磁盘中找,找到了直接返回,没找到再去上游服务器获取;在对上游服务器文件缓存时,会设置一个过期时间让资源自动过期,资源过期以后会再次去上游服务器拉取,相当于自动化的将上游服务器的资源存到nginx磁盘上,更新更方便
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;upstream stickytest{server 192.168.200.135:8080;}#设置proxy_cache相关参数,/ngx_tmp是存临时文件的目录,inactive=1d表示在当前缓存文件的目录下文件最长能存多久,并不代表文件的过期时间proxy_cache_path /ngx_tmp levels=1:2 keys_zone=test_cache:100m inactive=1d max_size=10g ;server {listen 80;server_name localhost;location / {#配置proxy_cache使用nginx对响应资源缓存proxy_cache test_cache;#在响应头中添加Nginx-Cache观察缓存使用情况add_header Nginx-Cache "$upstream_cache_status";proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}效果
配置以后响应头参数
Nginx-Cache显示为Miss,表示缓存没有命中查看缓存文件目录
/usr/local/nginx/ngx_tmp已经创建,但是缓存文件目录中没有缓存文件,所以缓存没有命中,响应结果压根就没缓存,实际还缺少一行缓存过期时间配置proxy_cache_valid 168h;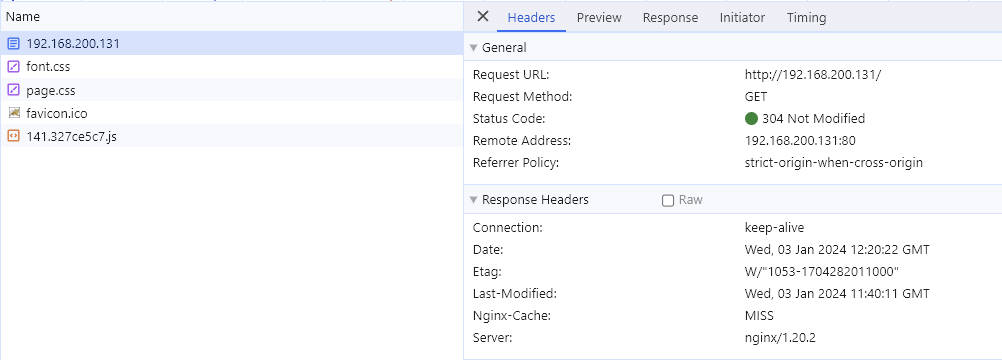
添加文件有效期的完整反向代理缓存配置
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;upstream stickytest{server 192.168.200.135:8080;}#设置proxy_cache相关参数,/ngx_tmp是存临时文件的目录绝对路径,inactive=1d表示在当前缓存文件的目录下文件最长能存多久,并不代表文件的过期时间,levels=1:2表示设置两级目录,第一级目录使用一个字符,第二级目录使用两个字符,还可以设置3级,分目录存储是为了查找方便,keys_zone是配置来给location中配置的proxy_cache指定属性值用的,表示可以使用该缓存目录下的缓存文件,100m是寻找文件需要使用索引可占用内存大小,就是缓存目录的文件名,这些索引是真实文件名的哈希值,这些索引存在内存中用来匹配请求文件名的哈希值,通过请求的URL可以找到对应的文件名哈希值即索引,快速获取文件位置并响应缓存文件,没有这个索引内存,nginx会通过请求的文件名计算出对应的哈希值并全盘扫描找该文件名对应的文件,每次请求都这样,速度就会比较慢proxy_cache_path /ngx_tmp levels=1:2 keys_zone=test_cache:100m inactive=1d max_size=10g ;server {listen 80;server_name localhost;location / {#配置proxy_cache使用nginx对响应资源缓存proxy_cache test_cache;#在响应头中添加Nginx-Cache观察缓存使用情况,用该变量把缓存命中状态写入响应头add_header Nginx-Cache "$upstream_cache_status";#配置缓存文件的过期时间,这个是第一次测试缓存后加的,不加这个响应文件压根就不会存入缓存目录,指的是nginx中没有对应URL的资源,向上游服务器请求之后何时再去请求上游服务器请求的时间,这个时间应该小于上面的inactive=1dproxy_cache_valid 23h;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}缓存使用效果
响应头中的参数
Nginx-Cache变成了HIT,hit表示缓存已经命中,注意这里不是动静分离,所有的响应包括框架都会被缓存在nginx服务器中,走浏览器缓存的就不会显示Nginx-Cache这个参数,连续清空缓存硬性加载才会显示HIT;主请求会发送协商请求,这个也会显示HIT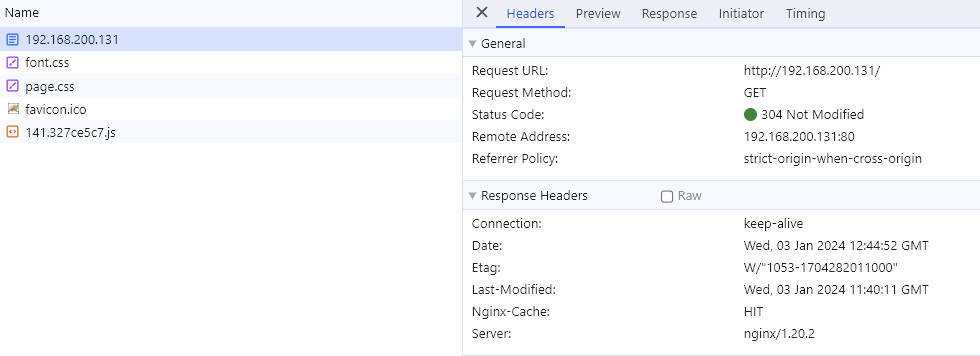
缓存文件目录树形结构
一级目录是一位数,二级目录是两位数,三级目录很长一串数是最终的文件,那一串数字是文件名的哈希值【是MD5算法算出来的值】
每个文件都有对应的路径,一个html、两个css和一个图标总共四个缓存文件
xxxxxxxxxx[root@nginx1 /]# tree /ngx_tmp//ngx_tmp/├── 0│ └── bb│ └── 64f92f094f7c9f64a8e1cadeabd2fbb0├── 5│ └── c2│ └── 944f86bf14cffc324fef290934798c25├── 7│ └── 2d│ └── 3c36817d87ce6ca8060bda47cc2d32d7└── a└── 18└── 40f19b55f9bd1d7192e85be8ca0b218a8 directories, 4 files
缓存文件内容
nginx在缓存文件的开头添加了内容,key就是请求URL;此外还有上游服务器返回的一些响应头信息
但是这种找文件的方式是通过内容查找的文件,因为压根不知道对应的文件名,页看不到内存中的索引信息,如果上游服务器的文件内容更新想要立即更新缓存文件,只能将整个临时目录全部删除,这种主动清空缓存的方式显然是无法接受的
xxxxxxxxxx[root@nginx1 /]# cat /ngx_tmp/0/bb/64f92f094f7c9f64a8e1cadeabd2fbb0¡eyًe^e汫qFW/"37-1703663993000"KEY: http://stickytest/page.cssHTTP/1.1 200Accept-Ranges: bytesETag: W/"37-1703663993000"Last-Modified: Wed, 27 Dec 2023 07:59:53 GMTContent-Type: text/cssContent-Length: 37Date: Wed, 03 Jan 2024 13:16:03 GMTConnection: closebody{background-color:#000;}
Proxy_cache配置参数
proxy_cache_max_range_offset参数值:
proxy_cache_max_range_offset number默认值:
——作用域:
http,server,location
作用是设置缓存上游服务器响应内容时,当内容的range达到设置值的情况下不对响应内容做缓存,比如一个两小时的视频可能只有前面5分钟看的人比较多【很多人可能看了前五分钟后面就不看了】,这时候只将视频的前5分钟缓存到nginx服务器中,后续的内容不做缓存,这样能节省磁盘空间,讲的不细啊这块
proxy_cache_use_stale参数值:
proxy_cache_use_stale error | timeout | invalid_header | updating | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | off默认值:
off作用域:
http,server,location
作用是配置当缓存文件过期后在什么条件下可以使用过期缓存,缓存过期以后正常情况下需要去上游服务器拉取新的响应,可以配置当向上游服务器拉取过程中发生了错误、超时、有不合法的响应头,以及各种异常响应码都可以配置继续使用本机已经过期的缓存文件【缓存文件删除的时间是由inactive参数配置的】
proxy_cache_background_update参数值:
proxy_cache_use_stale on | off默认值:
off作用域:
http,server,location
作用是配置当缓存文件过期后接受到请求直接响应过期缓存文件,同时再开启一个子请求去上游服务器拉取新的数据更新缓存,如果上游服务器出问题了可以配置参数
proxy_cache_use_stale一起使用proxy_no_cache参数值:
proxy_no_cache string ...默认值:
--作用域:
http,server,location
作用是配置指定哪些资源不进行缓存,比如一些请求需要携带用户的cookie或者jwt token令牌,让这些请求的响应结果不进行缓存,始终从上游服务器响应数据;这种一般配置在动态资源和静态资源混搭在一个location的情况在location中配置,实际上还可以针对静态资源和动态资源在不同的location中分开配置,直接配置静态资源开启反向代理缓存,动态请求不开启缓存,对部分特殊的动态请求在别的location下定制化的设置反向代理缓存规则,而不使用这种针对部分情况不使用缓存的配置
如果
proxy_no_cache后面配置的变量如果存在、不为空或者不等于0,则不对响应结果进行缓存【配置示例】
xxxxxxxxxxproxy_no_cache $cookie_nocache $arg_nocache$arg_comment;proxy_no_cache $http_pragma $http_authorization;proxy_cache_bypass参数值:
proxy_cache_bypass string ...默认值:
--作用域:
http,server,location
作用是配置配置在指定变量不为空或者不等于0的情况下响应的内容不从缓存中获取,这个和上面的参数
proxy_no_cache类似,但是含义不同,上一个是带参数的响应结果不进行缓存,这个参数的含义是有缓存也不使用【配置示例】
xxxxxxxxxxproxy_cache_bypass $cookie_nocache $arg_nocache$arg_comment;proxy_cache_bypass $http_pragma $http_authorization;proxy_cache_convert_head参数值:
proxy_cache_convert_head on | off默认值:
on作用域:
http,server,location
作用是配置当用户发起head请求时,也像get请求一样将上游服务器完整的内容拉取到nginx服务器并存入缓存文件,但是只响应给用户响应头信息;正常情况下用户发起head请求,上游服务器是不会响应给nginx响应体内容的。这种方式主要用户客户发起head请求后接下来可能很快就会对同一资源发起get请求的情况
get请求会同时响应响应体和响应头,HEAD请求只返回响应头,不会返回响应体;用postman可以发起head请求,在项目中也比较常见【比如想维持会话状态,是不是还在,向服务器发送head请求;像一些异步鉴权的操作,向接口发送head请求检查一下是否有权限去访问,而暂时不想获取响应的内容;即只想看能不能请求到,不想看内容的请求都可以发送head请求,比如看当前页面是否被更新,想看一下该请求的状态码,注意:对任何一个接口都可以发起head请求,只是响应体不响应了,响应头还是正常响应】
注意如果关闭需要在
proxy_cache_key中添加 $request_method 以便区分缓存内容【没讲,不是很懂这里,既然都全文拉取回来,难道不能自动处理不同请求方式下自动响应】proxy_cache_lock参数值:
proxy_cache_lock on | off默认值:
off作用域:
http,server,location
作用是配置当更新本机缓存的时候是否加锁,如果不加锁可以多线程竞争去覆盖旧缓存;当缓存文件失效后,瞬时请求可能有多个同时都去上游服务器请求资源且都带有更新缓存的任务,默认是不加锁的,因为加了锁会导致线程去竞争锁,造成响应变慢【不加锁可能导致瞬时请求获取的数据和缓存的数据不一致,加锁是为了数据的一致性,但是一般来说做缓存的数据对时效性要求不是特别高,所以一般默认情况下不加锁】
proxy_cache_lock_age参数值:
proxy_cache_lock_age time默认值:
5s作用域:
http,server,location
作用是配置当线程缓存更新锁超过预设时间还没有把响应结果更新成功就释放缓存更新锁,别的线程或者请求也可以去抢夺锁更新磁盘上的缓存文件
proxy_cache_methods参数值:
`proxy_cache_methods GET | HEAD | POST ...默认值:
GET HEAD作用域:
http,server,location
作用是配置反向代理缓存会缓存哪些请求方法的响应数据,默认是Head和Get,默认是不支持Post请求的
proxy_cache_min_uses参数值:
proxy_cache_min_uses number默认值:
1作用域:
http,server,location
作用是配置当请求达到指定次数以后才将响应内容缓存到nginx上,这种方式可以配置在高并发系统上来检测热点资源并对热点资源进行缓存,能减少高并发系统下缓存文件的数量
proxy_cache_path参数值:
proxy_cache_path path [levels=levels] [use_temp_path=on|off] keys_zone=name:size [inactive=time] [max_size=size] [min_free=size] [manager_files=number] [manager_sleep=time] [manager_threshold=time] [loader_files=number] [loader_sleep=time] [loader_threshold=time] [purger=on|off] [purger_files=number] [purger_sleep=time] [purger_threshold=time];默认值:
--作用域:
http
参数有点多,以后慢慢看,这里先记重点
作用是缓存文件相关的配置,path指缓存文件的存储目录【如果缓存目录已经快把磁盘写满了,但是此时又想要扩容磁盘,由于目录只能写一个,此时可以借助分级目录,将分级目录通过软连接的方式将目录挂载到其他磁盘】
levels=1:2设置目录层级以及目录名称位数,位数取的是md5的后几位,通过这个目录软连接可以把目录挂载到其他磁盘来实现缓存空间扩容,最初磁盘和服务器的性能较低的情况下一般使用tmpfs【类似一个虚拟的文件系统】将磁盘上的目录直接映射到内存里,表面向磁盘写数据实际上是向内存中写数据;现在不常用的原因是磁盘现在广泛的使用SSD了,服务器和操作系统的性能也还可以,同等容量的SSD的价格要远低于内存,一般就放SSD中;除非内存很冗余,想腾出几十个G出来做高速缓存就可以使用tmpfsuse_temp_path配置是否使用磁盘缓冲区,默认创建临时文件时,会先向磁盘缓冲区创建临时文件,等临时文件写完以后再改名移动到缓存目录下,默认是开启的,可以配置关闭inactive这个不是缓存文件的有效时间,而是超过该时间缓存文件没有被访问,缓存文件就会被删除掉,一方面有效期内到该时间没有被访问过,文件删除;另一方面,有效期过了以后没人访问,超过该时间没人访问过期缓存才会被自动删除掉proxy_cache_key参数值:
proxy_cache_key string默认值:
$scheme$proxy_host$request_uri作用域:
http,server,location
作用是配置缓存资源索引的对应key键值,通过该key去内存中查询对应的文件索引,设计的一定要有唯一性
proxy_cache_revalidate参数值:
proxy_cache_revalidate on | off默认值:
off作用域:
http,server,location
作用是当缓存资源过有效期的时候,向上游服务器发送
If-Modified-Since和If-None-Match来验证上游服务器文件是否发生更新【协商缓存】,如果没有就不需要重新下载资源了;这种方式能减少内网资源的消耗,特别是文件比较大的情况下【比如几个G的文件能瞬间把机器的网卡跑满,如果批量大文件失效会用尽内网的网络资源,设置缓存的时候就要避免文件批量失效导致同时更新,单个文件比较大就最好配置去检查一下文件是否有变化再去更新文件,内网带宽资源跑满了,连正常的proxy_pass代理上游服务器请求也发不过去了】
proxy_cache_valid参数值:
proxy_cache_valid [code ...] time默认值:
--作用域:
http,server,location
作用是配置缓存文件的过期时间,time是配置缓存文件的过期时间;code是配置状态码,根据响应的状态码来配置缓存文件的有效时间,即可以配置多个,不配置状态码默认是200, 301, 302
【配置示例】
xxxxxxxxxxproxy_cache_valid 200 302 10m;#301是重定向状态码proxy_cache_valid 301 1h;#any是其他任意状态码proxy_cache_valid any 1m;
Purger清理缓存
反向代理缓存文件要主动更新需要删掉已有的缓存文件,但是由于不知道文件名和哈希值的对应关系,无法手动实现上游服务器某个文件发生更新,在nginx上删除对应的缓存文件再重新拉取,这时候需要借助第三方模块purger的支持
这里一定要注意进入缓存文件目录再使用命令
rm -rf ./*删除缓存文件,千万别在根目录下执行该命令,这个缓存目录放的就不好,应该放在临时目录下purger的官方git:https://github.com/FRiCKLE/ngx_cache_purge【很老了,下载2.3版本】
安装Purger
将文件
ngx_cache_purge-2.3.tar.gz上传到/opt/nginx目录下,使用命令tar -zxvf ngx_cache_purge-2.3.tar.gz解压缩压缩包进入nginx的解压目录,使用命令
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --add-module=/opt/nginx/ngx_cache_purge-2.3 --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master进行预编译,没有报错使用命令make进行编译这里图省事加了很多其他模块的配置,自己根据需要删减或者增加即可
使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old4将老的nginx运行文件备份,使用命令cp /opt/nginx/nginx-1.20.2/objs/nginx /usr/local/nginx/sbin/nginx将新的nginx文件拷贝到nginx的安装目录在nginx中对purger进行配置
这里自定义了参数
proxy_cache_key $uri;,默认的该参数配置$scheme$proxy_host$request_uri,生成的key效果为http://stickytest/page.css,$proxy_host是upstream的名字,可以认为该参数实际读取的是proxy_pass的host部分;这个key必须和清理缓存站点的proxy_cache_purge的配置【此处配置是$1,表示uri中的第一个参数】相同,否则无法找到对应的缓存文件并删除该缓存文件自定义参数
proxy_cache_key $uri;的好处是不管访问的是http的资源,还是https的资源,或者通过各种域名访问到主机,一概不进行区分,只对访问的具体资源进行区分;这个对访问文件生成的key的协议和主机以及uri有影响,默认设置可能来自不同协议、域名等请求可能对同一份响应文件生成多个不同key的缓存文件,使用uri来作为key能够避免区分协议和不同的域名,相同的响应文件只生成同一份缓存文件proxy_cache_key $uri;还可以使用很多其他的变量,官方git举了一些例子【具体可用的参数课程没有讲过,自己总结】,比如proxy_cache_key $host$uri$is_args$args;【$is_args是判断是否有参数】,一旦修改了proxy_cache_key,proxy_cache_purge中的最后一个参数也要和key的形式保持一致xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;upstream stickytest{server 192.168.200.135:8080;}proxy_cache_path /ngx_tmp levels=1:2 keys_zone=test_cache:100m inactive=1d max_size=10g ;server {listen 80;server_name localhost;#额外添加一个location,实现和proxy_cache缓存文件反向的效果,访问某个资源带/purge起头的url能够清除对应url资源的缓存文件location ~/purge(/.*){#调用proxy_cache_purge去清理缓存区域test_cache[proxy_cache_path中的keys_zone]的缓存文件,$1指的是请求后面的uri除去/purge的部分proxy_cache_purge test_cache $1;}location / {proxy_cache test_cache;add_header Nginx-Cache "$upstream_cache_status";proxy_cache_valid 23h;#自定义缓存文件的key为请求的uriproxy_cache_key $uri;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}新生成的缓存文件内容
key已经变成uri了
xxxxxxxxxx[root@nginx1 ngx_tmp]# tree /ngx_tmp//ngx_tmp/├── 3│ └── 25│ └── 4ea8f60c18829c85e88bb2e92620a253├── 5│ └── 13│ └── 4cb14647de7a8b8654a4ae94f15a0135└── 9└── 7d└── 6666cd76f96956469e7be39d750cc7d96 directories, 3 files[root@nginx1 ngx_tmp]# cat 3/25/4ea8f60c18829c85e88bb2e92620a253ًe~eC5W/"25-1703663958000"KEY: /font.cssHTTP/1.1 200Accept-Ranges: bytesETag: W/"25-1703663958000"Last-Modified: Wed, 27 Dec 2023 07:59:18 GMTContent-Type: text/cssContent-Length: 25Date: Thu, 04 Jan 2024 09:46:48 GMTConnection: closebody{color:#fff;}在浏览器输入
192.168.200.131/purge/font.css测试清除该缓存文件这种方式适合单一文件更新后的缓存文件更新
【响应效果】
目录下对应资源的缓存文件已经没了,可以对该目录进行一个遍历,搞一个缓存文件列表,通过管理系统对缓存文件进行管理
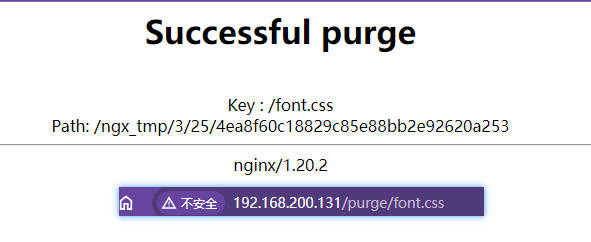
xxxxxxxxxx[root@nginx1 ngx_tmp]#tree /ngx_tmp//ngx_tmp/├── 3│ └── 25├── 5│ └── 13│ └── 4cb14647de7a8b8654a4ae94f15a0135└── 9└── 7d└── 6666cd76f96956469e7be39d750cc7d96 directories, 2 files测试其他形式的key的缓存文件和删除效果
【配置文件】
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;upstream stickytest{server 192.168.200.135:8080;}proxy_cache_path /ngx_tmp levels=1:2 keys_zone=test_cache:100m inactive=1d max_size=10g ;server {listen 80;server_name localhost;location ~/purge(/.*){#与proxy_cache_key保持一致proxy_cache_purge test_cache $host$1$is_args$args;}location / {proxy_cache test_cache;add_header Nginx-Cache "$upstream_cache_status";proxy_cache_valid 23h;proxy_cache_key $host$uri$is_args$args;proxy_pass http://stickytest;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【请求效果】
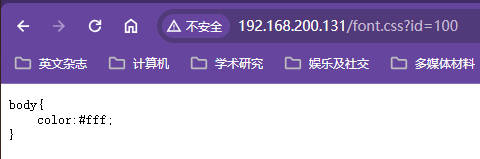
【缓存文件】
另一个文件是图标,key变成了
KEY: 192.168.200.131/font.css?id=100,这个$host是获取浏览器输入的host,$is_args是有参数就搞问号,没参数啥也不搞清除的时候也需要相同的添加了purge的相同host、uri和参数
📓这里面存在问题,前端为了不走浏览器缓存很可能在URL后面加时间戳,不同的时间戳还是请求的同一份资源,这时候nginx会认为这是全新的请求,从而对相同的资源再次生成全新的缓存文件。使用这种key很可能造成缓存冗余,消耗大量资源,降低检索效率,设置
proxy_cache_key一定要从资源的应用上出发,想清楚key的设置策略【比如动态参数会不会太大,太大了会生成海量的缓存文件,是否有必要这样设置key且合理设置缓存文件的有效时间,比如通过uri对前几页的数据列表进行缓存,并设置十几秒的有效时间,让nginx隔十几秒就去请求一次上游服务器的数据,对于数据不长期更新的可以设置的有效期更长一点,总之对动态的请求一定要根据每一个应用场景配置不同的location站点针对缓存资源内容、有效时间定制化的设置缓存文件规则;只给静态资源设置key只需要设置到uri即可;如果是加了随机数或者时间戳,这个参数是不重要的,也可以不将该参数设置为key】xxxxxxxxxx/ngx_tmp/├── 3│ └── 36│ └── 6fa206441fa760c8555c42922ff50363└── f└── 04└── 3a7bf6991c940d90a8503649bb60d04f4 directories, 2 files[root@nginx1 ngx_tmp]# cat 3/36/6fa206441fa760c8555c42922ff50363¿ƗeVًeOejҤvKW/"25-1703663958000"KEY: 192.168.200.131/font.css?id=100HTTP/1.1 200Accept-Ranges: bytesETag: W/"25-1703663958000"Last-Modified: Wed, 27 Dec 2023 07:59:18 GMTContent-Type: text/cssContent-Length: 25Date: Thu, 04 Jan 2024 10:07:11 GMTConnection: closebody{color:#fff;}通过PURGE请求方式删除缓存文件
官方文档对批量删除在
ngx_http_proxy_module有说明【这里面包含了缓存的全部配置,这里面的purge相关的配置都得依赖第三方purge模块,没有该模块这些配置无法使用】,此外还可以写脚本或者远程命令来删除缓存文件批量删除缓存文件没讲,后面自己了解
官方提供一种发送PURGE请求的方式来删除缓存文件,不再像之前配置location站点的方式来删除缓存文件
这种请求方式可以使用crul和postman来发送,能避免用户控制缓存的行为,postman默认就存在PURGE的请求方式
还有其他的缓存文件清理方式,用的比较少
xxxxxxxxxxproxy_cache_path /data/nginx/cache keys_zone=cache_zone:10m;#map相当于给某一个$purge_method赋值,如果请求方式为PURGE就给$purge_method赋值1,如果$purge_method为1就去执行proxy_cache_purge缓存文件清理,示例中的key取urimap $request_method $purge_method {PURGE 1;default 0;}server {...location / {proxy_pass http://backend;proxy_cache cache_zone;proxy_cache_key $uri;proxy_cache_purge $purge_method;}}
断点续传
HTTP请求的请求头参数range
断点续传要求有完整的Content-Length,流式传输是没有文件大小的
http请求的range,涉及到视频拖动进度条重新发起请求进行加载;多线程分块下载资源等这种需要标记指定从资源的某个位置开始下载资源,都需要在响应的响应头中添加range参数,请求的时候请求头中也要添加range参数
nginx默认是支持range的,但是tomcat服务器默认是不支持的【这里说的有问题吧,不管是直连tomcat还是通过nginx代理tomcat,tomcat也能使用range参数返回指定的字节】
nginx作为静态资源的应用场景比较多,比如做rtmp的资源文件服务器,基于HTTP协议的音视频点播【点播是资源文件事先就放在静态资源服务器上】;直播过程中不知道文件何时写完,在直播的过程中不断地向文件中进行追加,在响应资源的时候以Stream的形式对资源进行响应,播放器不知道资源啥时候传递完,播放器就会一直处于播放状态;有很多产品的音视频点播和直播都是使用的http协议的
带range的请求响应回来的状态码是206,表示Partial Content,返回部分内容
使用postman发起带range请求头参数的请求
nginx和tomcat都可以使用range参数获取指定字节范围的响应内容,不会响应全部内容
而且获取的是源文件的所有内容的指定字节范围,即html文件中的指定部分【可能返回注释中的内容或者标签内容】
【直连nginx上的资源】
Content-Type为Stream是看不到文件大小的,像下载过程中没有百分比,看不到大小的文件就是以stream的形式传输的,什么时候下载完毕取决于什么时候服务器不传递数据过来了
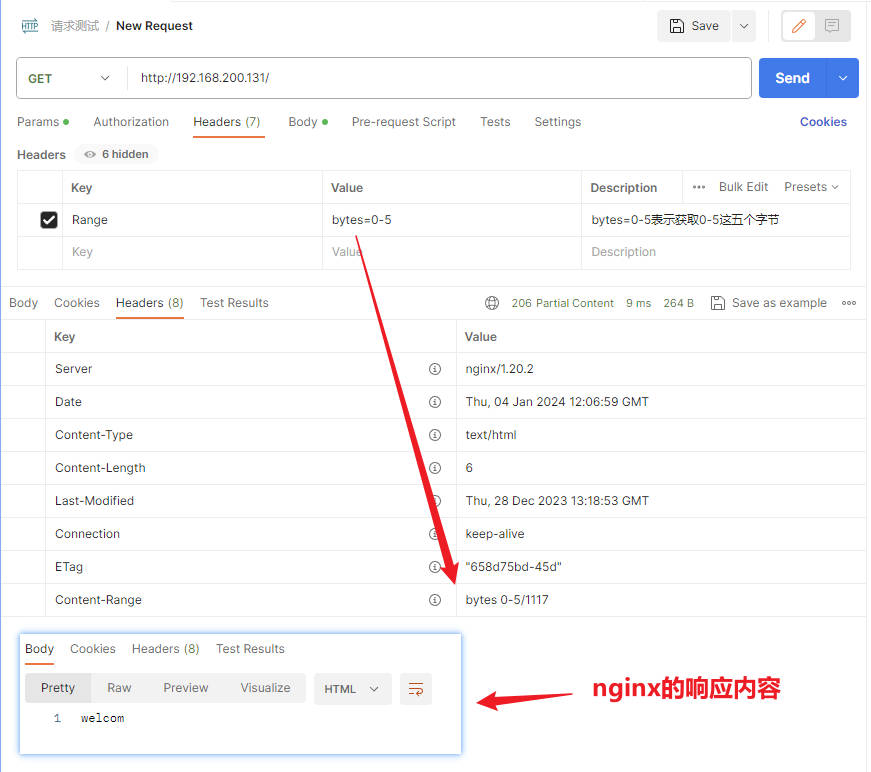
【通过nginx代理tomcat的资源】
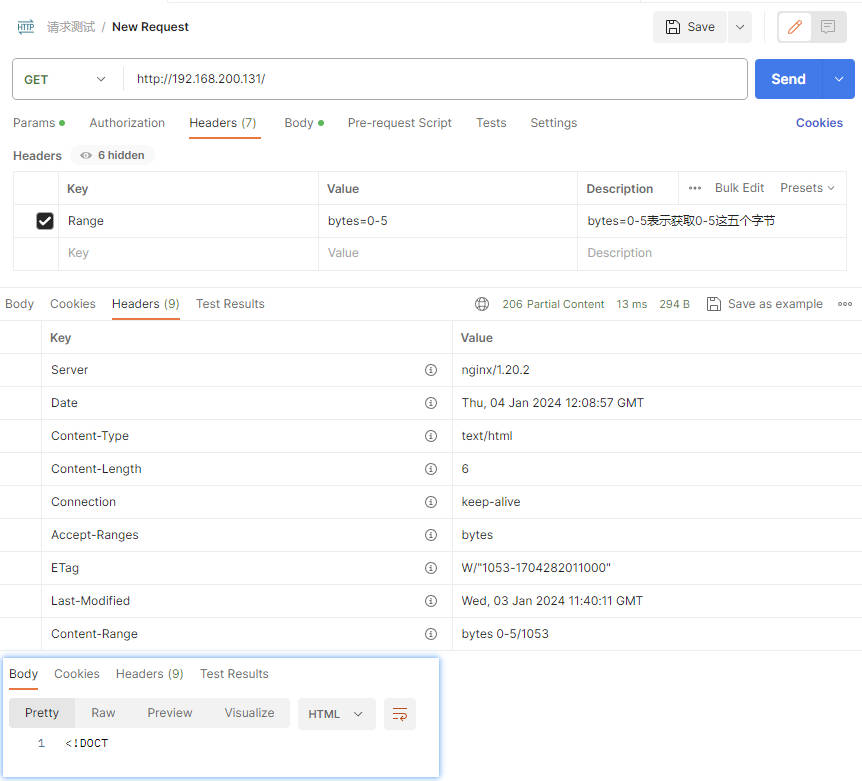
【直连tomcat上的资源】
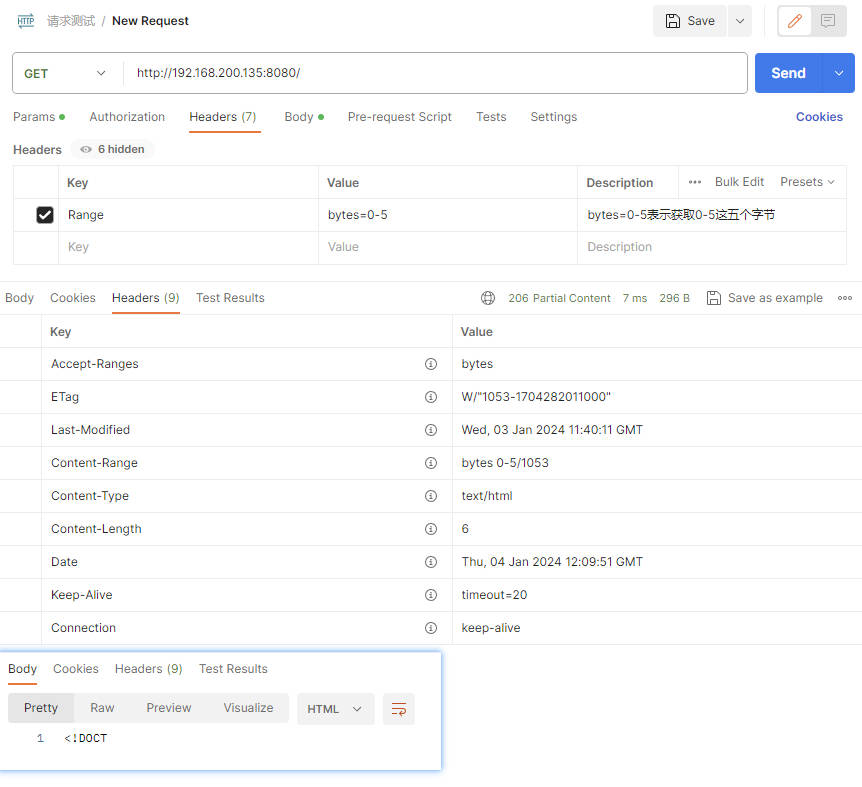
使用nginx做断点续传请求的时候需要设置请求头,在location中将range重新传递到新的请求头中
xxxxxxxxxxproxy_set_header Range $http_range
配置参数
proxy_cache_max_range_offsetproxy_cache_max_range_offset参数值:
proxy_cache_max_range_offset number默认值:
——作用域:
http,server,location
作用是设置缓存上游服务器响应内容时,当内容的range达到设置值的情况下不对响应内容做缓存【即range范围中的字节超过预设值就不对响应内容做缓存了】,比如一个两小时的视频可能只有前面5分钟看的人比较多【很多人可能看了前五分钟后面就不看了】,这时候只将视频的前5分钟缓存到nginx服务器中,后续的内容不做缓存,这样能节省磁盘空间,讲的不细啊这块;这个默认是没有设置的
对带range的响应做缓存,参数
proxy_cache_key中应该携带range的相关信息
内存缓存
Nginx内存缓存
Nginx内存缓存可以分为两个部分,第一个部分是Nginx内部访问本机磁盘上静态文件时对磁盘文件建立索引级别的内存缓存;在操作系统中访问一个文件并将文件发送出去需要访问文件句柄,在内存中建立缓存文件索引替代访问文件句柄的过程能高效的访问文件,文件索引缓存是不缓存文件内容的,内存中存储的是文件的源数据信息;第二个缓存是nginx进程间的共享级别缓存【nginx在启动后会创建多个进程】,在多进程的共享级别缓存中能够缓存文件内容,内存中存储的是文件的全量数据信息
两种缓存的明显区别是文件的数量和大小,索引缓存的文件如果用内存来缓存文件的全部内容,内存占用量是极大的,文件索引缓存适用于文件比较多,文件内容大的情况,快速查找文件和发送;多进程的共享级别缓存比较适合高频的数据访问,比如热点接口的响应数据,适用于数据量不大【像音视频就不行】的json数据【上游服务器的接口数据】或者被高频访问的静态资源
在内存缓存中想缓存全量数据光依靠nginx是很难办到的,一般配合OpenResty进行全量数据的内存缓存
还有sendfile的元数据内存缓存加速sendfile过程
外置内存缓存
Nginx内存缓存基于内存指的缓存会占用nginx这台机器的内存空间,甚至直接占用nginx的内存空间,单机扩容时非常容易遇到内存质的瓶颈,内存一旦占满,很难通过低廉的价格去提升内存的容量【128G扩展到256G的内存可能就需要更换支持该容量的主板,扩展到更大比如1/2T的内存可能整套设备都得更换】,可以通过外置缓存来解决硬件价格飙升的问题,增加额外的机器,通过网络来访问数据
外置内存缓存的解决方案现在都非常成熟,比如MemoryCache、Redis这两种缓存中间件都非常主流而且自身的可用性和功能都非常稳定可靠,外置内存缓存一台机器上的内存不够还可以部署集群;
如此大的内存空间一般用于缓存数据库表,增加数据库表的增删改查速度,最后定时的写入数据库;将后端的数据操作前置到内存中来,这些数据一般也是经常会被访问的热门数据,比如用户表、商品数据、权限数据等等;此时涉及到后端数据库与内存数据的同步问题,此时需要做多机的多写同步,用事务控制双写【既向缓存服务器中更新缓存数据,同时又向真正的数据库去存储数据,两个操作都成功才算是数据同步完成】来保证多机的数据一致性,通过这种双写的方式达到数据的一致性【?这是向内存操作的同时又向数据库操作吗?这样不是数据库还是系统的瓶颈吗?能不能内存中写,定时批量存入数据库呢】
外置缓存的应用非常多,java用redis集群存储热点数据,一般nginx连接的外置内存缓存的数据维护工作就不由nginx负责了,nginx一般只是访问外置内存缓存,当然一些简单的计数操作【比如nginx变成应用服务器做防火墙的时候可以检查用户的访问频次,针对每个用户都要记录访问次数,如果这个操作依靠上游tomcat服务器用java来做,这个操作的链路就比较长了,这种简单的操作就可以通过nginx来完成】;但是庞大的业务数据不会使用nginx来维护的
Nginx+MemCached
Memcached有很多不足,确实难用,redis的功能更加强大
Nginx+MemCached方案
nginx连接memcached的模块是不支持写入数据的,只支持读数据;写数据的工作只能放在上游服务器用一些api来做增删改查或者直接使用第三方工具telnet做增删改查
使用命令
yum install -y memcached安装memcached,并使用命令systemctl start memcached启动memcachedmemcached包括依赖一起只有几百kB,非常小巧;memcached不向redis一样有像mysql一样有linux客户端,要连接memcache需要使用工具memcached-tool,这个工具也无法对memcached做增删改查工作,只是连上memcached看一下运行状态
使用命令
memcached-tool 127.0.0.1:11211 stats使用memcached-tool连接memcached,memcached的默认端口是11211会显示memcached的一些运行信息
xxxxxxxxxx[root@nginx1 ~]# memcached-tool 127.0.0.1:11211 stats#127.0.0.1:11211 Field Valueaccepting_conns 1auth_cmds 0auth_errors 0bytes 0bytes_read 33bytes_written 54cas_badval 0cas_hits 0cas_misses 0cmd_flush 0cmd_get 0cmd_set 0cmd_touch 0conn_yields 0connection_structures 11curr_connections 10curr_items 0decr_hits 0decr_misses 0delete_hits 0delete_misses 0evicted_unfetched 0evictions 0expired_unfetched 0get_hits 0get_misses 0hash_bytes 524288hash_is_expanding 0hash_power_level 16incr_hits 0incr_misses 0libevent 2.0.21-stablelimit_maxbytes 67108864listen_disabled_num 0pid 1918pointer_size 64reclaimed 0reserved_fds 20rusage_system 0.028524rusage_user 0.020374threads 4time 1704539183total_connections 12total_items 0touch_hits 0touch_misses 0uptime 424version 1.4.15使用命令
yum install -y telnet安装telnet使用命令
telnet 127.0.0.1 11211使用telnet连接memcached使用telnet可以直接对memcached做增删改查操作
【连接效果】
xxxxxxxxxx[root@nginx1 ~]# telnet 127.0.0.1 11211Trying 127.0.0.1...Connected to 127.0.0.1.Escape character is '^]'.
Telnet对memcached的操作
telnet操作时万一写错了需要使用
ctrl+backspace来删除写错的字符退出telnet需要使用命令
quit,千万别按Ctrl+c,这个不仅不能退出客户端还会导致无法删除的乱码使用set命令向memcache中添加键值对
如果没有对应的key就新增,如果有对应的key就覆盖值
telnet的键值对设置要分两行完成,第一行为key,第二行为value,设置key的同时还要跟上键值对的其他信息
xxxxxxxxxx#keyName是键值对的key,第一个参数是键值对的元数据信息,第二个参数是键值对的过期时间,设置为0表示永不过期,第三个参数是value的字节数;#输完以上三个参数会自动的换行,此时需要输入键值对的value,如果value的字节数和预设的字节数对不上会报错;如果字节数和预设值相同则会提示stored表示数据存储成功set keyName 0 0 3yiming#输入的value超过3个字节报错CLIENT_ERROR bad data chunkERRORset keyName 0 0 3123#输入的value符合要求表示已经存储STORED使用get命令从memcache中获取数据
xxxxxxxxxxget keyName#响应命令,元数据信息和value都能够显示出来VALUE keyName 0 3123END
使用nginx连接memcached
官方文档对连接memcached的介绍:http://nginx.org/en/docs/http/ngx_http_memcached_module.html,这个模块好像是默认自带的,没有添加任何额外的模块就能直接配置使用
nginx对memcached的配置
如果没有从memcached中找到对应的响应数据会直接报错404,如果发生了404我们希望nginx能用错误页接管这个错误,将这个请求用proxy_pass代理到上游服务器中去获取对应的响应数据并将响应数据存入memcached以供用户下次请求直接响应,同时将请求结果返回给nginx,即用反向代理将404处理成反向代理请求上游服务器的操作
xxxxxxxxxxupstream backend {server 192.168.44.104:8080;}location / {#如果请求到对应的内容就会走以下流程,以请求信息组成key去访问memcached,获取到缓存memcached中的响应内容,将响应头缓存信息改为命中,以文本的形式发送给浏览器进行响应#期望将当前响应给用户的信息从事先存入缓存memcached中直接取出,以用户请求的uri?参数args作为key#http://concurrency.cn/index.html?id=100,其中/index.html?id=100就是这里设置的key即$uri?$args部分,注意这里设置的key是用于从memcached中直接取响应结果的,向memcached中设置对应key和value需要在上游tomcat服务器中去完成#如果通过这个key到memcached中找到该资源,就不再去上游服务器发送请求了set $memcached_key "$uri?$args";#这个是设置memcached的地址,默认会用上一行的key去请求memcached,获取对应的响应内容memcached_pass 127.0.0.1:11211;#拿到内容将缓存状态设置为命中add_header X-Cache-Satus HIT;#并以文本的格式让浏览器进行响应add_header Content-Type 'text/html; charset=utf-8'; #强制响应数据格式为html}nginx对请求memcache缓存找不到资源的404错误处理的错误页配置
xxxxxxxxxxupstream backend {server 192.168.44.104:8080;}location / {set $memcached_key "$uri?$args";memcached_pass 127.0.0.1:11211;add_header X-Cache-Satus HIT;add_header Content-Type 'text/html; charset=utf-8'; #强制响应数据格式为html}error_page 404 = @fallback;location @fallback{#请求上游服务器的时候携带请求头,上游服务器能从请求头中获取到对应的uri信息,注意这里不能使用set_headerproxy_set_header memcached_key $memcached_key;#处理404错误将请求转发到上游tomcat服务器,这配置有问题吧,遇到404错误全部按某个业务的逻辑去进行处理proxy_pass http://192.168.44.104:8080;}【响应效果】
从请求头信息中获取到了对应的key信息,这里只是表示nginx能成功转发到tomcat服务器并获取到对应的key设定值
使用telnet向memcached中添加对应key为/?的键值对,value为12345模拟tomcat服务器向memcached存入数据,再使用nginx访问对应的键值对
实际上业务程序就是在返回结果上添加一个注解的事,存入memcached同时还会响应给请求方
【添加缓存】
xxxxxxxxxxset /? 0 0 512345STORED【nginx成功使用缓存的效果】
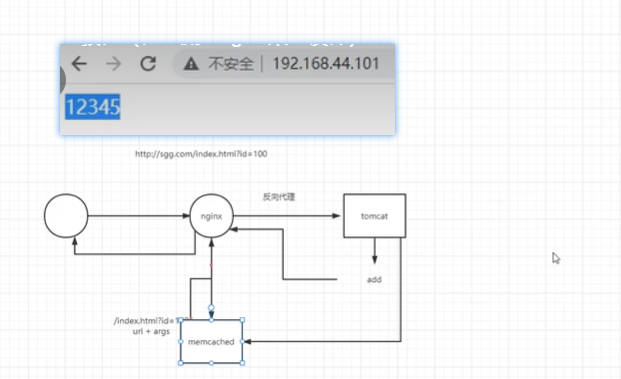
Nginx+Redis
Redis比memcache的流行程度更高,功能强大,性能不低,非常哇塞的缓存中间件
Nginx可以通过插件化的第三方模块
redis2-nginx-module去连接Redis,redis2-nginx-module【这里的redis的2指的是协议2.0,不是版本2.0】是一个支持 Redis 2.0 协议的 Nginx upstream 模块,它可以让 Nginx 以非阻塞方式直接访问远方的 Redis 服务,同时支持 TCP 协议和 Unix Domain Socket 模式,并且可以启用强大的 Redis 连接池功能。
redis2-nginx-module模块的官方文档:https://github.com/openresty/redis2-nginx-module,可以看出这个模块是OpenResty开发的,OpenResty是中国人开发的,官方文档比较好懂,同时OpenResty默认集成了Lua git,即使用OpenResty可以在配置文件中去执行lua代码nginx对redis2的官方介绍:https://www.nginx.com/resources/wiki/modules/redis2/
nginx读取redis数据最关键的点就是连接池,只要支持连接池,连接可以复用,读取性能就还不错
使用lua开发的Redis或者Memcache客户端功能还会更强大,定制化程度更高;因为目前使用的都是c语言实现的缓存中间件,除非是精通C语言做起来才会好一些;其他语言开发者去写C语言程序就会很困难。Redis还有一个Lua Resty,在resty包下的redis包,官方也推荐使用
lua-resty-redis【也是OpenResty项目下的】来做nginx访问redis的客户端
使用命令
yum install epel-release更新yum源关于源的这部分基本都没讲过,以后自己研究
使用命令
yum install -y redis安装redisyum安装的坏处是软件的版本可能比较老,只是安装比较方便,但是redis的协议没怎么变化,不影响使用对应协议第三方模块
redis2-nginx-module的效果我的机器上早就编译安装了redis6.2.13,在已经安装了redis的情况下,本机安装的都是最初的redis6.2.13,并修改了环境变量的情况下,在使用
yum install -y redis安装的redis使用命令systemctl start redis由于没有指定配置文件,环境变量会采用系统的环境变量【这里由于我忘了原来的redis安装在/usr/local/bin目录下,重新使用yum安装了,但是发现启动不起来,就是因为原来环境变量设置的版本和yum安装的版本不一致,而且我找不到yum安装的redis的配置文件,就直接使用命令yum remove redis将yum安装的redis卸载了,使用早安装的redis6.2.13;还有一个启动不起来的原因是/usr/lib/systemd/system/redis.service中的权限问题,使用命令vim /usr/lib/systemd/system/redis.service,将用户和组改为User=root Group=root,然后使用命令systemctl daemon-reload重新加载系统服务,使用命令systemctl start redis启动,我这里改了报错就变成了环境变量不匹配的问题了,也是从不匹配的问题发现我之前已经安装了redis】配置文件
/etc/redis.conf是我从/opt/redis-6.2.13目录下拷贝过去的,为了方便后台启动使用,其中更改了配置daemonize yes,原配置是daemonize no,表示以后台的方式启动因为我本机安装了redis且修改了redis的环境变量,直接使用命令
redis-server /etc/redis.conf就可以后台启动redis
在https://github.com/openresty/redis2-nginx-module/tags下载模块
redis2-nginx-module,这里与课程一致下载0.15版本,上传至linux的/opt/nginx目录下使用命令
tar -zxvf redis2-nginx-module-0.15.tar.gz解压压缩包进入nginx的安装目录,使用命令
./configure --prefix=/usr/local/nginx/ -add-module=/opt/nginx/redis2-nginx-module-0.15进行预编译,然后使用命令make实际不要直接用这个命令,要根据实际添加的模块来进行自定义该命令,实际我这里使用的是
./configure --with-compat --add-dynamic-module=/opt/nginx/ngx_brotli-1.0.0rc --prefix=/usr/local/nginx/ --add-module=/opt/nginx/redis2-nginx-module-0.15 --add-module=/opt/nginx/nginx-goodies-nginx-sticky-module-ng-c78b7dd79d0d --add-module=/opt/nginx/ngx_cache_purge-2.3 --with-http_gzip_static_module --with-http_gunzip_module --add-module=/opt/nginx/nginx-http-concat-master使用命令
mv /usr/local/nginx/sbin/nginx /usr/local/nginx/sbin/nginx.old5将老nginx运行文件备份,在nginx的解压目录的objs目录下使用命令cp objs/nginx /usr/local/nginx/sbin/将编译好的nginx拷贝到nginx的安装目录并重启nginx
使用命令
systemctl start redis启动redis,使用命令redis-cli登录默认的6379客户端。如果redis的端口修改成了XXX,则需要使用命令redis-cli -p XXX登录客户端在nginx的配置文件中添加对redis连接的支持配置
表示访问URL:http://192.168.200.131/foo会执行以下操作去redis中执行指令
set one first通过nginx的配置可以直接从redis中读取并且还可以向redis中写入数据
xxxxxxxxxxlocation = /foo {#这个和配置memcached的add_header Content-Type 'text/html; charset=utf-8';效果是一样的,使用default_type也会将后面的内容自动添加到响应头的Content-Type的参数里default_type text/html;#如果redis设置了密码,可以通过设置改参数进行认证操作,没讲具体实现,自己学习一下redis2_query auth 123123;#设置了一个自定义变量,变量的值设置为firstset $value 'first';#用redis2_query去执行查询,set是指查询过程中执行set操作,值为$value即first,key为oneredis2_query set one $value;#将上述命令使用redis2_pass发送给redis,redis2_pass后面跟的是redis的地址redis2_pass 192.168.199.161:6379;}在浏览器输入
http://192.168.200.131/foo【响应效果】
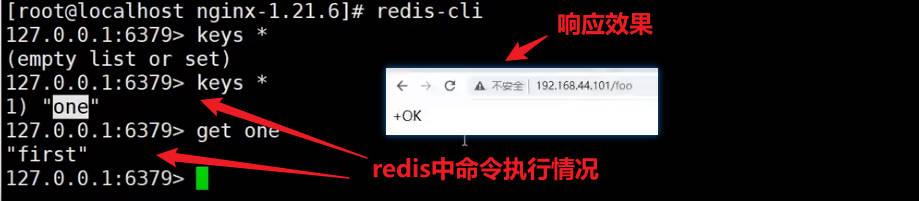
在nginx的配置文件中添加读取redis数据的配置
xxxxxxxxxxlocation = /get {#使用default_type也将后面的内容自动添加到响应头的Content-Type的参数里default_type text/html;#用redis_pass发送请求到服务器地址redis2_pass 192.168.200.131:6379;#安全认证redis2_query auth 123123;#set_unescape_uri是第三方模块,能将uri编码重新转义,尤其是当uri中有特殊字符的时候,作用是将uri中的特殊字符给转义回来#$arg_key是nginx的内部变量,arg表示参数,key是其中一个参数的参数名,会将该参数的参数值取出来,并赋值给自定义参数$key#这个配置需要安装第三方模块ngx_set_misc,一样下载编译安装;这里为了方便不下载该模块进行参数赋值,直接用nginx的内部变量去发送redis指令#set_unescape_uri $key $arg_key;#用redis2_query去执行redis指令get $key#redis2_query get $key;#为了方便不安装模块ngx_set_misc,直接在该配置中使用nginx内部变量redis2_query get $arg_key;}在浏览器输入
http://192.168.200.131/get观察响应效果响应处理期间发生问题会在浏览器显示$-1,原因是该uri没带参数,nginx拿不到对应的参数
在浏览器输入
http://192.168.200.131/get?key=one观察响应效果在redis中找不到对应key的数据也会响应$-1,找到了会显示$5并展示对应的value
除了以上展示的添加键值对,通过key查询值以外,还有其他很多的其他配置,功能远远高于nginx连接memcached的功能,在官方文档中https://github.com/openresty/redis2-nginx-module有很详细的介绍。readme.md就是官方文档
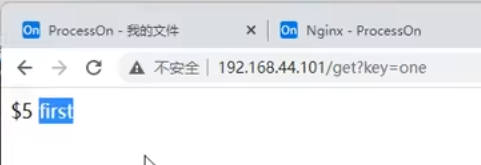
其他redis的配置方式
此外,如果还可以在nginx中配置连接池,访问redis的过程中复用连接池
此外还可以配置
redis2_connect_timeout连接超时、redis2_send_timeout发送时间超时、redis2_read_timeout是快速失败的配置、redis2_buffer_size是读取redis数据的时候的数据缓冲大小【提示了不需要配置太大,默认大小是内存一个页的大小,根据操作系统是4k或者8k】、redis2_next_upstream是做容错用的,如果第一个没搞定就去使用第二个、Selecting Redis Databases是切换redis中的数据库、还有lua相关的支持、此外还有发布订阅功能,都在官方文档上有介绍,功能非常丰富pipelined
redis支持pipelined【一个连接复用,一个连接上一次性执行多条命令】,一次发送很多的redis命令去执行返回结果,但是因为redis是单线程的不会并行执行,会按照顺序一个一个的执行
xxxxxxxxxx# multiple pipelined querieslocation = /foo {set $value 'first';redis2_query set one $value;redis2_query get one;redis2_query set one two;redis2_query get one;#redis_pass是直接向redis中发请求redis2_pass 127.0.0.1:6379;}raw query
可以将本来只能在redis命令行里输入的命令,在nginx中以字符串的形式传递给redis,让redis来帮忙执行
主要是键盘的操作可以通过字符串的形式带到命令的执行过程中
xxxxxxxxxxlocation = /bar {# $ is not special here...#发送一个ping,正常情况下返回一个pang,redis2_literal_raw_query不能使用变量,即$符号会单纯地认为是一个字符而不会认为是一个变量redis2_literal_raw_query '*1\r\n$4\r\nping\r\n';redis2_pass 127.0.0.1:6379;}location = /bar {# variables can be used below and $ is special#\r\n相当于敲了一个回车redis2_raw_query 'get one\r\n';redis2_pass 127.0.0.1:6379;}raw query从uri中获取redis命令字符串并通过nginx传递给redis
获取参数部分不含问号的所有字符串【整个参数部分是redis命令】,并赋值给变量$query,将该命令传递给redis执行,即通过浏览器地址栏输入对数据的操作命令
xxxxxxxxxx# GET /baz?get%20foo%0d%0alocation = /baz {set_unescape_uri $query $query_string; # this requires the ngx_set_misc moduleredis2_raw_query $query;redis2_pass 127.0.0.1:6379;}lpush
可以在nginx的配置文件中使用redis的lpush命令
xxxxxxxxxxlocation = /init {#先将key1的键值对删掉redis2_query del key1;redis2_query lpush key1 C;redis2_query lpush key1 B;redis2_query lpush key1 A;redis2_pass 127.0.0.1:6379;}lrange
可以在nginx的配置文件中使用redis的lrange命令
xxxxxxxxxxlocation = /get {redis2_query lrange key1 0 -1;redis2_pass 127.0.0.1:6379;}复用连接池
xxxxxxxxxxhttp {upstream backend {server 127.0.0.1:6379;# a pool with at most 1024 connections# and do not distinguish the servers:#连接池直接在upstream中用keepalive配置保持多少个连接,请求的时候就会复用这些连接,效率优化会很明显keepalive 1024;}server {...location = /redis {set_unescape_uri $query $arg_query;redis2_query $query;redis2_pass backend;}}}redis集群配置
xxxxxxxxxxupstream redis_cluster {server 192.168.199.161:6379;server 192.168.199.161:6379;}location = /redis {default_type text/html;redis2_next_upstream error timeout invalid_response;redis2_query get foo;redis2_pass redis_cluster;}
应用缓存
上级tomcat应用服务器的缓存,java本身就做了一层缓存,java内存中的对象,静态变量都不需要用户进行管理,这些缓存数据在内存中可以直接用【经典的单例模式就是,把高频访问的数据放在单例中,这是静态缓存,还没聊到JVM这一层】,java内部还可以通过ehcache或者谷歌的guava第三方组件组建JVM级别的内存【JVM堆外内存】,tomcat也可以去访问第三方的缓存中间件
Sendfile性能优化
Strace工具
Strace号称追踪linux内核的神器,可以看到操作系统进程在操作系统上都干了什么事情,默认情况下在mini版的linux系统下是未安装的,使用命令
yum install -y strace安装Strace
Strace的使用
使用命令
strace -p 进程号监控nginx进程监控的是nginx的worker工作线程
命令卡在nginx通过epoll去等待事件来唤醒nginx的执行
xxxxxxxxxx[root@nginx1 ngx_tmp]# ps -ef|grep nginxroot 16044 1 0 1月04 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.confnobody 16045 16044 0 1月04 ? 00:00:00 nginx: worker processroot 39093 2118 0 04:37 pts/0 00:00:00 grep --color=auto nginx[root@nginx1 ngx_tmp]# strace -p 16045strace: Process 16045 attachedepoll_wait(8,通过浏览器访问nginx观察监控效果
nginx重新加载后老的worker进程没了
自己测试要响应200才行,304没有读文件的操作,只是检查了一下文件元数据的信息
通过Strace观察sendfile的过程,此时没有使用nginx做代理,主要观察一下nginx对请求的响应过程
xxxxxxxxxx[root@nginx1 ngx_tmp]# strace -p 16045strace: attach: ptrace(PTRACE_SEIZE, 16045): 没有那个进程[root@nginx1 ngx_tmp]# ps -ef |grep nginxroot 16044 1 0 1月04 ? 00:00:00 nginx: master process /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.confnobody 40029 16044 0 04:57 ? 00:00:00 nginx: worker processroot 40041 2118 0 04:58 pts/0 00:00:00 grep --color=auto nginx[root@nginx1 ngx_tmp]# strace -p 40029strace: Process 40029 attached#nginx通过epoll等待用户的请求,第一个请求的过程没有经历内存拷贝,即没有经历用户态,直接找到文件一个sendfile将文件响应出去的,如果将文件元数据缓存起来,可以不经过stat和open这个过程,直接把元数据信息给sendfile,sendfile可以直接向内核发送写请求,直接将文件写到网络接口直接发送出去epoll_wait(10, [{EPOLLIN, {u32=2351931888, u64=140263098917360}}], 512, 29182) = 1#来了一个HTTP请求,获取到http请求的头信息recvfrom(3, "GET / HTTP/1.1\r\nHost: 192.168.20"..., 1024, 0, NULL, NULL) = 535#stat就是根据请求的url开始找请求的资源了stat("/usr/local/nginx//html/index.html", {st_mode=S_IFREG|0644, st_size=936, ...}) = 0#open是开始打开文件open("/usr/local/nginx//html/index.html", O_RDONLY|O_NONBLOCK) = 7#fstat是返回已打开的文件,并获取到linux内核的相关参数fstat(7, {st_mode=S_IFREG|0644, st_size=936, ...}) = 0#以下操作是带缓存式的写数据,写完一个sendfile文件就响应给客户端,sendfile发送写请求给内核将数据写到网络接口响应给用户writev(3, [{iov_base="HTTP/1.1 200 OK\r\nServer: nginx/1"..., iov_len=238}], 1) = 238sendfile(3, 7, [0] => [936], 936) = 936#这个是网络接口向ip地址写数据write(8, "192.168.200.1 - - [05/Jan/2024:0"..., 210) = 210#这个是把写操作给关掉close(7) = 0#这里就开始等待下一次请求了,还接到一次请求是favicon.ico,获取网站的图标epoll_wait(10, [{EPOLLIN, {u32=2351931888, u64=140263098917360}}], 512, 24625) = 1recvfrom(3, "GET /favicon.ico HTTP/1.1\r\nHost:"..., 1024, 0, NULL, NULL) = 479open("/usr/local/nginx//html/favicon.ico", O_RDONLY|O_NONBLOCK) = -1 ENOENT (没有那个文件或目录)write(9, "2024/01/05 04:58:39 [error] 4002"..., 265) = 265writev(3, [{iov_base="HTTP/1.1 404 Not Found\r\nServer: "..., iov_len=155}, {iov_base="<html>\r\n<head><title>404 Not Fou"..., iov_len=100}, {iov_base="<hr><center>nginx/1.20.2</center"..., iov_len=53}, {iov_base="<!-- a padding to disable MSIE a"..., iov_len=402}], 4) = 710write(8, "192.168.200.1 - - [05/Jan/2024:0"..., 243) = 243epoll_wait(10,观察没有sendfile的Strace监控效果
在nginx的配置文件关闭sendfile功能后再次请求
开启sendfile能够极大地优化系统性能,目前还没有配置任何的nginx服务器上的缓存
xxxxxxxxxx[root@nginx1 ngx_tmp]# strace -p 41273strace: Process 41273 attachedepoll_wait(10, [{EPOLLIN, {u32=2351931888, u64=140263098917360}}], 512, 39825) = 1#接收请求recvfrom(4, "GET / HTTP/1.1\r\nHost: 192.168.20"..., 1024, 0, NULL, NULL) = 535#找文件的元数据信心stat("/usr/local/nginx//html/index.html", {st_mode=S_IFREG|0644, st_size=936, ...}) = 0#打开文件open("/usr/local/nginx//html/index.html", O_RDONLY|O_NONBLOCK) = 8fstat(8, {st_mode=S_IFREG|0644, st_size=936, ...}) = 0#pread64是一个升级版的read函数,表示开始读文件了,引号中是读取到的内容,如果开了sendfile是不会有这个操作的pread64(8, "welcome nginx!I'm 192.168.200.13"..., 936, 0) = 936#这个write的过程中没有sendfile过程的出现了,没有向内核发送sendfile函数让内核去发送文件了,而是预先有一个pread64的操作writev(4, [{iov_base="HTTP/1.1 200 OK\r\nServer: nginx/1"..., iov_len=238}, {iov_base="welcome nginx!I'm 192.168.200.13"..., iov_len=936}], 2) = 1174write(3, "192.168.200.1 - - [05/Jan/2024:0"..., 210) = 210close(8) = 0epoll_wait(10, [{EPOLLIN, {u32=2351931888, u64=140263098917360}}], 512, 36631) = 1recvfrom(4, "GET /favicon.ico HTTP/1.1\r\nHost:"..., 1024, 0, NULL, NULL) = 479open("/usr/local/nginx//html/favicon.ico", O_RDONLY|O_NONBLOCK) = -1 ENOENT (没有那个文件或目录)write(7, "2024/01/05 05:25:30 [error] 4127"..., 265) = 265writev(4, [{iov_base="HTTP/1.1 404 Not Found\r\nServer: "..., iov_len=155}, {iov_base="<html>\r\n<head><title>404 Not Fou"..., iov_len=100}, {iov_base="<hr><center>nginx/1.20.2</center"..., iov_len=53}, {iov_base="<!-- a padding to disable MSIE a"..., iov_len=402}], 4) = 710write(3, "192.168.200.1 - - [05/Jan/2024:0"..., 243) = 243epoll_wait(10,
Sendfile调优
Nginx配置sendfile的
open_file_cache系列优化参数以下参数需要配置在对应资源的站点location下
主要的意义就是在开启sendfile的基础上进一步的缓存文件元数据信息进一步地提升sendfile的性能
默认情况下系统是没有开启这个功能的,这个功能也是nginx调优比较重要的方法,具体的参数设置还是要根据具体的系统应用来考虑
散碎的小文件可以将文件全文存放到nginx的内存中,来获取比sendfile更高的性能;但是文件过多或者单个文件过大就不适合放在内存中,sendfile做磁盘文件的读写对大文件来说是非常有优势的【因为大文件的顺序读写速度是很快的,包括机械硬盘和固态硬盘上都是如此】,对小文件来说优势不是特别明显;但是大文件放内存性价比就不高了
sendfile加open_file_cache配置做内存式的索引和磁盘式的存储适合文件多、单个文件比较大的传统存储情况;内存式的存储适合内容不太大的热点数据存储xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;upstream stickytest{server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {#这个配置在sendfile关闭的情况下没有太大意义,主要就是给sendfile使用的#该max配置表示具体能缓存500个文件句柄,可以多配置一些,不会占用太多内存;inactive是前后两次访问时间间隔超过设置的60s,就会把句柄从缓存中剔除出去,如果句柄缓存满了,系统会使用LRU算法根据访问量少和存在时间较长的句柄数据自动剔除掉,保证句柄最多不超过设置的上限open_file_cache max=500 inactive=60s;#配置一个资源访问量达到多少次以后才建立句柄【应该是元数据吧,看老师说的意思应该就是元数据信息】缓存open_file_cache_min_uses 1;#如果文件发生了变化,但是缓存数据没有更新无法更新新的数据,该参数配置每隔60s去检查缓存元数据对应的文件是否发生更改,如果发生了变化就将文件的元数据重新构建一次open_file_cache_valid 60s;#找文件元数据过程中发生了错误,会将错误信息也进行缓存,比如一个文件找不着,这时候会把找不着的错误信息也缓存,避免下次相同请求还去找open_file_cache_errors on;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}Strace跟踪结果
【对sendfile优化配置后第一次请求】
xxxxxxxxxx[root@nginx1 ngx_tmp]# strace -p 42756strace: Process 42756 attachedepoll_wait(10, [{EPOLLIN, {u32=2351931408, u64=140263098916880}}], 512, -1) = 1#两次请求,为啥之前没有,不太清楚accept4(6, {sa_family=AF_INET, sin_port=htons(54229), sin_addr=inet_addr("192.168.200.1")}, [112->16], SOCK_NONBLOCK) = 3epoll_ctl(10, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLRDHUP|EPOLLET, {u32=2351931888, u64=140263098917360}}) = 0epoll_wait(10, [{EPOLLIN, {u32=2351931408, u64=140263098916880}}, {EPOLLIN, {u32=2351931888, u64=140263098917360}}], 512, 60000) = 2accept4(6, {sa_family=AF_INET, sin_port=htons(54230), sin_addr=inet_addr("192.168.200.1")}, [112->16], SOCK_NONBLOCK) = 4epoll_ctl(10, EPOLL_CTL_ADD, 4, {EPOLLIN|EPOLLRDHUP|EPOLLET, {u32=2351932128, u64=140263098917600}}) = 0recvfrom(3, "GET / HTTP/1.1\r\nHost: 192.168.20"..., 1024, 0, NULL, NULL) = 535#打开文件open("/usr/local/nginx//html/index.html", O_RDONLY|O_NONBLOCK) = 7fstat(7, {st_mode=S_IFREG|0644, st_size=936, ...}) = 0writev(3, [{iov_base="HTTP/1.1 200 OK\r\nServer: nginx/1"..., iov_len=238}], 1) = 238#没有读文件操作,直接使用sendfile发送文件,这是第一次请求的效果sendfile(3, 7, [0] => [936], 936) = 936write(8, "192.168.200.1 - - [05/Jan/2024:0"..., 210) = 210setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0epoll_wait(10, [{EPOLLIN, {u32=2351931888, u64=140263098917360}}], 512, 60000) = 1recvfrom(3, "GET /favicon.ico HTTP/1.1\r\nHost:"..., 1024, 0, NULL, NULL) = 479open("/usr/local/nginx//html/favicon.ico", O_RDONLY|O_NONBLOCK) = -1 ENOENT (没有那个文件或目录)write(9, "2024/01/05 05:57:27 [error] 4275"..., 265) = 265writev(3, [{iov_base="HTTP/1.1 404 Not Found\r\nServer: "..., iov_len=155}, {iov_base="<html>\r\n<head><title>404 Not Fou"..., iov_len=100}, {iov_base="<hr><center>nginx/1.20.2</center"..., iov_len=53}, {iov_base="<!-- a padding to disable MSIE a"..., iov_len=402}], 4) = 710write(8, "192.168.200.1 - - [05/Jan/2024:0"..., 243) = 243epoll_wait(10,【对sendfile优化配置后第二次请求】
除第一次请求外,此后的请求没有open操作,只有sendfile和write操作,相当于把open操作的结果缓存住了,缓存的内容和优化配置的参数名高度统一
open_file_cache_系列参数,实际上是将文件的描述符,创建日期、修改时间、文件大小等元数据信息缓存到内存中,能够极大地再次加速sendfile过程xxxxxxxxxxepoll_wait(10, [], 512, 59914) = 0close(4) = 0epoll_wait(10, [], 512, 15075) = 0close(3) = 0epoll_wait(10, [{EPOLLIN, {u32=2351931408, u64=140263098916880}}], 512, -1) = 1accept4(6, {sa_family=AF_INET, sin_port=htons(54420), sin_addr=inet_addr("192.168.200.1")}, [112->16], SOCK_NONBLOCK) = 3epoll_ctl(10, EPOLL_CTL_ADD, 3, {EPOLLIN|EPOLLRDHUP|EPOLLET, {u32=2351931889, u64=140263098917361}}) = 0epoll_wait(10, [{EPOLLIN, {u32=2351931408, u64=140263098916880}}], 512, 60000) = 1accept4(6, {sa_family=AF_INET, sin_port=htons(54421), sin_addr=inet_addr("192.168.200.1")}, [112->16], SOCK_NONBLOCK) = 4epoll_ctl(10, EPOLL_CTL_ADD, 4, {EPOLLIN|EPOLLRDHUP|EPOLLET, {u32=2351932129, u64=140263098917601}}) = 0epoll_wait(10, [{EPOLLIN, {u32=2351931889, u64=140263098917361}}], 512, 59999) = 1#此时第二次请求没有打开文件的操作了,没有open函数,直接sendfilerecvfrom(3, "GET / HTTP/1.1\r\nHost: 192.168.20"..., 1024, 0, NULL, NULL) = 535stat("/usr/local/nginx//html/index.html", {st_mode=S_IFREG|0644, st_size=936, ...}) = 0writev(3, [{iov_base="HTTP/1.1 200 OK\r\nServer: nginx/1"..., iov_len=238}], 1) = 238sendfile(3, 7, [0] => [936], 936) = 936write(8, "192.168.200.1 - - [05/Jan/2024:0"..., 210) = 210setsockopt(3, SOL_TCP, TCP_NODELAY, [1], 4) = 0epoll_wait(10, [{EPOLLIN, {u32=2351931889, u64=140263098917361}}], 512, 59985) = 1recvfrom(3, "GET /favicon.ico HTTP/1.1\r\nHost:"..., 1024, 0, NULL, NULL) = 479open("/usr/local/nginx//html/favicon.ico", O_RDONLY|O_NONBLOCK) = -1 ENOENT (没有那个文件或目录)write(9, "2024/01/05 06:01:00 [error] 4275"..., 265) = 265writev(3, [{iov_base="HTTP/1.1 404 Not Found\r\nServer: "..., iov_len=155}, {iov_base="<html>\r\n<head><title>404 Not Fou"..., iov_len=100}, {iov_base="<hr><center>nginx/1.20.2</center"..., iov_len=53}, {iov_base="<!-- a padding to disable MSIE a"..., iov_len=402}], 4) = 710write(8, "192.168.200.1 - - [05/Jan/2024:0"..., 243) = 243epoll_wait(10,
Nginx Stream代理
Nginx的四层代理,即基于TCP协议上直接做负载均衡和反向代理,以mysql的多主集群做演示实验,使用nginx对后端四层协议的应用做反向代理
官方文档:http://nginx.org/en/docs/stream/ngx_stream_core_module.html
nginx自身有一个Stream模块
ngx_stream_core_module,但是这个包没有默认编译到最初的安装包nginx中【stream反向代理是Nginx1.9以后支持的】,需要在预编译的时候手动指明该模块,但是文件在压缩包内,使用命令./configure --prefix=/usr/local/nginx/ --with-stream进行预编译并使用make编译,将nginx文件拷贝到安装目录替换老的nginx讲的不细啊后面,好水,我都笔记做成这样了还不太能理解
此外nginx还可以给很多后端中间件做负载均衡,如消息中间件,做搜索的组件
系统结构
mysql的集群方式有很多种,最简单的就是一主一从,一主多从;还有多主互相同步数据【MS、MSS、MMM;M是master,S是从服务器,主节点可写可读,从节点只读,一般来说两台服务器上的数据是一样的,如果数据不一样,就是另外一套方案了,比如灰度发布,从节点上是新数据,主节点上是成熟稳定的老数据,做灰度发布让用户随机或者按一定比例选择获取老数据或者是新的数据】,对mysql集群管理和配置的工具有很多,官方的就支持集群,还可以使用脚本工具,比如MHA、MMM;还有开发上的中间件如mycat【一个服务器,帮助用户做透明代理】、shadingsfair【客户端运行的主备插件】
用nginx做mysql的负载均衡更纯粹更简单,对开发者来说更加透明;【透明化是指做负载均衡的客户端不知道集群中有多少台机器】

以前用mycat放在上游服务器后面做透明代理搭建mysql的集群,mycat也能做负载均衡,而且功能相对于mysql来说更完善,还可以使用mycat来做分表;使用nginx代替mycat只是执行效率更高一些;mycat因为功能比较多,显得更笨重一些,做反向代理的功能和nginx差不多,此外还会做主备切换【一般用mycat是玩分库分表,不会拿来单独反向代理】;在这个背景下使用nginx做反向代理才显得干净纯粹,实际上还要考虑主从同步、主备切换、分库分表的事情;如果只是想对mysql集群做反向代理、负载均衡维持高可用不使用跨表跨库更复杂的查询用nginx就可以了;如果是其他的集群没有类似于mycat这样的中间件也可以使用nginx来做负载均衡和高可用,官网有举例子,甚至借助stream能使用UDP协议
在多台mysql服务器已经做好多主同步的基础上,使用nginx来做负载均衡以及高可用【如果一个数据库宕机了还可以再在集群中添加一台数据库】
配置4层反向代理
和原来的HTTP配置很像,但是是和http模块平级的stream模块
nginx.conf
在这种配置下,可以直接使用数据库工具Navicat直接连接反向代理服务器nginx可以直接连上对应的数据库
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}#这就是实际演示mysql远程连接的配置,通过其他的mysql直连nginx就能在一台mysql上访问被代理的mysql,md动力节点讲的啥玩意儿stream {upstream mysql{server 192.168.44.211:3306;server 192.168.44.212:3306;}server {listen 3306;proxypass mysql;}}http {include mime.types;default_type application/octet-stream;sendfile on;server {listen 80;server_name localhost;location / {root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}在mysql从机上使用命令
mysql -uroot -p -h192.168.44.101启动mysql并连接反向代理服务器这个作用似乎是直接用mysql客户端连接并管理反向代理服务器对应连接被代理的客户端,显示的数据库信息似乎也是远程连接数据库的信息,使用命令
show databases;能看到被代理mysql服务器的数据库信息,此时如果重启代理服务器nginx,再次使用命令show databases;,此时会显示连接已经丢失实在想不到本地的mysql能用mysql客户端远程连接其他的mysql数据库,而且不知道为什么会自动选择stream这个站点
在这种连接方式的基础上数据一样可以做负载均衡,数据不一样可以做灰度发布
Nginx的QPS限流
项目上线以前应该使用测试工具测出系统的QPS上限,避免项目的QPS不满足生产条件,一上线就被压垮;同时需要对生产中的QPS进行限制,以确保项目的安全稳定,限制阈值使用压测工具测得
现在常用的压测工具是Jmeter,Jmeter是Apache开发的,也有很多年的历史了;好用并且测试结果可以从各个维度进行展示;这是一个java开发的工具,挺大的,压缩包都七十多兆,运行需要jdk环境,解压后执行jmeter.bat运行程序;官方网站:https://jmeter.apache.org
Nginx官方对QPS限制的功能在模块
ngx_http_req_module中,使用的算法是漏桶算法【也叫漏斗算法】,该模块的官方文档:http://nginx.org/en/docs/http/ngx_http_limit_req_module.html,该模块可以配置在http模块下的server中的各个locationNginx限速的三种方式,限制服务器端QPS通过漏桶算法、带宽限制用令牌桶算法、单个客户端的并发线程数限制用计数器算法,不冲突可以混合使用
对Nginx进行限流配置
nginx.conf
这是基于漏桶算法的最基本配置,经过确认,这里的配置就是针对单个用户做一秒一个请求的限速,并不是对服务器来做整体上的限速
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;#在http模块下对限速进行总体配置,在location模块下对每个站点目录进行独立的限流设置#limit_req_zone表示调取限流相关的模块,#$binary_remote_addr是nginx的内部变量,指远程客户端的IP地址;这是限流的对象,还可以设置为server_name针对一个server做限流,不再对单一的用户做限流,官方文档有讲,课上这部分讲的太烂;同时还可以IP和server一起限制,一起限制时根据最小匹配原则,先匹配上哪个另一个限流条件就失效#zone=one:10m,zone=one是给该限速指令取了一个名字叫one,这是可以自定义的,目的是给后续location通过名字进行使用;:10m是指为远程客户端IP地址分配10m的内存缓冲空间去记录用户的Ip地址#rate=1r/s表示限制每秒只接收一个请求,r表示request。1r表示一个请求[听讲的意思似乎可以对IP进行QPS限制一秒一个],这里的$binary_remote_addr可以换成其他的参数比如$user_agent、$remote_addr;$binary_remote_addr是使用最原始的IP地址二进制数据,$remote_addr是使用十进制字符串形式的数据,使用$binary_remote_addr单条数据的数据量更小,能记录的数据量越多limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;server {listen 80;server_name localhost;location / {#在location下使用在http模块下设置的限流规则onelimit_req zone=one;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}浏览器测试效果
因为对限流设置的很小,一秒一个,所以直接子啊浏览器中就能看到超过一秒一个请求后的报错效果
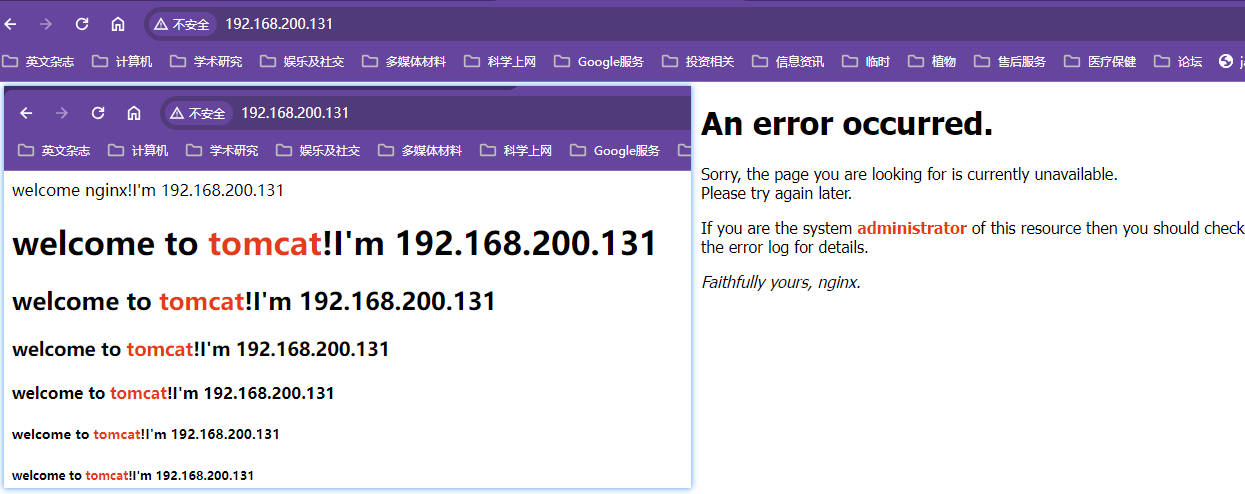
【报错信息】
限流的报错信息是503服务展示不可用错误,可以针对该错误进行单独的服务降级
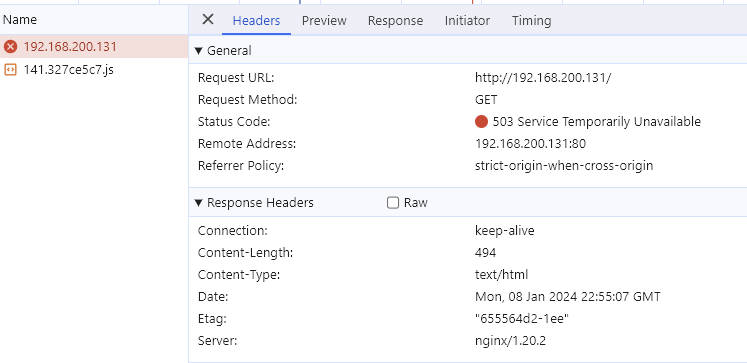
使用jmeter对nginx限流效果进行测试
jmeter设置
【线程组设置】
Thread Group表示发送请求的最小单位是以线程作为单位的
Name是线程组的名称,Comments是该线程组的摘要说明,这两个都可以不填
Number of Threads是并发请求的用户数,意思是给并发请求启动多少个线程来模拟用户数量
Ramp-up period指的是这些线程在多长时间内将这些线程启动起来,可以看做多长时间内把请求发送出去
Loop Count该线程组发送请求循环的次数,infinite表示无限次发送请求
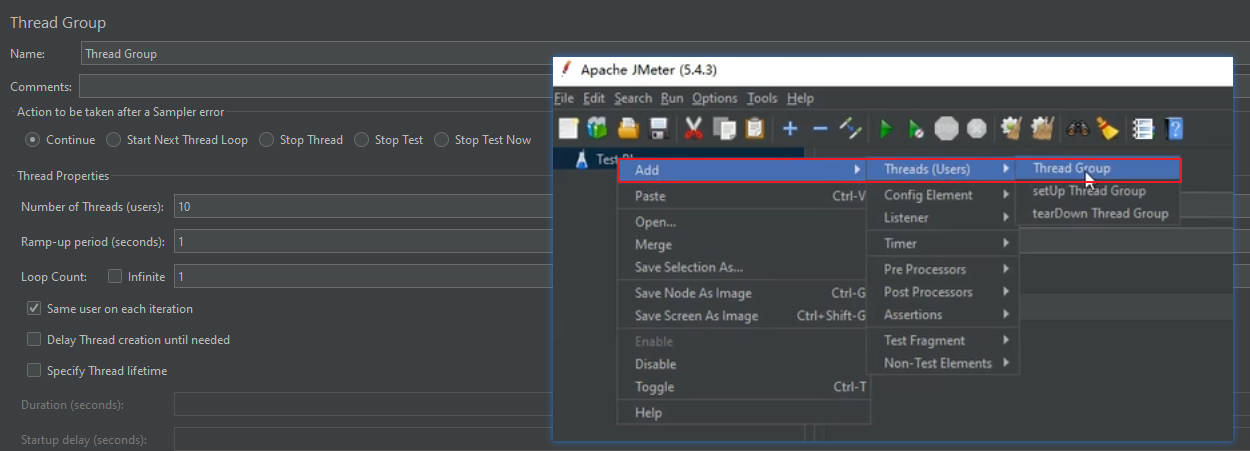
【请求设置】
点击绿色按钮是启动该线程组,弹框是提示是否保存当前设置的请求计划,点击保存会将请求设置保存在本地的jmeter的bin目录下的Summary Report.jmx文件中【就是持久化操作】
使用jmeter查看测试效果
【jmeter的查看测试结果集菜单】
listener下有很多展示测试数据的测试结果集选项,比较常用的有以下三种,要像图中这样选中对应的选项卡,在选项卡菜单中运行线程组
View Result Tree
Summary Report
View Result in Table
【View Result Tree测试效果】
直接选中对应的结果集选项,并按此前操作点击绿色按钮
在此前的限流设置下,一秒内的十次并发请求,只有第一个成功了
该结果集选项卡下能看到每个请求的请求协议信息、请求的URL和响应数据
【Summary Report测试效果】
Label字段指是发送的是哪一类请求,Http Request表示发送的是http请求,Total表示所有请求的统计信息
Sample表示发送请求的样本个数,我发了3次十个请求,这里就显示的30个
Average、Min、Max、Std.DEV都是响应时间,意思是响应时间的平均值,最小值、最大值和中位值
Error是请求发送发生错误的请求比例有多少
Throughput是指吞吐量,就是指QPS,卧槽我这里怎么是9.6个每分钟,老师的演示是11个每秒,说样本太少,展示数据的结果不准确
Received KB/sec是指每秒接收数据的吞吐量,即网络消耗的吞吐
Send KB/sec是指每秒发送数据的吞吐量
Avg.Bytes是平均每秒数据吞吐量的大小
需要关注的主要就是QPS和发送接收数据的吞吐量,如果QPS怎么也上不去,就像下图演示的情况,此时一定要关注传输数据的吞吐量,因为数据传输的速率是由网卡决定的,比如百兆网卡下载速度应该是100除以8,即12M左右,到达数据传输上限或者延迟很高QPS也是上不去的,不知道是不是我这里的网络太差的原因,但是我这儿用的是同一台主机,难道也是用网卡进行通信的吗
注意上面的工具栏两个小扫把【悬停显示clear】可以清除页面的数据【一个是清除当前,一个是清除所有】,每次发送请求都最好点一下清除数据,方便统计
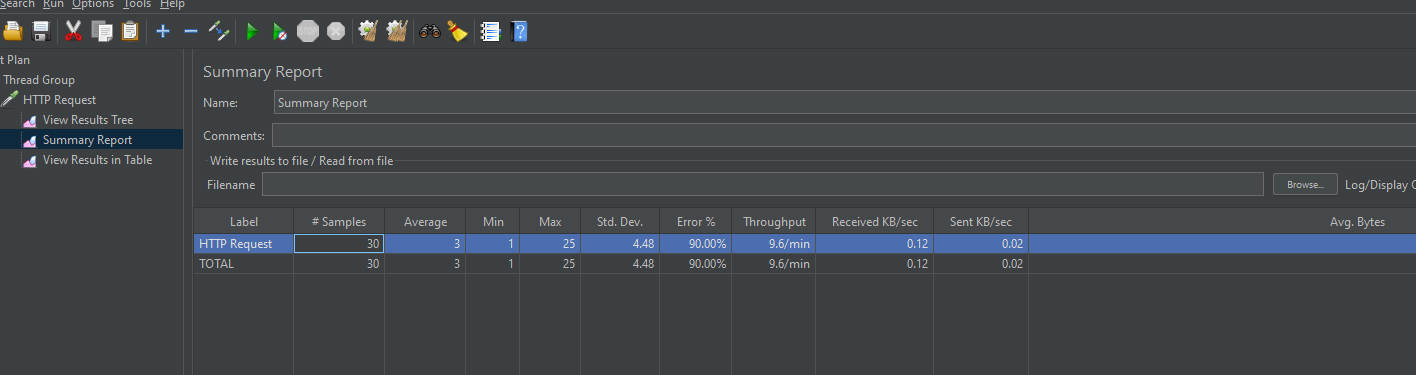
【View Result in Table测试效果】
能够看到每个请求的开始时间【毫秒级别】,请求线程、响应时间、响应状态、请求和响应数据量
对Nginx服务器无限次请求,观察jmeter统计效果
我这里发了十二万个请求,在nginx服务器的设定限流规则下,只有几个成功了【因为试验了几秒钟】,此时我的QPS上来了,能达到42.4每秒,卧槽老师的都快10000每秒了
连续发起请求,整个过程40多万个请求,可以动态的显示QPS效果。我这里QPS稳定达到了14000左右每秒【最高一万七,一万七不是真实数据,我第二次请求一直单增,但是最终还是稳定1万四】,老师的还是10000左右
虚拟机的配置相比于实际生产机极低,也能到一万多的QPS,QPS高的原因是nginx性能高此外还有请求几乎都报错,即有很多无效的QPS
顶上error和success分别勾选能单独统计成功请求和失败请求的QPS,在ngixn设置的限流策略下随时间推移勾选成功会将QPS稳定在设置值1r/s
而且在View Result in Table中能看到成功请求的时间间隔严格的遵循1s,完全精确到jmeter的时间刻度1ms
漏桶算法配置
上述的设置中并没有漏桶的概念,漏桶的意思是将请求全部存储起来,根据系统的QPS限制一点点地通过;但是上述配置是超过系统QPS设置的请求直接失败并响应503;当系统可用时再次接收下一个请求后当前一秒的时间窗口内的请求依然全部失败被拒绝丢弃;而漏桶算法要求一秒的时间窗口内,后续超过QPS限制的请求被存储起来,下一个一秒的时间窗口内再响应上一个一秒时间窗口内没有被处理的请求【即把所有请求放在一个桶里面存起来,按照服务器的设置QPS对桶里的请求进行依次处理,请求数量超出桶的容量再进行丢弃】
在nginx中对桶进行配置
❗️这里的brust属性没有形象的说明到底是什么意思,个人经过测试理解,当一秒内五个用户发起无限次请求,一个请求都不会直接被拒绝,状态类似于一秒钟处理一个,其他的请求貌似进入排队状态,但是这里很奇怪,如果是根据IP区分用户,那么jmeter发起的模拟用户的并发请求IP是否各不相同,从nginx对ip进行限流且每秒响应一个的结果上来说并没有一秒钟处理五个请求,所以这里的模拟5个用户,用户的区分很可能不是IP;但是Nginx的brust设置是5,一个请求也没有拒绝,那么这个brust是怎么不依靠ip区分这五个用户的呢?;此外一旦jmeter设置成6个用户一秒内发起无限次请求,立马出现n多个请求被拒绝的情况,说明brust的设置是针对用户数量的设置,好像就设置了5个用户,允许优先占用brust的5个用户的所有请求进行排队而不会直接失败,一旦多出来一个用户多余出来的用户请求会直接全部失败,而且失败都是同一个用户即一个线程同时失败一片请求,但是隔一段时间失败的线程会进行轮换【不太明白这里是什么意思,要理解这里需要理解jmeter是如何区分用户请求和nginx是如何区分用户请求的,这里课堂上没有讲解brust到底指的是什么以及为什么一秒处理一个请求,以后自己研究一下】,暂时理解成brust=5设置为5个桶,一个用户一个桶,单个用户所有的请求都存入一个桶中不会直接失败,用户的请求按照设置的一秒一个进行处理,同时注意这些桶不是用户独占【还是有问题,如果是按IP区分用户这里应该一秒处理五个请求,总之这里要理解透彻需要自己研究】
讲的很不好,没有解释清楚brust=5究竟是什么意思,到底是五个用户还是五个请求容量;而且按课程讲的五个容量后续请求全部排队也不对,因为我这里五个用户一个失败的请求都没有,但是一旦设定6个用户且没有设置nodelay就立马出现大量单个线程请求轮换批量失败
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;server {listen 80;server_name localhost;location / {#brust=5就像是设置5个桶容纳5个用户的全部请求,按照设定的针对IP的限流规则在整体上对所有桶内的请求限流,多余的用户发送的请求会被全部抛弃limit_req zone=one burst=5;#下面是比较完整的设置,nodelay表示如果用户的请求积压,超过一定容量范围的请求会直接失效;感觉老师这里没有理解到位啊,完全无法解释测试效果;卧槽这里加了nodelay以后QPS变成了四点几接近五了,没加QPS只是1,且前五个请求瞬间就能完成#limit_req zone=one brust=5 nodelay;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}
令牌桶算法配置
这种配置在桶中放的是令牌,以固定速率比如5个每秒向一个桶中放入令牌,令牌可以根据客户请求需要分配不同的令牌数量给同一个用户,用来控制请求处理过程中的相关配置,比如一个令牌代表100M的网络带宽,vip用户分配3个令牌在后续的处理过程中可以使用300M的网络带宽对数据进行下载;一般用户分配一个令牌,实现对不同用户的限速;如果桶中没有令牌了可以设置后续请求等待或者直接快速失败
使用令牌桶限制网络带宽配置
Nginx内部实现网络带宽限制使用的就是令牌桶算法,每个请求进入nginx后会拿走一个牌子,每个牌子代表请求能够享受的带宽资源
主要是以下两个配置,还有很多第三方模块可以更精准地限制网络带宽
nginx.conf中的
limit_ratexxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;server {listen 80;server_name localhost;location / {limit_req zone=one burst=5 nodelay;#设置响应请求资源文件的速度,以字节byte为单位,设置文件下载速度为1kblimit_rate 1k;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}访问
http://192.168.200.131/Git-2.22.0-64-bit.zip下载文件效果下载前就能获取到文件的大小,下载速度在880-1220之间波动,平均值大约在1kb,这个速度是浏览器估计的,不同的浏览器显示的速度也不同;有些浏览器显示快可能是浏览器不要脸也可能是浏览器有多线程下载的功能
有些客户端【比如迅雷】可以发起多线程下载,每个请求接入服务器都可以拿到一个令牌,达到高速下载的目的
nginx.conf中的
limit_rate_after这种到达一定阈值后的限速比较适合一些视频网站,用户很多时候可能只是预览前一部分,不想看了就关掉了,这样先把一部分内容加载过去让用户先看,然后限速传输节省网络带宽,大量用户如果不想看就会直接关掉连接,这样能节省服务器的网络带宽资源,正常情况下是先加载一部分然后限速要能满足用户流畅地观看,主要目的是为了避免带宽的浪费
还可以看的正爽后面内容限速卡顿需要开会员
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;server {listen 80;server_name localhost;location / {limit_req zone=one burst=5 nodelay;#该配置表示下载多少大小的资源以后再开始执行限速,下面配置表示建立连接传递1m数据后再开始限速limit_rate_after 1m;#设置响应请求资源文件的速度,以字节byte为单位,设置文件下载速度为1kblimit_rate 1k;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}下载一定容量后再限制下载速度的效果
瞬间进度条就到达了一定的容量然后限速
计数器算法
限制并发数,限制一个客户端的并发请求数,比如开了多线程下载;有的服务器开了多线程下载也没用,请求连接不上,并发数限制就是累加当前客户端的并发线程个数【计数器算法就是自加一】
客户端并发量配置
限制了客户端并发数,只有等客户第一个请求处理响应完成后才会处理第二个请求
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;#limit_conn_zone表示对并发数限制的命令,对客户端Ip进行并发数限制,zone也是配置规则的名字,和此前的配置不能重名;需要分配内存空间,这里是10m来记录用户的Ip和对应并发数limit_conn_zone $binary_remote_addr zone=two:10m;server {listen 80;server_name localhost;location / {#limit_req zone=one burst=5 nodelay;#limit_rate_after 1m;#这里速度太快会让请求瞬间响应,无法观察到前一个请求还没有处理完并发请求就过来的效果,所以此处将改成20字节,就能观察到同一时刻并发数太多导致的请求直接失败limit_rate 20;#limit_conn使用two这个命名空间来对该空间中的Ip对象限制并发数为1,这样设置了压根使用不了多线程下载limit_conn two 1;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}使用jmeter对并发请求设置进行测试
jmeter使用的是httpClient发送的请求,十个用户无限并发请求,因为限制了响应速度,后续的请求全部失败,很长时间以后第一个请求才响应回来

日志
日志可以收集用户的低价值数据【用户的行为,出行、购物等】接入大数据系统或者AI系统可以获取到很高的商业价值,高价值数据一般指用户的手机号、家庭住址、银行卡余额等数据,可以在商品推荐中调整商品推荐的策略
电商系统日志可以记录包括用户访问了哪些商品,停留了多长时间,购买了哪些商品构建用户行为画像,做推荐系统;抖音b站都有这种;像京东鼠标滑动停留的操作都可以通过js来向日志系统发起请求,一般网站中size很小的请求都是搜集用户信息的;日志系统比较复杂,和AI、大数据和BI平台有关系,比如最近老是看内存就会推荐内存;反正就是通过用户行为来调整用户的推荐策略
网站也可以通过日志获取网站每天访问独立的IP有多少个【UV】、每个页面的浏览量是多少【PV】,还有数据标准,看哪些图片是红绿灯来让用户训练大数据或者AI模型来提供给自动驾驶系统使用
nginx上对日志支持的模块式是
ngx_http_log_module,记录日志的请求一般就用http协议,没必要使用https协议,http协议更加高效,https协议额外增加四次握手
Access.log
日志配置参数
以下两个配置是
logs/access.log的配置,访问日志,只要有效的访问都会进行记录,不像java能够分等级写入,一些不重要的接口的日志功能可以直接关闭,能够提升nginx的性能,但是尽可能的不要关,可以用来检查是否有IP存在攻击行为,配合防火墙把Ip给禁用掉;不包含错误请求【如404、500】,错误请求的日志都会记录在error.logaccess_log参数值:
access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]];默认值:
access_log logs/access.log combined;作用域:
http,server,location,if in location,limit_except
日志的总体配置
path是日志的路径
buffer是配置缓冲区,记录日志时先将日志写到内存缓冲区;
日志是文档,可以配置日志的gzip压缩级别【gzip模块自带就有,静态压缩才需要编译安装静态压缩模块,这里应该不需要开启动态压缩功能吧】,日志会直接追加到gz格式的日志压缩文件中,直接看是看不了的,需要解压才能看
flush是写入日志的时间间隔,触发将日志写入磁盘可能有以下几个事件,第一个是buffer缓冲区满了,最后一条日志缓冲区写不下了就会将缓冲区数据向磁盘写入;第二个是flush time时间到了也会向磁盘写入,这种设置是应对网站没有什么人访问时即缓冲区满不了也要强制的去写一下日志,时间不要设置的太短,几分钟或者一个小时都行,设置方法
flush=1s;worker进程正常关闭的时候也会触发写日志的操作;nginx的默认配置没有对flush配置,来一个请求就把日志写入磁盘[if=condition]是一些判断条件,比如根据userAgent,如果来自安卓的就记日志,苹果手机的就不记录;条件匹配上就不记录对应的日志配置
access_log off;是关闭站点的访问日志功能log_format参数值:
log_format name [escape=default|json|none] string ...;默认值:
log_format combined "...";作用域:
http
配置日志的格式 可以配置要记录的变量,如下实例所示
$remote_addr是远程IP地址、$time_local是本地时间、$status是请求的状态,还有以前使用过的各种变量,貌似官网列举的变量不是全部,老师说正常的Nginx变量都可以用日志的格式除了支持文本的方式还支持json的格式的字符串,但是nginx并不知道变量的层级关系,只会去做特殊字符的转义
【配置实例】
xxxxxxxxxxlog_format combined '$remote_addr - $remote_user [$time_local] ''"$request" $status $body_bytes_sent ''"$http_referer" "$http_user_agent"';【json格式日志的配置实例】
需要手动使用变量构建json对象,nginx可以在日志中转义对应的特殊符号为字符串
xxxxxxxxxxlog_format ngxlog json '{"timestamp":"$time_iso8601",''"source":"$server_addr",''"hostname":"$hostname",''"remote_user":"$remote_user",''"ip":"$http_x_forwarded_for",''"client":"$remote_addr",''"request_method":"$request_method",''"scheme":"$scheme",''"domain":"$server_name",''"referer":"$http_referer",''"request":"$request_uri",''"requesturl":"$request",''"args":"$args",''"size":$body_bytes_sent,''"status": $status,''"responsetime":$request_time,''"upstreamtime":"$upstream_response_time",''"upstreamaddr":"$upstream_addr",''"http_user_agent":"$http_user_agent",''"http_cookie":"$http_cookie",''"https":"$https"''}';open_log_file_cache参数值:
open_log_file_cache max=N [inactive=time] [min_uses=N] [valid=time];默认值:
open_log_file_cache off;作用域:
http,server,location
配置内存缓存日志文件的文件描述符,可以降低高并发情况下的IO开销,如果缓冲区和刷新时间设置的还Ok的话,其实不会频繁的进行日志文件的IO操作,此时影响不大,配置了会起到优化的作用,但是只有高频的磁盘IO情况下优化效果才会明显【对文件IO的操作需要以后学习一下】
max=N表示最大打开多少个文件描述符,一共有几个日志文件就设置多少,可以冗余设置,比如5,access.log是其中一个日志文件
[inactive=time]是间隔多长时间没有使用就过期,[min_uses=N]日志的写入次数达到多少再做缓存,[valid=time]是缓存的有效时间
内存缓冲区
模块
ngx_http_empty_gif_module是返回一个像素1x1的透明像素块,该像素块是用来访问nginx服务器的,比如京东的log.gif,主要目的就是把请求达到nginx服务器上搜集用户的行为信息,该模块内置在nginx中,通过简单配置就能使用
配置模块
ngx_http_empty_gif_modulenginx.conf
单独配置一个location
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;limit_conn_zone $binary_remote_addr zone=two:10m;server {listen 80;server_name localhost;location = /_.gif {empty_gif;}location / {limit_conn two 1;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}通过URL
192.168.44.101/_.gif对该透明像素块进行访问这种像素块一般都是通过img标签内嵌在网页中,随便放在哪儿

access.log
默认的日志格式:客户端IP - - 时间 "请求方式 URI 协议" 响应状态码 0 "-" "UserAgent客户端信息"
/favicon.ico的请求是浏览器自动发起的
使用命令
tail -f /usr/local/nginx/logs/access.log能在linux客户端实时地显示文件内容更新情况,使用Xftp并不会实时更新文件内容可以看出现在默认的nginx配置是每接收一个请求就会去写一次日志,但是不同的nginx版本默认配置可能不一样,要根据nginx配置进行判断,如果配置了缓冲区就会等缓冲区写满以后或者刷新时间到了或者nginx服务器重启才会批量向磁盘写入
xxxxxxxxxx192.168.200.1 - - [11/Jan/2024:11:45:41 +0800] "GET /_.gif HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36"
配置nginx的缓冲区
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;limit_conn_zone $binary_remote_addr zone=two:10m;#日志格式,这个的第二个参数compression是日志别名,需要和日志设置的别名要匹配log_format compression '$remote_addr - $remote_user [$time_local] ''"$request" $status $body_bytes_sent ''"$http_referer" "$http_user_agent"';#compression是别名,这个主要用于和日志形式的配置相互匹配,名字可以自定义,这个名字是在日志格式确定的,在日志配置中使用;通过buffer设置日志缓冲区,32k是日志缓冲区的大小,目录必须存在,否则会报错;日志格式的配置必须在日志配置的前面,否则会报错access_log logs/access.log compression buffer=32k;#为了表现刷新效果,将刷新时间更改为1s#access_log logs/access.log compression buffer=32k flush=1s;server {listen 80;server_name localhost;location = /_.gif {empty_gif;}location / {limit_conn two 1;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}设置以后无论怎么刷新,tail命令都观察不到日志文件的变化,就是还没有达到buffer缓冲区的上限,重启nginx会写入磁盘
除非断电可能会导致日志的丢失,但是这种低价值数据丢一点点没有关系
经过测试,配置强制定时刷新后每个配置的时间间隔后都会刷新日志文件的内容
【更新后的日志格式】
xxxxxxxxxx192.168.200.1 - - [11/Jan/2024:14:16:26 +0800] "GET /_.gif HTTP/1.1" 304 158 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36" "-"
日志文件压缩
正常服务器一天的日志可能就以G为单位了【我靠这么大不浪费存储空间吗,我一个人用一段时间日志和错误文件都快1G】,配置gzip来实现日志压缩的效果,日志压缩在缓冲区中就已经压缩了,然后在日志文件中直接追加日志的内容
配置日志文件使用gzip压缩
开启gzip压缩日志最好单独搞一个文件,否则会出现配置前是明文,配置后的日志信息是压缩文件信息;总之就是向log为后缀的文件写入明文或者写入压缩后的日志内容;解压缩比如日志文件
ngx_logs/access.log需要拷贝一份日志文件并更改后缀gz,然后直接在linux使用命令gzip -d access.gz就能自动解压缩access.gz文件到没有后缀的access文件,在压缩等级设置为9的情况下解压和不解压的文件大小相差7倍左右,压缩等级为6的时候是2倍多一点点nginx.conf
但是处理日志的时候不需要太在意性能,因为日志服务器一般只处理日志,一般不会处理别的请求,这个根据实际场景去调整日志压缩等级
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;limit_conn_zone $binary_remote_addr zone=two:10m;log_format compression '$remote_addr - $remote_user [$time_local] ''"$request" $status $bytes_sent ''"$http_referer" "$http_user_agent" "$gzip_ratio"';#只写gzip不写=6默认压缩等级是1,设置的太高压缩的时候比较消耗性能access_log ngx_logs/access.log compression buffer=32k gzip=6 flush=1s;server {listen 80;server_name localhost;location = /_.gif {empty_gif;}location / {limit_conn two 1;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}
日志格式
配置json格式的日志内容,用MongoDB、EalsticSearch或者文本文档类型数据库做数据分析时可以直接将json日志直接导入,文本格式的日志更适合大数据框架,比如Hadoop、Htfx,可以设置边界符或分隔符,用数仓工具做数据分析
配置json格式的日志内容
nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;limit_conn_zone $binary_remote_addr zone=two:10m;log_format compression '$remote_addr - $remote_user [$time_local] ''"$request" $status $bytes_sent ''"$http_referer" "$http_user_agent" "$gzip_ratio"';log_format ngxlog json '{"timestamp":"$time_iso8601",''"source":"$server_addr",''"hostname":"$hostname",''"remote_user":"$remote_user",''"ip":"$http_x_forwarded_for",''"client":"$remote_addr",''"request_method":"$request_method",''"scheme":"$scheme",''"domain":"$server_name",''"referer":"$http_referer",''"request":"$request_uri",''"requesturl":"$request",''"args":"$args",''"size":$body_bytes_sent,''"status": $status,''"responsetime":$request_time,''"upstreamtime":"$upstream_response_time",''"upstreamaddr":"$upstream_addr",''"http_user_agent":"$http_user_agent",''"http_cookie":"$http_cookie",''"https":"$https"''}';#json格式日志也可以使用gzip,只是这里为了方便观察效果故意不设置access_log ngx_logs/access.log ngxlog buffer=32k flush=1s;server {listen 80;server_name localhost;location = /_.gif {empty_gif;}location / {limit_conn two 1;root html;index index.html;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}日志效果
xxxxxxxxxx[root@nginx1 ngx_logs]# tail -f /usr/local/nginx/ngx_logs/access.logjson{"timestamp":"2024-01-11T16:38:32+08:00","source":"192.168.200.131","hostname":"nginx1","remote_user":"-","ip":"-","client":"192.168.200.1","request_method":"GET","scheme":"http","domain":"localhost","referer":"-","request":"/_.gif","requesturl":"GET /_.gif HTTP/1.1","args":"-","size":0,"status": 304,"responsetime":0.000,"upstreamtime":"-","upstreamaddr":"-","http_user_agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36","http_cookie":"-","https":""}【信息细节】
xxxxxxxxxx{"timestamp":"2024-01-11T16:38:32+08:00","source":"192.168.200.131","hostname":"nginx1","remote_user":"-","ip":"-","client":"192.168.200.1","request_method":"GET","scheme":"http","domain":"localhost","referer":"-","request":"/_.gif","requesturl":"GET /_.gif HTTP/1.1","args":"-","size":0,"status":304,"responsetime":0,"upstreamtime":"-","upstreamaddr":"-","http_user_agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36","http_cookie":"-","https":""}
Error.log
错误日志官方文档:http://nginx.org/en/docs/ngx_core_module.html#error_log,在core模块下,因为比较简单,没有单独组织成一个模块
access.log可以自定义很多格式,error.log不能自定义格式;
error.log有两个参数
参数解析
error_log参数值:
error_log file [level];默认值:
error_log logs/error.log error;作用域:
main,http,mail,stream,server,location
level是日志的错误等级,根据源码中记录的错误等级来记录日志,一共有8个等级,
debug,info,notice,warn,error,crit,alert, oremerg。等级从前到后依次是越来越严重;默认是error级别错误日志可以做分析,但是不能自定义格式,只能按照系统的配置来搜集数据做分析,导入到大数据系统后还需要对这些日志格式进行处理
日志分割
可以通过直接抓取日志,比如以流的方式通过一些工具如DataX、FileBs等将Nginx日志直接拉到ELK或者Kafka中进行消费,消费完成后再清空日志;如果不是通过上述方式处理日志就需要进行日志分割,分割日志有两种方式,
使用脚本将日志按照日期进行切割【每隔一天生成一个新的日志文件】,当挪动日志文件后需要通知nginx重新加载配置即reload一下;
使用CentOs内置的一个日志管理工具Logrotate,迷你版中都有这个工具,里面已经把处理日志脚本需要做的事都完成了,只需要配置一下日志分割的方式和规则即可,需要配置去通知nginx的worker进程的操作
上游服务器健康检查
重试机制
这是一种被动式的服务重试和状态检查,需要通过配置来标记服务不可用,且没有可视化界面
如果上游服务器是一个在upstream中配置的两台以上机器的集群,如果某台机器不可用,nginx会将请求自动转向下一台机器,再将结果响应回来,不会请求一次上游服务器,发现服务器不可用就直接报错
官方文档:http://nginx.org/en/docs/http/ngx_http_proxy_module.html#proxy_next_upstream
参数解析
proxy_next_upstream参数值:
proxy_next_upstream error | timeout | invalid_header | http_500 | http_502 | http_503 | http_504 | http_403 | http_404 | http_429 | non_idempotent | off ...;默认值:
proxy_next_upstream error timeout;作用域:
http,server,location
作用是配置请求上游服务器发生了哪些错误后再尝试去请求upstream中的下一个上游服务器,error是上游服务器报错、timeout是连接失败、invalid_header是无效的响应头、后续是一系列状态码;设置为off就不会自动去重试下一个服务了;
默认配置是error和timeout,一般是不需要改的
【配置实例】
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream proxyServers{server 192.168.200.134:8080;server 192.168.200.135:8080;}server {listen 80;server_name localhost;location / {#设置重试的情况proxy_next_upstream error timeout;#设置重试的时间proxy_next_upstream_timeout 15s;#在重试时间内可以尝试的次数,也是集群中的机器数,可以尝试5个机器proxy_next_upstream_tries 5;proxy_pass http://proxyServers;}location ~*/(css|js|css) {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}proxy_next_upstream_timeout参数值:
proxy_next_upstream_timeout time;默认值:
proxy_next_upstream_timeout 0;作用域:
http,server,location
作用是配置做失败重试的时候的超时时间【单指整个重试动作】,值为0表示不对超时时间进行限制;可以设置为具体的时间比如15s,超过15s就会告诉用户该次请求彻底失败了
proxy_next_upstream_tries参数值:
proxy_next_upstream_tries number;默认值:
proxy_next_upstream_tries 0;作用域:
http,server,location
作用是配置做失败重试的超时时间内可以做多少次重试,设置为0表示不限制重试的次数
这个次数是包含第一次请求失败的次数的
重试的时间不要设置的太小,重试的次数不要设置的太多,很容易造成还没有来得及尝试就超时返回给客户端,导致并没有进行重试操作
配置一台机器运行失败导致服务下线的次数
如果多次请求一台机器老是失败但是不排除掉每次都去尝试请求效率很低,通过upstream中的server配置可以配置允许一台机器可以失败多少次
max_fails=count设置一台允许失败的次数
这时候也可能是网络丢包等原因导致的服务器下线,服务器如果缓过来需要使用下述第二个配置来让服务上线
xxxxxxxxxxupstream proxyServers{#设置允许机器134失败5次,超过5次会直接将该机器标记为不可用,下次再有请求进来就不会向该机器发起请求了server 192.168.200.134:8080 max_fails=5;server 192.168.200.135:8080;}fail_timeout=time比如设置time为10s,标记服务下线以后十秒,可以尝试让服务上线一次观察一下响应结果是否正常
同时还有另一层含义,10s内如果失败5次就让服务下线
xxxxxxxxxxupstream proxyServers{#设置允许机器134失败5次,超过5次会直接将该机器标记为不可用,下次再有请求进来就不会向该机器发起请求了server 192.168.200.134:8080 max_fails=5 fail_timeout=10s;server 192.168.200.135:8080;}
主动健康检查
Nginx借助第三方插件完成主动检查机制,有很多项目就是为了使用该主动健康检查模块才使用的tengine【开源版Nginx自身没有主动健康检查的功能】
重试机制是被动式的健康检查和服务下线【响应接收不到多次判定下线】,主动健康检查是Nginx主动向上游服务器发起一些指令检查上游服务器是否在线,如果不在线就把对应服务进行剔除,Nginx的tengine版本【https://github.com/yaoweibin/nginx_upstream_check_module】和商业版本【http://nginx.org/en/docs/http/ngx_http_upstream_hc_module.html】的部分插件都能用在原版Nginx上做主动健康检查,企业中使用tengine主要的原因就是能进行主动健康检查,还可以通过可视化界面直观看到哪些上游服务器宕机了,没有图形化界面只能通过日志去分析服务的状态【这个过程是比较麻烦的,即只有重试机制需要分析日志才能获取上游服务器的状态】
tengine提供主动健康检查的模块是
nginx_upstream_check_module,这个模块可以直接安装在Nginx开源版上,但是需要改开源版的源码,tengine大量修改了Nginx的源代码,很多模块不能拿过来就直接用,改源码一般通过脚本改;【该主动检查模块已经很完善了,并且已经用在了淘宝网上】Nginx商业版提供主动健康检查的模块是
ngx_http_upstream_hc_module,nginx很无耻的将商业版的模块文档放在了开源Nginx的官方文档中,比如主动健康检查、upstream动态配置、Endpoint主动反馈服务器的其他状态信息【官方文档会有改模块在商业版中可用】,官方开发出来的商业版本一般更加安全稳定
开源版Nginx安装模块
nginx_upstream_check_module安装比较繁琐,要去修改Nginx的源码,需要下载code中对应自己Nginx的patch脚本,该脚本用于修改Nginx的源码,使用的Nginx版本一定要和patch的版本相对应【patch只有特定Nginx版本的】,这一点一定要注意,版本号对不上很有可能导致安装以后使用不了
教学演示Nginx1.20.2【我的Nginx就是这个版本】对应patch
[check_1.20.1+.patch]这种方式不仅能主动检查http协议的,stream的也能检查
将模块
nginx_upstream_check_module压缩包nginx_upstream_check_module-0.3.0.tar.gz上传到/opt/nginx下并解压缩在linux服务器上将脚本文件复制拷贝到
/opt/nginx/path中【复制的时候要使用插入模式避免丢东西】点开patch文件,点击右上角的raw进行复制粘贴到path文件中
使用命令
yum install -y patch安装patch在nginx1.20.2的解压包内使用命令
patch -p1 < /opt/nginx/path不在解压包执行会报错文件找不到,执行显示修改了以下几个文件
xxxxxxxxxx[root@nginx1 nginx-1.20.2]# patch -p1 < /opt/nginx/pathpatching file src/http/modules/ngx_http_upstream_hash_module.cpatching file src/http/modules/ngx_http_upstream_ip_hash_module.cpatching file src/http/modules/ngx_http_upstream_least_conn_module.cpatching file src/http/ngx_http_upstream_round_robin.cpatching file src/http/ngx_http_upstream_round_robin.h在nginx解压目录使用命令
./configure --prefix=/usr/local/nginx20 --add-module=/opt/nginx/nginx_upstream_check_module-0.3.0进行预编译配置,使用命令make进行编译,使用命令make install安装nginx修改新安装的nginx的配置文件
/usr/local/nginx20/conf/nginx.conf这种主动检查机制的好处是没有必要用户每次请求都去重试已经挂掉的机器,被动重试也有这个效果,只是需要单独配置;很明显SpringCloud GateWay明显要更标准化一些,可定制化程度也更高
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;sendfile on;keepalive_timeout 65;upstream backend {server 192.168.200.131:8080;server 192.168.200.135:8080;#以下是添加主动健康检查模块nginx_upstream_check_module配置的第一部分,interval=3000指每隔3000ms检查一次上游服务器状态,rise指的是请求多少次都成功了上游服务器才算是正常的;fall=5表示如果请求五次都是down的状态就将服务标记为down的状态,timeout=1000是检查请求的超时时间,type=http表示走http协议check interval=3000 rise=2 fall=5 timeout=1000 type=http;#设置nginx向上游服务器发起http请求的头协议和uricheck_http_send "HEAD / HTTP/1.0\r\n\r\n";#表示nginx认为上游服务器还活着的状态码是200系列和300系列状态码check_http_expect_alive http_2xx http_3xx;}server {#避免和原nginx发生端口冲突listen 808;server_name localhost;#以下是添加主动健康检查模块nginx_upstream_check_module配置的第二部分location /status {#这个是调用check_status模块来展示服务状态的页面check_status;#把该站点的请求日志给关掉access_log off;}location / {proxy_pass http://backend;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}因为这里更改了端口,直接使用
./nginx启动会走系统的默认配置【不懂这句话什么意思】,需要使用命令./nginx -c /usr/local/nginx20/conf/nginx.conf指定配置文件来启动使用URL
192.168.200.131:808/status访问上游服务器状态的图形化界面启动135的tomcat观察一下效果
fall count是失败的次数
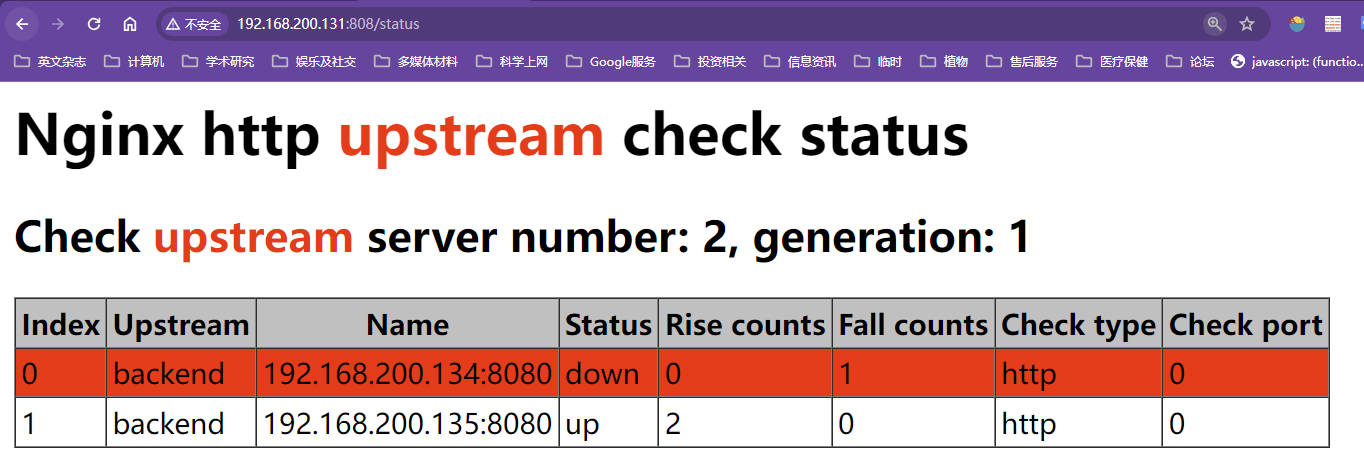
Nginx二次开发
Nginx本身和第三方模块可能也无法满足企业生产的实际需求,需要在原有基础上做一些改动,改动一般有两种,第一种是对源码即Nginx的C语言上的编译开发,难度对很多程序员来说是比较大的;第二种是基于Lua对Nginx的一些基础功能做扩展,这种方式更简单一些;
在性能方面,C语言开发在系统上的执行效率更高,Lua开发性能比C语言低一些,但是会明显高于其他语言【Nginx还可以使用PHP等其他语言做扩展】,包括现在大家认为的性能之王nodejs;使用Lua可以略微牺牲一点性能,提升开发上的便捷
有很多的开源项目使用Lua做二次开发,比较知名的有高性能开源网关Kong,API Six等、软防火墙AWF都选择使用Lua+nginx进行开发,使用时稳定性和可靠性以及开发难度上都比较友好
Lua是里约热内卢天主教大学的一个巴西人小组开发的脚本语言,像python、js都属于脚本语言【脚本语言是在执行的过程中进行解释】,脚本语言一般运行在客户端,因为一般脚本语言都是轻量级的,脚本语言功能不是很强大,但是执行效率很高
Luajit相对于Lua就相当于jdk对于java,是Lua的解析器,除了包含对lua的解析器还有一些基础的功能包,使用也是使用Luajit,Nginx可以内嵌Luajit来执行lua脚本,OpenResty是将额外的一些扩展包集成在Nginx中【用java进行类比就是Lua是java,Luajit是jdk,nginx是运行的平台,OpenResty相当于Spring全家桶,里面有很多基础使用的脚手架,比如对http请求的处理、对字符串的处理、还有很多类似模板引擎的工具包,总之把基础语言做的更完善且有很多脚手架,OpenResty集成了Luajit和很多第三方的包并且有机的整合在一起,相当于web容器平台,非常伟大好用,社区也比较活跃,像nginx一样每个点背后都是非常庞大的内容】
OpenResty是国人开发开源在全世界都非常有影响力的中间件,Lua不是专门面向web开发的语言,很多游戏也会使用Lua语言【魔兽世界中就有很多.lua的脚本文件,而且都是源码;很多手游也会使用】,选择Lua第一是因为小巧,第二是速度比较快,适用于空间狭小但是需要完成逻辑判断的环境【比如mysql数据库对比到sqlLite,如果是内嵌到手机上一般就会选择更轻量的SQLLite】
Lua语言不适合大量功能模块的开发,脚本语言在团队配合时会显得比较捉襟见肘,代码量一大就非常难维护;也不期望在nginx中做非常重量级的开发,比如在nginx中去做一个ERP系统,这是不合理的;但是只是想做一些功能,比如屏蔽一些请求,更灵活的做反向代理【按照自定义的逻辑或者算法去做负载均衡就可以使用Lua去写一些模块和go语言一样适合开发一些高性能的组件】,Lua语言因为比较小巧,会在自身和开发上带来很多缺陷,开发和调试比较麻烦,Nginx中开发的Lua脚本需要在Nginx中实际跑起来才能通过web端去做测试
开发Lua脚本过程中IDE可以使用的插件
EmmyLua和LDT是基于IDE开发Lua脚本的插件,实际上Lua的语法很简单,而且Nginx中简单功能开发只有几百行甚至几十行,很多时候根本用不上IDE,IDE主要是一些复杂逻辑写好以后在本地跑做测试用的,IDE更多时候用来像写游戏客户端等本地脚本才会用到IDE,因为C/S架构系统调试在本机上都能运行【不需要通过web端访问就能进行调试】
EmmyLua插件
Git仓库和官方文档:https://github.com/EmmyLua/IntelliJ-EmmyLua
中文文档:https://emmylua.github.io/zh_CN/
支持IntelliJ,IDEA可以直接将这个插件内置在IDEA中,功能是代码补全,调用Luajit去执行写好的程序
LDT插件
Eclipse上的Lua开发插件
官网:https://www.eclipse.org/ldt/
有LDT客户端,解压就能使用
Lua基础语法
老师这里演示用的Eclipse的LDT客户端,直接从网址https://eclipse.dev/ldt/下载客户端Stable release (1.4.2),不使用eclipse插件,安装插件比较麻烦,以后mark
使用LDT创建Lua项目
创建新Lua项目
设置项目名称和Luajit版本
名称随意,版本使用默认的5.1即可
基础语法
没讲完,涵盖Lua程序百分之七八十的内容,以后系统学;以下内容组合也能写出比较复杂的Lua程序
main函数
对应Java中的main方法
这也是定义函数的方法,local是作用域,function表示这是一个函数,main是函数名,括号中可以接参数
括号到end间的区域就是写代码的地方
最下面的
main()是去调用上面定义的main方法点击绿色的运行按钮--run as--lua Application
xxxxxxxxxxlocal function main()endmain()关键字
不能作为变量取名字
nil是空值,表示访问的是一个没有声明过的变量,相当于java和c语言中的NULL
and break do else elseif end false for function if in local nil not or repeat return then true until while 注释
单行注释
xxxxxxxxxx--两个减号是单行注释多行注释
xxxxxxxxxx--[[多行注释,可以换行]]
数据类型
Lua的基本数据类型很少,只有字符串和基本的64位的double数字类型,在lua内部会帮我们自动转型
数字类型
数字变量直接写数字,不用写具体类型,弱类型,只有执行的时候才知道数字是那种类型的
【数字类型实例】
xxxxxxxxxxnum = 1024num = 3.0num = 3.1416num = 314.16e-2num = 0.31416E1num = 0xffnum = 0x56字符串类型
【字符串类型实例】
可以用单引号,也可以用双引号,还可以使用两个中括号【两个中括号的字符串可以是多行字符串,而且貌似里面的特殊符号不需要转义】
字符串中可以使用转义字符
\n【换行】、\r【回车】、\t【横向制表】、\v【纵向制表】、\\【反斜杠】、\”【双引号】、 以及\'【单引号】等等lua拼接字符串和变量需要在变量前面使用
..,java是在变量两边用+号xxxxxxxxxxa = 'alo\n123"'a = "alo\n123\""a = '\97lo\10\04923"'a = [[alo123"]]【字符串可以带换行效果】
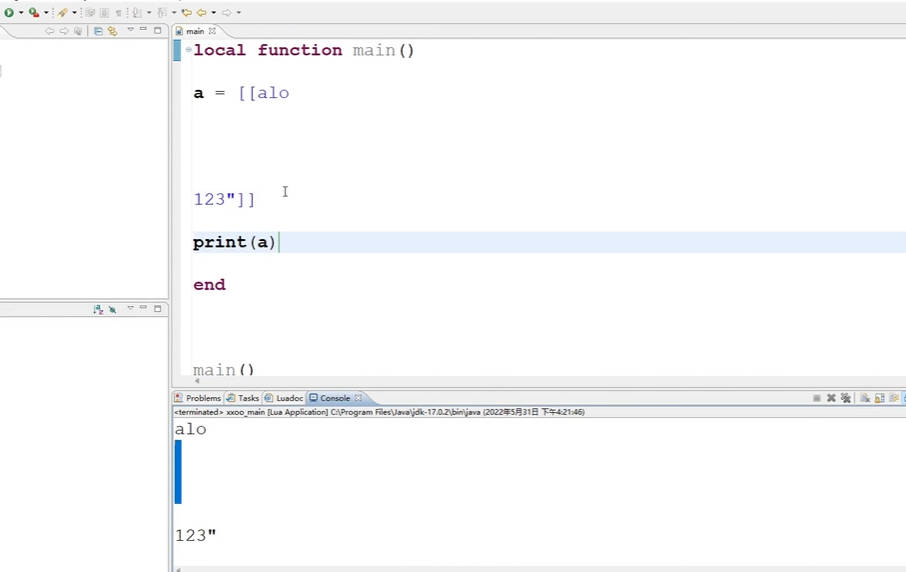
布尔类型
false可以用
false和nil表示true可以使用数字
0和空字符串'\0'表示
作用域
变量前加local关键字是局部变量
此外变量前没有任何特殊说明全是全局变量
函数或者语句块中的定义的变量没有local关键字都是全局变量,可以在任何地方进行调用
打印函数
print(String),print(name,bol)print函数是Lua的内置函数,向终端控制台打印字符串,是换行打印;如果用逗号隔开是打印两个变量值,用制表符【不像空格,比空格宽很多】隔开
while循环
定义局部变量
i为0,局部变量max为10,当i小于等于10时执行打印i并让i加1end是循环体的end,和函数的end不是同一个end
xxxxxxxxxxlocal i = 0local max = 10while i <= max doprint(i)i = i +1endfor循环
i初始值为100,想要i<1,每次循环i每次减去2;i = 1, 100, 2表示i等于1,i小于100,每次循环i加上2xxxxxxxxxxsum = 0for i = 100, 1, -2 dosum = sum + iendprint(sum)if-else
定义一个年龄140,性别男;
如果年龄为40且性别为男则打印
男人四十一枝花【很多脚本语言的逻辑判断都是if...then,then后面是匹配上条件以后执行的代码,且C语言系的if后面要加括号,VBScript这一系的if后面不需要加括号】;中间的其他逻辑判断选项使用
elseif...then连接,相当于java中的else if;【~=意思是不等于】最后总的兜底逻辑判断用else衔接;【lua拼接字符串和变量需要在变量前面使用
..,java是在变量两边用+号】循环体的最后用end结束
xxxxxxxxxxlocal function main()local age = 140local sex = 'Male'if age == 40 and sex =="Male" thenprint(" 男人四十一枝花 ")elseif age > 60 and sex ~="Female" thenprint("old man!!")elseif age < 20 thenio.write("too young, too simple!\n")elseprint("Your age is "..age)endend-- 调用main()定义函数
定义一个名为myPower的函数,下面的演示是在main函数中又定义了一个myPower函数,作用是两个参量之和,后面调用函数并传参,将结果传递给变量power2并打印
函数可以嵌套定义
千万别把最后的
main()漏了,不然程序压根不会执行xxxxxxxxxxlocal function main()function myPower(x,y)return y+xendpower2 = myPower(2,3)print(power2)endmain()匿名函数
在函数
newCounter()中定义匿名函数【匿名函数没有名字】,newCounter()返回的是匿名函数,匿名函数的第一次执行结果其实就是1,这种写法类似于javaScript中的闭包,c1是获取匿名函数【本次获取不会进行一次计算,只会为匿名函数的变量赋初始值,这个变量初始值作为全局变量会累加,此时只是执行匿名函数,并没有执行
local i = 0】,此后的c1()会执行匿名函数并且将结果返回,其中匿名函数的变量i累加1;执行一次就会累加一次【理解成执行c1 = newCounter()就将newCounter()返回的匿名函数以c1作为方法名了,匿名函数中的变量i是c1函数中完全独立的变量【看做是完全独立的变量】,又是全局变量且没有初始化动作,所以每次执行都会累加】xxxxxxxxxxfunction newCounter()local i = 0return function() -- anonymous functioni = i + 1print('i为'..i)return iendendc1 = newCounter()print(c1()) --> 1print(c1()) --> 2print(c1())【执行效果】
成员函数
person是一个Table,可以在Table中自定义没有的方法,通过
Table名.函数名()对成员函数进行调用xxxxxxxxxxlocal function main()person = {name='旺财',age = 18}function person.eat(food)print(person.name .." eating "..food)endperson.eat("骨头")endmain()函数返回值
变量赋值
可以多个变量同时赋值,根据顺序进行匹配,
数量对不上也不会报错,多出来的字面值不会用上;
字面值少了多出来的参数会赋值控制nil
xxxxxxxxxxname,age,isGay = "yiming", 37, false, "yimingl@hotmail.com"print(name,age,isGay)返回值
就是return的值可以return两个甚至多个值,java就不行,需要搞到集合、数组或者对象里面返回,在拉出来分割
xxxxxxxxxxfunction isMyGirl(name)--这里返回的是两个参数,一个是判断name和'xiao6'是否相等的布尔值、一个是传递name变量的值return name == 'xiao6' , nameend--按照变量赋值的规则获取isMyGirl函数的多个返回值并赋值给bol和name变量local bol,name = isMyGirl('xiao6')print(name,bol)
Table
Table就像java中使用的map,即key-value的形式存储数据
dog就是一个Table,并不是一个Map,因为Table中除了键值对还能放一些额外的东西【感觉Table有点像对象,但是Lua不支持面向对象,只能通过Table模拟出来看起来好像是面向对象的方式】,dog也能直接打印【打印的是Table的内存地址,没有toString()】dog中可以通过key获取到值并给对应的key赋值或者获取更改Table中的值
xxxxxxxxxxlocal function main()dog = {name='111',age=18,height=165.5}dog.age=35print(dog.name,dog.age,dog.height)print(dog)endmain()数组
数组只有value,没有key;依靠下标去取value;数组的value还可以是自定义函数,而且还是匿名的【牛皮】;而且匿名函数只会在取value并以方法调用的方式才会执行。
arr[4]可以看做匿名函数的方法名数组的下标是从1开始的【Lua的下标都是从1开始】
xxxxxxxxxxlocal function main()arr = {"string", 100, "dog",function() print("wangwang!") return 1 end}print(arr[4]())endmain()【数组遍历】
使用
for k,v in pairs(数组变量) do函数可以将数组拆成key-value的形式,k是下标,v是对应下标的值;每次循环是按顺序取值并赋值给k,vxxxxxxxxxxarr = {"string", 100, "dog",function() print("wangwang!") return 1 end}for k, v in pairs(arr) doprint(k, v)endend
OpenResty
OpenResty的官方网站:http://openresty.org
OpenResty的开源项目
OpenResty是非常庞大的技术社区,现在只是入门的阶段,Nginx二次开发万里长征的第一步,真要做Nginx的二次开发,需要深入学习Lua语言,熟悉OpenResty相关的API,甚至需要去看Nginx和OpenResty的源代码才能写出高效的程序,有很多开源项目已经将这些程序用Lua写出来了,比如比较流行的网关Kong等,有精力可以继续学习
Kong
基于Openresty的流量网关
Kong 基于 OpenResty,是一个云原生、快速、可扩展、分布式的微服务抽象层(Microservice Abstraction Layer),也叫 API 网关(API Gateway),在 Service Mesh 里也叫 API 中间件(API Middleware)。Kong 开源于 2015 年,核心价值在于高性能和扩展性。从全球 5000 强的组织统计数据来看,Kong 是现在依然在维护的,在生产环境使用最广泛的 API 网关。
提供鉴权、防刷、做请求的路由等功能
核心优势:
可扩展:可以方便的通过添加节点水平扩展,这意味着可以在很低的延迟下支持很大的系统负载。
模块化:可以通过添加新的插件来扩展 Kong 的能力,这些插件可以通过 RESTful Admin API 来安装和配置。
在任何基础架构上运行:Kong 可以在任何地方都能运行,比如在云或混合环境中部署 Kong,单个或全球的数据中心。
APISIX
这个也是基于OpenResty开发的
ABTestingGateway
一个可以动态设置分流策略的网关
ABTestingGateway 关注与灰度发布相关领域,基于 Nginx 和 ngx-lua 开发,使用 Redis 作为分流策略数据库,可以实现动态调度功能。ABTestingGateway 是新浪微博内部的动态路由系统 dygateway 的一部分,目前已经开源。在以往的基于 Nginx 实现的灰度系统中,分流逻辑往往通过 rewrite 阶段的 if 和 rewrite 指令等实现,优点是性能较高,缺点是功能受限、容易出错,以及转发规则固定,只能静态分流。ABTestingGateway 则采用 ngx-lua,通过启用 lua-shared-dict 和 lua-resty-lock 作为系统缓存和缓存锁,系统获得了较为接近原生 Nginx 转发的性能。
核心优势:
支持多种分流方式,目前包括 iprange、uidrange、uid 尾数和指定uid分流
支持多级分流,动态设置分流策略,即时生效,无需重启
可扩展性,提供了开发框架,开发者可以灵活添加新的分流方式,实现二次开发
高性能,压测数据接近原生 Nginx 转发
灰度系统配置写在 Nginx 配置文件中,方便管理员配置
适用于多种场景:灰度发布、AB 测试和负载均衡等
WAF
软防火墙,做一些基础的防护,如防刷、SQL注入、黑白名单等;这些软防火墙的功能不是很有价值,也不在高效,因为市面上有很多此类产品,但是其中的字典库对规则的匹配是比较有价值的,为的是更好的防止恶意请求
Git仓库:https://github.com/unixhot/waf、https://github.com/loveshell/ngx_lua_waf
核心优势:
防止 SQL 注入,本地包含,部分溢出,fuzzing 测试,XSS/SSRF 等 Web 攻击
防止 Apache Bench 之类压力测试工具的攻击
屏蔽常见的扫描黑客工具,扫描器
屏蔽图片附件类目录执行权限、防止 webshell 上传
支持 IP 白名单和黑名单功能,直接将黑名单的 IP 访问拒绝
支持 URL 白名单,将不需要过滤的 URL 进行定义
支持 User-Agent 的过滤、支持 CC 攻击防护、限制单个 URL 指定时间的访问次数
支持支持 Cookie 过滤,URL 与 URL 参数过滤
支持日志记录,将所有拒绝的操作,记录到日志中去
OpenResty的安装
安装方式有两种,一种是使用OpenResty对不同系统提供的预编译包,通过yum命令直接安装;第二种是直接去官方网站下载源码包然后进行编译安装
源码包下载地址【也是官方网站】:http://openresty.org/cn/download.html,新版本的OpenResty默认使用Luajit作为默认的编译器,不需要再额外安装Luajit了,下载OpenResty-1.21.4.1版本【基于最新版的Nginx1.21开发的】
OpenResty和Nginx都在走向付费提供很多不必要重复开发的内容,很多时候雇佣程序员开发相同的内容不一定有买的来的可靠
源码包编译安装
将压缩包
openresty-1.21.4.1.tar.gz上传至目录/opt/nginx/下,并使用命令tar -zxvf openresty-1.21.4.1.tar.gz解压压缩包进入OpenResty的解压目录,使用命令
./configure --prefix=/usr/local/openresty预编译OpenResty目前没有加载其他的组件,不需要额外的内容
需要的依赖包括
gcc openssl-devel pcre-devel zlib-devel,可以使用命令yum install gcc openssl-devel pcre-devel zlib-devel postgresql-devel安装这些依赖,我这里玩Nginx的时候已经安装过了,依赖安装可以直接忽略使用命令
./configure --help可以查看更多的预编译选项使用命令
make对OpenResty进行编译,使用命令make install对OpenResty进行安装安装成功测试:在目录
/usr/local/openresty下能看到如下目录结构相比于nginx多了几个目录,Luajit是编译器;lualib中有很多OpenResty开发的包,
/lualib/resty目录中有和dns、lrucache、limit、redis连接、mysql连接和一些哈希算法相关的包【这些都是Nginx中没有的,可以借助这些包做一些开发】;lua这些代码在使用的使用不需要像Nginx加载c语言写的模块需要load或者编译在运行程序中,可以通过动态引用来进行使用【可以理解为明文的脚本代码,需要的时候把代码跑一下】;OpenResty其实就是Nginx,在原有的Nginx上添加了Luajit和其他的功能
xxxxxxxxxx[root@nginx1 openresty]# lsbin COPYRIGHT luajit lualib nginx pod resty.index site启动OpenResty前需要修改OpenResty的nginx的配置文件
/usr/local/openresty/nginx/conf/nginx.conf,避免80端口冲突我这儿将端口号改为888
在
/usr/local/openresty/nginx/sbin目录下使用命令./nginx -c conf/nginx.conf【这里的相对路径不能是./nginx -c ../conf/nginx.conf,会报错,但是很奇怪,conf目录明明在sbin目录的同级目录,为什么这里相对路径不需要出sbin目录】启动openResty使用命令
./nginx -s stop停止nginx的运行【因为没有写运行脚本,目前只有通过手动启停来重新加载配置文件内容】
在浏览器使用URL
192.168.200.131:888对OpenResty的默认页进行访问,可以观察到以下效果即为启动成功意思是OpenResty成功被安装,文档在https://openresty.org,商业付费的支持在https://openresty.com/
在博客https://blog.openresty.com/中对CPU占用变高和内存占用变高有一些解决方案

在nginx中测试一下lua脚本
lua脚本写在Nginx的配置文件中
方式一
在nginx.conf中添加一个location写lua脚本
location中除了lua就没有其他东西了,没有proxy_pass或者root根目录,全是由Lua代码负责输出内容
这种方式存在一个弊端,因为配置文件主要是做配置用的,不是拿来做编程用的;一旦lua代码多了,配置文件会非常庞大,这就引申出第二种方式在配置文件nginx.conf中引入Lua脚本
xxxxxxxxxxserver {listen 888;server_name localhost;#charset koi8-r;#access_log logs/host.access.log main;#以下这段lua代码在OpenResty的初始化配置中就已经有了location /lua {#意思是返回的内容以html的形式展现出来,其实就是添加响应头Content-Type让浏览器识别直接下载不要展示default_type text/html;#content_by_lua就表示lua开始执行参与请求处理了,lua的内容在引号之间#函数ngx.say是在nginx中输出参数内容,这里的参数内容是字符串content_by_lua 'ngx.say("<p>Hello, World!</p>")';}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}【测试效果】
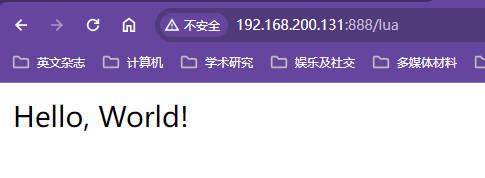
方式二
在nginx.conf的location下使用命令
content_by_lua_file lua脚本的相对或绝对路径;引入lua脚本,Lua脚本的根目录在nginx的主目录下在nginx的根目录下创建lua目录,在lua目录下创建lua脚本文件
hello.lua,向脚本文件中写入以下内容【hello.lua】
xxxxxxxxxxngx.say("<p>Hello, World!!!</p>")修改配置文件
nginx.conf,将原来lua脚本直接写入配置文件的站点目录改为在站点目录中引入lua脚本经过测试,因为期间lua脚本的相对路径写错了,导致页面不展示,更改以后正常展示,由此证明实现了相应的效果
注意因为还是在配置文件中引入了lua脚本,所以更改了lua脚本还是需要重启Nginx
xxxxxxxxxxserver {listen 888;server_name localhost;location /lua {default_type text/html;content_by_lua_file lua/hello.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}测试效果
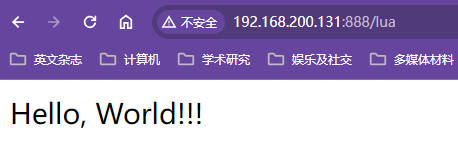
开启lua脚本热部署
因为每次修改lua脚本以后都需要重启nginx,很不方便,在http模块下使用命令
lua_code_cache off;来开启lua脚本的热部署这个热部署生产环境不要开,对性能影响比较大;设置该指令后关闭nginx会提示
nginx: [alert] lua_code_cache is off; this will hurt performance in /usr/local/openresty/nginx/conf/nginx.conf:13,意思是设置该指令会损伤nginx的性能;这是因为lua在OpenResty中去跑是介于脚本语言和静态编译语言之间的动态语言,性能比较高,但是如果编程纯粹的脚本语言或者解释型语言,每次请求的时候都会去重新加载执行一遍,浪费性能【没听懂,以后理解】;但是开发的时候方便程序员去重启nginx这个热部署只是针对lua脚本文件修改,修改了主配置文件还是需要重启nginx
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;#以下命令是开启lua脚本的热部署,关闭以后修改lua脚本就不需要再重启nginx了lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;content_by_lua_file lua/hello.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}
Lua脚本获取系统变量
获取请求的变量并在通过lua对变量进行加工,有这些请求参数和信息就可以针对这些信息使用lua做一些额外的开发
Lua获取请求头信息
local headers = ngx.req.get_headers():获取当前请求的头信息headers["Host"]:请求的ip和端口,key不区分大小写headers["user-agent"]:请求的客户端信息【也可以通过headers.user_agent获取对应的属性值】脚本hello.lua
xxxxxxxxxxlocal headers = ngx.req.get_headers()ngx.say("Host : ", headers["Host"], "<br/>")ngx.say("user-agent : ", headers["user-agent"], "<br/>")ngx.say("user-agent : ", headers.user_agent, "<br/>")for k,v in pairs(headers) doif type(v) == "table" thenngx.say(k, " : ", table.concat(v, ","), "<br/>")elsengx.say(k, " : ", v, "<br/>")endend执行效果
实际上headers中的所有参数从第4行到11行一共八个参数
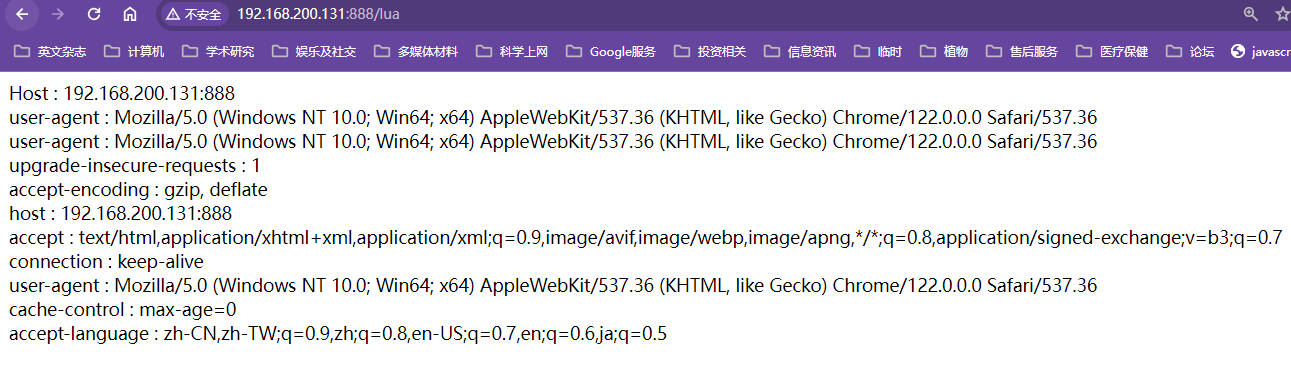
处理Http请求的其他方式
没说怎么用,只是说除了
content_by_lua_file还可以使用以下命令修改系统变量,猜测是和content_by_lua_file一样使用在location中set_by_lua修改nginx中的系统变量
rewrite_by_lua修改nginx中的uri
access_by_lua访问控制
header_filter_by_lua修改响应头
boy_filter_by_lua修改响应体
log_by_lua日志交互
Lua获取Post请求的请求参数
hello.lua
核心还是通过
local post_args = ngx.req.get_post_args()获取到Post请求的请求参数列表然后对请求参数列表进行遍历xxxxxxxxxxngx.req.read_body()ngx.say("post args begin", "<br/>")local post_args = ngx.req.get_post_args()for k, v in pairs(post_args) doif type(v) == "table" thenngx.say(k, " : ", table.concat(v, ", "), "<br/>")elsengx.say(k, ": ", v, "<br/>")endend执行效果
这个需要发送post请求才能看见效果,get请求参数列表为空,但是不会报错,使用postman进行测试
注意参数要放在请求体中的表单去提交
postman执行效果
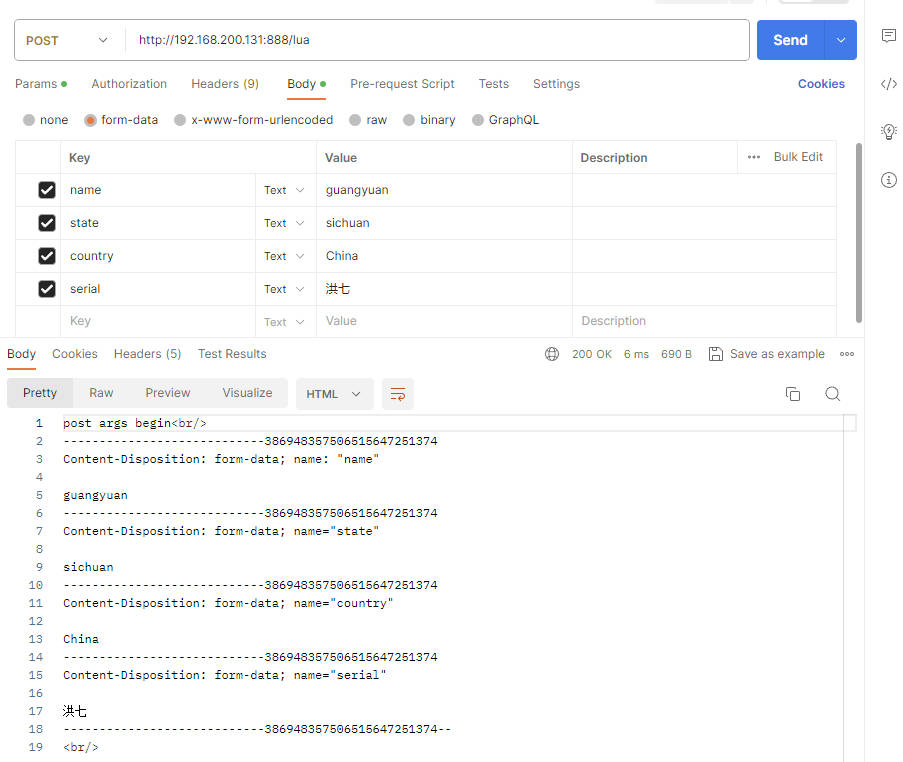
Lua获取uri中的单一变量
nginx.conf
xxxxxxxxxxlocation /nginx_var {default_type text/html;content_by_lua_block {ngx.say(ngx.var.arg_a)}}
Lua获取请求Uri中的所有变量
hello.lua
xxxxxxxxxxlocal uri_args = ngx.req.get_uri_args()for k, v in pairs(uri_args) doif type(v) == "table" thenngx.say(k, " : ", table.concat(v, ", "), "<br/>")elsengx.say(k, ": ", v, "<br/>")endend
Lua获取请求的通用信息
以下代码全部在hello.lua脚本中
获取http协议版本
ngx.req.http_version()xxxxxxxxxxngx.say("ngx.req.http_version : ", ngx.req.http_version(), "<br/>")获取请求的方法
ngx.req.get_method()xxxxxxxxxxngx.say("ngx.req.get_method : ", ngx.req.get_method(), "<br/>")获取原始的请求头内容
ngx.req.raw_header()【最原始的整个请求头文本】xxxxxxxxxxngx.say("ngx.req.raw_header : ", ngx.req.raw_header(), "<br/>")获取请求的请求体内容
ngx.req.get_body_data()xxxxxxxxxxngx.say("ngx.req.get_body_data() : ", ngx.req.get_body_data(), "<br/>")
Nginx的进程缓存
OpenResty提供两种方式去Nginx内存中操作缓存数据,促进提高系统的并发量承载能力
此前nginx做内存缓存只能缓存一些文件句柄或者静态资源文件索引列表,或者IP并发列表、IP的QPS数据,现在通过OpenResty的进程缓存空间能够缓存自定义数据,一般也是存储少量的数据,比如计数等数据,不会存储内容很大的数据;一方面是内存容易被撑爆,第二是类似于shared_dict这种字典式的内存存储在修改数据的时候会有锁的产生,对内存中响应数据的QPS有影响
方式一是使用shared_dict
方式一:在lua脚本中使用
lua_shared_dictshared_dict性能比较高效,在多个worker进程中可以去共享一份缓存数据,因为多进程操作一份缓存数据,一定会涉及到锁的产生,有点像在nginx中跑一个小型的redis
核心一:在lua脚本中使用变量
shared_data = ngx.shared.shared_data来操纵缓存数据核心二:同时使用shared_dict需要在主配置文件的http模块中声明shared_dict和其大小
hello.lua
xxxxxxxxxx--操作shared_dict的缓存数据需要获取到shared_data对象local shared_data = ngx.shared.shared_data--从shared_dict的缓存数据中通过key为i获取对应的值local i = shared_data:get("i")--如果i没有数据那么将i设置为1if not i theni = 1--向shared_dict的缓存数据中通过set方法向缓存空间设置key为i的数据的值为i的值shared_data:set("i", i)--打印向缓存空间内设置了i-1这个键值对数据ngx.say("lazy set i ", i, "<br/>")end--如果之前已经有了对应i的数据,对应缓存空间中i的数据再自加1,并将结果取出赋值给ii = shared_data:incr("i", 1)--打印当前缓存空间中key为i的数据的值ngx.say("i=", i, "<br/>")nginx.conf
声明shared_dict的空间大小,表示申请1M内存去做进程间的内存缓存,该内存缓存能够被所有的worker进程进行访问并且能保证原子性
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;#声明shared_dict的空间大小,表示申请1M内存去做进程间的内存缓存,该内存缓存能够被所有的worker进程进行访问并且能保证原子性lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;content_by_lua_file lua/hello.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}请求访问效果
这是从缓存空间取出的数据,中间还涉及到使用Lua代码对key为i的数据的创建和自增操作
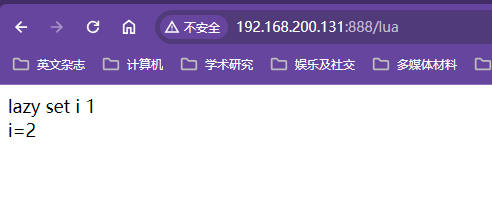
方式二:使用
lua-resty-lrucache模块做内存缓存LRU缓存对比shared_dict的功能更加强大一些,该模块纯粹用Lua语言实现的,由Lua官方提供的模块,也可以像shared_dict一样在nginx的内存中使用缓存,且运行在独立的进程中,单进程的增删改操作不需要添加锁,做一些修改操作的时候性能会更高一些,但是一般使用时不会感觉和shared_dict在性能上的差异【性能上的差异并不是很大,差别就在一个有锁,一个没有锁】,LRU缓存可以额外做LRU算法上的清理工作;同时LRU缓存是以key-value的数量个数作为大小的限制、shared_dict是以缓存空间的内存占用大小来作为限制,shared_dict能更有效地控制系统内存缓存空间的大小占用,LRU没法预估内存缓存空间的大小,这种大小的限制需要对每一个key-value的大小需要提前预测感知才行,但是内存也更加弹性化,不会导致因为内存空间占满了导致数据写不进去
Git仓库和官方文档:https://github.com/openresty/lua-resty-lrucache
lua-resty-lrucache默认就已经在OpenResty的目录下了,资源文件路径/usr/local/openresty/lualib/resty/lrucache.luaLRU缓存使用时一定要关闭lua脚本的热部署,即不能使用
lua_code_cache off;,默认是on官方推荐的用法是在lua脚本中自定义函数来使用
一定要保证初始化操作只能被执行一次,包括连接mysql和redis的数据库连接池时也是一样只能执行一次,否则是用不上此前使用过的连接或者缓存空间的,Lua如何保证只执行一次某个代码片段没有讲,这里后续自己学习【还没讲呢,这里第一次演示的就是每次请求都执行一次初始化代码的情况】,实际上这里的代码确实只会执行一次,这个也是全局变量,但是因为在主配置文件开启了lua脚本的热部署,lua_code_cache off;关闭了lua代码的缓存,每次请求结束lua代码创建的全局参数缓存都会不使用
【cache.lua】
该文件在
/usr/local/openresty/lualib/my/cache.luaxxxxxxxxxx--定义一个数组local _M = {}local _M = {}--这部分到第一个end之间的代码在lua脚本热部署关闭的情况下只能执行一次,这部分是内存空间初始化的部分,每次请求都执行会导致每次用的缓存空间都是新的,永远在执行第一次的代码。后续请求也无法获取到此前请求存入缓存中的数据;实际上这里的代码确实只会执行一次,这个也是全局变量,但是因为在主配置文件开启了lua脚本的热部署,lua_code_cache off;关闭了lua代码的缓存,每次请求结束lua代码创建的全局参数缓存都会不使用lrucache = require "resty.lrucache"c, err = lrucache.new(200) -- allow up to 200 items in the cache,初始化内存缓存空间,表示能承载200个键值对ngx.say("count=init")--如果c没有被附上值,c没有值为false,not false即为true,即创建缓存空间出现问题就会报错if not c thenerror("failed to create the cache: " .. (err or "unknown"))end--这个是在数组_M中的一个元素定义一个go函数,在这个方法中去向缓存空间操作键值对function _M.go()--从缓存空间中获取key为count的键值对valuecount = c:get("count")--将缓存空间中key为count的键值对的value设置成100,这一步是不是多余了,反正后面都会重新赋值c:set("count",100)--打印最开始从缓存中取出的key为count的value值ngx.say("count=", count, " --<br/>")--如果没有从缓存中获取到对应key为count的value值if not count then--向缓存空间设置键值对count-1c:set("count",1)--打印首次向缓存空间中设置键值对count-1ngx.say("lazy set count ", c:get("count"), "<br/>")else--如果有值直接让值加1并打印没有加1以前的count,即这里的count+1是为了下次请求访问准备获取的值,因为这里目前每次请求都会创建一次缓存空间,所以获取到的count永远是初始化的值1,而且以后得请求都无法拿出上一个请求向缓存中设置的值c:set("count",count+1)ngx.say("count=", count, "<br/>")endendreturn _M在主配置文件中使用
content_by_lua_block来对lua函数进行调用xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;#声明shared_dict的空间大小,表示申请1M内存去做进程间的内存缓存,该内存缓存能够被所有的worker进程进行访问并且能保证原子性lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#content_by_lua_file lua/hello.lua;#在该代码块中去调用lua脚本中的函数方法,require相当于引入lua的代码文件,这个是有默认根目录的,需要在日志文件看报错信息来找到对应的根目录位置,貌似在引入的时候执行了一次对应的代码块,这个引入似乎不像content_by_lua_file一样每个请求都会执行一次,而是后续只去调用其中返回的数组的go函数,开启了lua_code_cache off;会导致引入的代码执行产生的对象无法被缓存,content_by_lua_block {require("my/cache").go()}}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}【require引入脚本文件的位置报错信息】
这里找文件my/cache,通过访问
/lua站点,因为没有该文件,错误日志会显示在所有可能目录中没有对应的文件默认的lua文件可以存在的地方的根目录如下所示,根目录下是一个根目录,lualib也是一个目录
xxxxxxxxxx2024/01/13 18:15:39 [error] 45316#0: *1 lua entry thread aborted: runtime error: content_by_lua(nginx.conf:30):2: module 'my/cache' not found:no field package.preload['my/cache']no file '/usr/local/openresty/site/lualib/my/cache.ljbc'no file '/usr/local/openresty/site/lualib/my/cache/init.ljbc'no file '/usr/local/openresty/lualib/my/cache.ljbc'no file '/usr/local/openresty/lualib/my/cache/init.ljbc'no file '/usr/local/openresty/site/lualib/my/cache.lua'no file '/usr/local/openresty/site/lualib/my/cache/init.lua'no file '/usr/local/openresty/lualib/my/cache.lua'no file '/usr/local/openresty/lualib/my/cache/init.lua'no file './my/cache.lua'no file '/usr/local/openresty/luajit/share/luajit-2.1.0-beta3/my/cache.lua'no file '/usr/local/share/lua/5.1/my/cache.lua'no file '/usr/local/share/lua/5.1/my/cache/init.lua'no file '/usr/local/openresty/luajit/share/lua/5.1/my/cache.lua'no file '/usr/local/openresty/luajit/share/lua/5.1/my/cache/init.lua'no file '/usr/local/openresty/site/lualib/my/cache.so'no file '/usr/local/openresty/lualib/my/cache.so'no file './my/cache.so'no file '/usr/local/lib/lua/5.1/my/cache.so'no file '/usr/local/openresty/luajit/lib/lua/5.1/my/cache.so'no file '/usr/local/lib/lua/5.1/loadall.so'stack traceback:coroutine 0:[C]: in function 'require'content_by_lua(nginx.conf:30):2: in main chunk, client: 192.168.200.1, server: localhost, request: "GET /lua HTTP/1.1", host: "192.168.200.131:888"【更改Lua脚本的根目录】
Lua脚本的根目录也可以通过在主配置文件的http模块下通过以下配置设置,这是将lua脚本的目录修改到绝对路径
/path/to/lua-resty-lrucache/lib/下,上面的演示不采用这种方式,选择在lualib目录下创建my目录,在该目录下存放自定义的lua脚本文件xxxxxxxxxx# nginx.confhttp {# only if not using an official OpenResty releaselua_package_path "/path/to/lua-resty-lrucache/lib/?.lua;;";...}执行效果
count=init是文件cache.lua通过代码ngx.say("count=init")打印的日志,通过测试发现目前每次请求都会去执行一次cache.lua文件中的代码,c, err = lrucache.new(200)创建缓存空间的代码后面紧跟的就是打印count=init的代码,每次请求都打印了,说明每次请求都新创建的缓存空间,该问题需要解决,否则缓存空间根本没有办法使用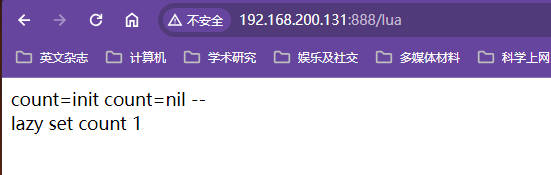
将主配置文件的
lua_code_cache off;注释掉观察多次请求的效果原因就是
lua_code_cache off;禁用Lua脚本缓存,导致require("my/cache")执行了一次该文件返回的对象无法被缓存,从而每次请求都会去执行一次初始化代码,实际生产环境中不会开启该热部署选项以下是注释掉该热部署配置后的响应效果
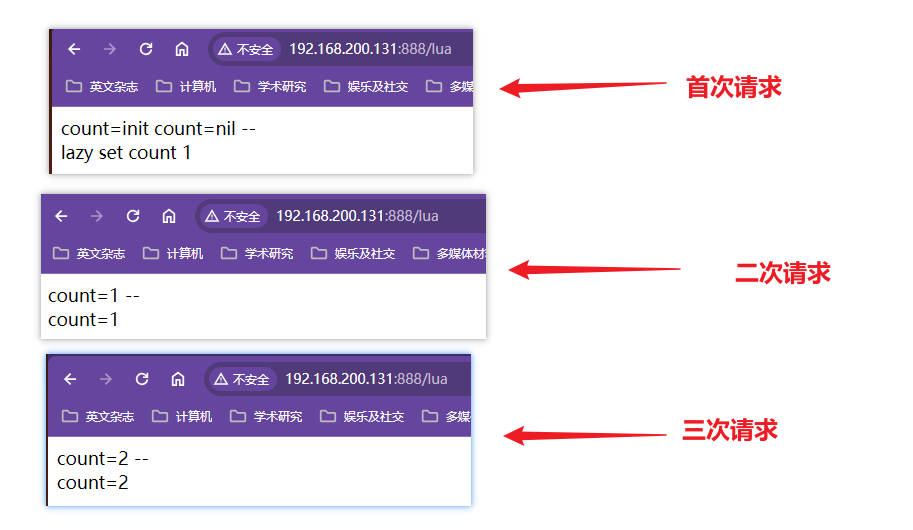
OpenResty连接Redis
OpenResty连接redis也可以使用两个模块。
模块一是此前讲过的开源版本nginx使用
redis2-nginx-module连接外置内存缓存redis【redis2-nginx-module是一个支持 Redis 2.0 协议的 Nginx upstream 模块,它可以让 Nginx 以非阻塞方式直接防问远方的 Redis 服务,同时支持 TCP 协议和 Unix Domain Socket 模式,并且可以启用强大的 Redis 连接池功能】;模块二是使用模块
lua-resty-redis访问redis,lua-resty-redis是一个纯粹使用lua脚本实现的redis客户端,同样也是OpenResty出品的,Git仓库和官方文档:https://github.com/openresty/lua-resty-redis【Lua实现的redis客户端后期可以看看源码自己进行一些更改,但是c语言实现的redis客户端【这个客户端是用来远程连接操纵redis服务器的,类似于redis-cli,不是指用lua写了一个redis,实际还是需要单独安装redis服务器】,绝大多数程序员是没有这个能力去修改的;官方文档的常用命令介绍是比较详细的,后期需要自己去研读】redis集群或者nginx集群下的lua连接redis脚本找第三方的工具包来使用,如果redis是集群,就使用
resty-redis-cluster来作为redis客户端完成集群上的数据操作,官方文档:https://github.com/steve0511/resty-redis-cluster没有特殊要求使用
redis2-nginx-module或者lua-resty-redis访问操作redis都可以,节省tomcat服务器响应的过程提高效率,这时候为了数据一致性,一般不会让nginx去写或者修改数据,一般只有计数的需求nginx才可能去操纵redis,比如记录Ip的请求次数;一般业务需求为了数据一致性不会让nginx去操作业务数据,业务数据写一般都是tomcat来进行维护;一定要使用Nginx来写入数据一定要用事务保证缓存和数据库双写的数据一致性
使用OpenResty去连接redis
好像没有单独引入
lua-resty-redis模块,而是OpenResty默认集成了该工具,通过lua命令local redis = require "resty.redis"使用的创建redis连接的lua脚本文件
/usr/local/openresty/nginx/lua/redis.luaxxxxxxxxxx--通过OpenResty自带的工具包resty.redis创建一个redis局部变量local redis = require "resty.redis"--通过局部变量redis创建一个连接对象red出来local red = redis:new()--连接超时配置,毫秒为单位red:set_timeouts(1000, 1000, 1000) -- 1 sec--设置连接地址,返回两个变量,一个ok。一个errlocal ok, err = red:connect("127.0.0.1", 6379)--如果ok的返回值没有东西,直接报错打印错误信息if not ok thenngx.say("failed to connect: ", err)returnend--如果ok有值,通过连接red向redis中设置键值对dog-an animal,仍然返回两个变量ok和err表示数据操作状态ok, err = red:set("dog", "an animal")--不ok就打印错误信息,ok就打印ok信息,且因为有return不再继续向下执行if not ok thenngx.say("failed to set dog: ", err)returnendngx.say("set result: ", ok)--通过连接red拿着dog这个key去获取对应的value,仍然返回两个返回值,查询结果或者错误信息local res, err = red:get("dog")ngx.say(res)--如果查询结果中没有值就打印错误信息并结束方法的执行if not res thenngx.say("failed to get dog: ", err)returnend--我怀疑这个也不会执行,因为res如果是空值,那么上一个判断也会成立,not res应该也为true,不管,系统学了lua在理解;经过测试,如果redis中没有对应的key,get方法返回的res会是null,但是lua中没有null,0和nil代表false,,所以这里判断没有值res的值为ngx.nullif res == ngx.null thenngx.say("dog not found.")returnendngx.say("dog: ", res)主配置文件nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#执行连接操作redis的脚本文件content_by_lua_file lua/redis.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}lua脚本执行效果

OpenResty连接mysql
OpenResty使用
lua-resty-mysql作为连接Mysql的客户端,Git仓库以及官方文档:https://github.com/openresty/lua-resty-mysql可以作为mysql客户端发送各种DML、DDL的SQL,同时支持数据库连接池,使用Nginx连接mysql最好查询条件带参数,因为OpenResty中没有预编译功能,不像jdbc的preparedStatement,有很大的风险,比如sql注入
Nginx连接mysql不是特别理想,因为特别容易将流量直接打到mysql上,大项目最好将nginx和mysql隔离开;小项目无所谓,mysql几十个字段,单条查询结果几百到2k字节间,抗个几千的并发也是没问题的
官方文档有介绍,除了mysql,还有很多其他组件也可以通过OpenResty进行连接
使用OpenResty连接mysql
创建mysql连接的lua脚本文件
/usr/local/openresty/nginx/lua/mysql.lua这里需要修改mysql的权限,否则连接会失败;设置mysql的权限把连接权限改为任何地址
mysql client 命令行输入
use mysql;update user set host = '%' where user ='root';flush privileges;xxxxxxxxxxlocal mysql = require "resty.mysql"local db, err = mysql:new()if not db thenngx.say("failed to instantiate mysql: ", err)returnend--设置连接超时时间1sdb:set_timeout(1000) -- 1 sec--配置数据库的相关信息,连接信息会返回该四个变量local ok, err, errcode, sqlstate = db:connect{host = "192.168.200.131",port = 3306,database = "zhangmen",user = "root",password = "Haworthia0715",charset = "utf8",--mysql返回数据包的最大限制,默认是一兆大小max_packet_size = 1024 * 1024,}ngx.say("connected to mysql.<br>",ok,err,errcode,sqlstate)--如果数据库中有cat就会删掉,不成功会报错local res, err, errcode, sqlstate = db:query("drop table if exists cats")--这里不能打印res[ngx.say(res)]否则也会报错,可能是res数据类型不能直接被打印的原因,使用cjson转换成json再打印此时可以,我在机器上测试过local cjson = require "cjson"ngx.say("result: ", cjson.encode(res))if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnend--创建表cat,两个字段,一个key一个nameres, err, errcode, sqlstate =db:query("create table cats ".. "(id serial primary key, ".. "name varchar(5))")if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnendngx.say("table cats created.")--这个数据库是老师提前建好并插入了数据,我不知道数据,这里执行直接就报错找不到表t_emp然后结束执行了res, err, errcode, sqlstate =db:query("select * from t_emp")if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnendlocal cjson = require "cjson"--res查询结果需要使用cjson.encode(res)被转换成json才能被输出到浏览器,即使没查到内容也需要使用cjson先转换才能输出,直接输出会报错,且cjson必须使用cjson.lua进行引入ngx.say("result: ", cjson.encode(res))--这是连接池,复用连接local ok, err = db:set_keepalive(10000, 100)if not ok thenngx.say("failed to set keepalive: ", err)returnend主配置文件nginx.conf
xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#手动设置响应内容的字符编码格式供浏览器参考,响应内容出现中文浏览器不会乱码charset utf-8;#执行连接操作redis的脚本文件content_by_lua_file lua/mysql.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}响应效果
没有t_emp数据,这里直接报错该表不存在结束脚本执行了
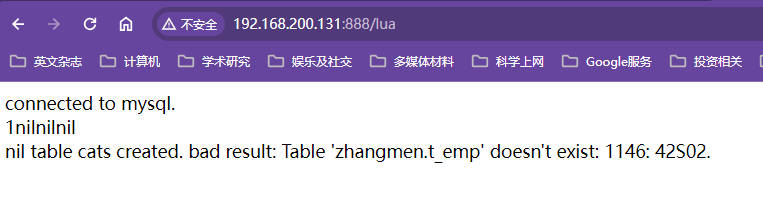
课堂实例
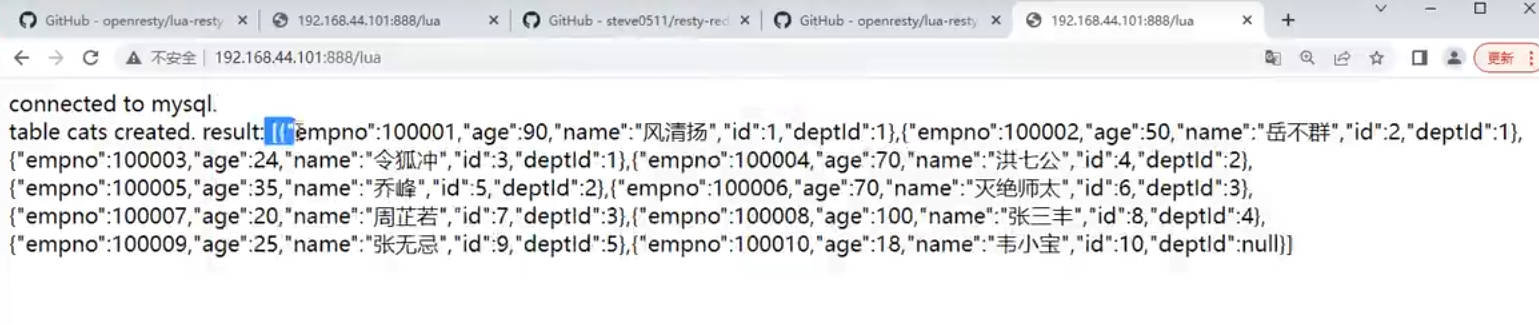
OpenResty的模板引擎
模板引擎加数据源加业务逻辑就可以做成类似SpringMVC的应用,就可以在OpenResty中开发出自己想要的应用;OpenResty的模板引擎
lua-resty-template是OpenResty提供的第三方插件,Git和官方文档:https://github.com/bungle/lua-resty-template这套模板引擎比较复杂,且实现的功能比较全面,已经和jsp、thymeleaf这种模板引擎很类似了
使用模板引擎对标签进行渲染
模版引擎还有很多其他的配置,能够让页面变得更加复杂
在OpenResty的根目录下创建模板目录
tpl,在模板目录下创建模板文件view.html模板由html和标签【标签用两个大括号括起来】组成
xxxxxxxxxx<html><body><h1>{{message}}</h1></body></html>在主配置文件中配置模板文件存放位置
在location下进行模板文件根目录配置
set $template_root /usr/local/openresty/tpl;引入Lua脚本
content_by_lua_file lua/tpl.lua;,在tpl中渲染模板xxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#OpenResty会读取该变量$template_root把对应目录设置为模板的根目录set $template_root /usr/local/openresty/tpl;charset utf-8;#使用lua脚本tpl.luacontent_by_lua_file lua/tpl.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}安装
lua-resty-template模块默认OpenResty下没有该模块,下载2.0版本
lua-resty-template-2.0.tar.gz;将文件上传到lualib目录下并解压缩【解压目录结构】
xxxxxxxxxx[root@nginx1 lua-resty-template-2.0]# ll总用量 80-rw-rw-r--. 1 root root 3074 2月 24 2020 Changes.md-rw-rw-r--. 1 root root 210 2月 24 2020 dist.inidrwxrwxr-x. 3 root root 19 2月 24 2020 lib-rw-rw-r--. 1 root root 1498 2月 24 2020 LICENSE-rw-rw-r--. 1 root root 848 2月 24 2020 lua-resty-template-dev-1.rockspec-rw-rw-r--. 1 root root 40 2月 24 2020 Makefile-rw-rw-r--. 1 root root 57916 2月 24 2020 README.md将
lua-resty-template-2.0/lib/resty/目录下的所有文件挪到lualib/resty目录下将这两个文件挪动到
/usr/local/openresty/lualib/resty目录下,挪动后剩下文件lua-resty-template-2.0可以直接删掉,xxxxxxxxxx[root@nginx1 resty]# ll总用量 24drwxrwxr-x. 2 root root 64 2月 24 2020 template-rw-rw-r--. 1 root root 23230 2月 24 2020 template.lua
在
/usr/local/openresty/lua/目录下创建lua脚本tpl.luaxxxxxxxxxx-- Using template.new--引入模板引擎的lib包/lualib/resty/templatelocal template = require "resty.template"--通过模板文件创建view对象local view = template.new "view.html"--设置模板文件中的变量值view.message = "Hello, World!"--使用上面的参数值去渲染模板文件页面数据view:render()-- Using template.render-- template.render("view.html", { message = "Hel11lo, Worl1d!" })访问效果
模版引擎的基本用法
讲的很粗糙,细节看官方文档学习
模板文件
/tpl/view.html弹幕说这个语法和django很像
xxxxxxxxxx<!--{(header.html)}表示引入另外一个模板文件,因为没有找到目标原始文件,显示效果中直接把文件名输出了,可以做不常改变文件的头和尾-->{(header.html)}<body>{# 这个是注释标签 #}<!--将参数值name变成大写,{* string.upper(name) *}能将英文字母大写-->{# 不转义变量输出 #}姓名:{* string.upper(name) *}<br/>{# 转义变量输出 #}{# {{description}}直接将内容作为字符串响应,即便是一段html标签也会原样输出,简单的说就是将特殊符号转义成字符串 #}简介:{{description}}{# {* description *}是不转义特殊字符,直接原样输出字符串,这个字符串如果是html标签或者js代码会在浏览器进行渲染 #}简介:{* description *}<br/>{# {* age + 10 *}也可以在其中引入变量和运算符做一些运算 #}年龄: {* age + 10 *}<br/>{# {% for i, v in ipairs(hobby) do %}对hobby数组进行循环遍历输出,ipairs是lua语言中的for循环写法,这就很像lua的写法,怀疑这个模版最后会转成lua语言执行,和jsp很像,且在循环体中也可以输出原生html的内容,比如- xxoo #}爱好:{% for i, v in ipairs(hobby) do %}{% if v == '电影' then %} - xxoo{%else%} - {* v *}{% end %}{% end %}<br/>成绩:{% local i = 1; %}{# 这是对键值对数据Map进行遍历,应该在lua中称为table #}{% for k, v in pairs(score) do %}{# i的初始值为1,当i大于1的时候输出逗号,即每个键值对用逗号隔开 #}{% if i > 1 then %},{% end %}{* k *} = {* v *}{% i = i + 1 %}{% end %}<br/>成绩2:{{# score2是数组,数组的每个元素是table,这是对数组中的table进行遍历,数组通过下标拿数据 #}}{% for i = 1, #score2 do local t = score2[i] %}{% if i > 1 then %},{% end %}{* t.name *} = {* t.score *}{% end %}<br/>{# {-raw-}中间的内容不解析,即便是标签也不解析,直接原样输出{(file)} #}{-raw-}{(file)}{-raw-}{(footer.html)}nginx/lua/tpl.luaxxxxxxxxxxlocal template = require("resty.template")--这个是模板引擎缓存,调试的时候可以将模板引擎缓存关掉,上线以后再打开,缓存打开以后更改模板可能不会发生变化template.caching(false)local context = {title = "测试",name = "lucy",description = "<script>alert(1);</script>",age = 40,hobby = {"电影", "音乐", "阅读"},score = {语文 = 90, 数学 = 80, 英语 = 70},score2 = {{name = "语文", score = 90},{name = "数学", score = 80},{name = "英语", score = 70},}}template.render("view.html", context)主配置文件
nginx/conf/nginx.confxxxxxxxxxxworker_processes 1;events {worker_connections 1024;}http {include mime.types;default_type application/octet-stream;lua_shared_dict shared_data 1m;lua_code_cache off;sendfile on;keepalive_timeout 65;server {listen 888;server_name localhost;location /lua {default_type text/html;#OpenResty会读取该变量$template_root把对应目录设置为模板的根目录set $template_root /usr/local/openresty/tpl;charset utf-8;#使用lua脚本tpl.luacontent_by_lua_file lua/tpl.lua;}location / {root html;index index.html index.htm;}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}}测试效果
因为这里没有
header.html和footer.html,这两文件一般放不咋变化的头和尾,因为找不到对应的文件,所以直接把文件名打印出来了header.html和footer.html都是模板文件,根目录都是和主模板文件view.html在同一个模板根目录tpl下
tpl/header.htmlxxxxxxxxxx<h1>引入的外部头组件</h1>tpl/footer.htmlxxxxxxxxxx<h1>CopyRight@2024 | 引入的外部尾组件</h1>头尾拼接效果
应用示例
Redis缓存+mysql+模板输出构建的小应用,以一个sql作为key缓存到redis中,如果通过sql从redis中获取不到对应的结果就去mysql中查询,如果没有结果就去连接mysql去数据库查,然后将查询结果扔到redis中,如果下次还有相同的sql查询,直接去redis中去获取;获取到数据以后直接渲染到模板文件上响应给客户端
这是很简陋的版本,千万不要到线上直接使用,
而且不建议使用这种方式去做比较复杂的业务,因为业务一复杂,lua脚本就要分文件,调试的时候非常难搞,一旦出错,就要看error.log,从源码上一条一条去排查错误,而且异常信息不好捕捉和展示,甚至可能出现语法错误导致项目无法运行
搭建流程
tpl.lua
这里需要创建表t_temp,还要插入数据,换个谷粒学院的edu_chapter表来进行实现
这个sql是针对请求写死在脚本中的,用户只知道点了按钮,不知道sql
xxxxxxxxxx--引入cjson工具cjson = require "cjson"--定义key即sql语句sql="select * from edu_chapter"--引入连接redis的工具local redis = require "resty.redis"local red = redis:new()red:set_timeouts(1000, 1000, 1000) -- 1 seclocal ok, err = red:connect("127.0.0.1", 6379)if not ok thenngx.say("failed to connect: ", err)returnendlocal res, err = red:get(sql)if not res thenngx.say("failed to get sql: ", err)returnendif res == ngx.null thenngx.say("sql"..sql.." not found.")--引入连接mysql的工具local mysql = require "resty.mysql"local db, err = mysql:new()if not db thenngx.say("failed to instantiate mysql: ", err)returnenddb:set_timeout(1000) -- 1 seclocal ok, err, errcode, sqlstate = db:connect{host = "192.168.200.131",port = 3306,database = "zhangmen",user = "root",password = "Haworthia0715",charset = "utf8",max_packet_size = 1024 * 1024,}ngx.say("connected to mysql.<br>")--这里从mysql查询的数据应该会自动被转换成table类型的数据res, err, errcode, sqlstate = db:query(sql)if not res thenngx.say("bad result: ", err, ": ", errcode, ": ", sqlstate, ".")returnend--ngx.say("result: ", cjson.encode(res))--把table类型数据转成json字符串,带转义符号,这个格式的json不能因为有转义符号在在线json格式化时会报错,直接以res作为value存入redis会存入res的内存地址ok, err = red:set(sql, cjson.encode(res))if not ok thenngx.say("failed to set sql: ", err)returnendngx.say("set result: ", ok)--第一次请求去mysql中拉数据并不会渲染,这里直接把数据存入redis后直接打印set result:ok就直接结束了returnendlocal template = require("resty.template")template.caching(false)local context = {title = "测试",name = "lucy",description = "<script>alert(1);</script>",age = 40,hobby = {"电影", "音乐", "阅读"},score = {语文 = 90, 数学 = 80, 英语 = 70},score2 = {{name = "语文", score = 90},{name = "数学", score = 80},{name = "英语", score = 70},},--要把json字符串转换成table对象才能在模版文件中进行渲染zhangmen=cjson.decode(res)}template.render("view.html", context)view.html
xxxxxxxxxx{(header.html)}<body>{# 不转义变量输出 #}姓名:{* string.upper(name) *}<br/>{# 转义变量输出 #}年龄: {* age + 10 *}<br/>{# 循环输出 #}爱好:{% for i, v in ipairs(hobby) do %}{% if v == '电影' then %} - xxoo{%else%} - {* v *}{% end %}{% end %}<br/>成绩:{% local i = 1; %}{% for k, v in pairs(score) do %}{% if i > 1 then %},{% end %}{* k *} = {* v *}{% i = i + 1 %}{% end %}<br/>成绩2:{% for i = 1, #score2 do local t = score2[i] %}{% if i > 1 then %},{% end %}{* t.name *} = {* t.score *}{% end %}<br/>{# 中间内容不解析 #}{-raw-}{(file)}{-raw-}掌门:{# 下一行会直接显示table的内存地址,注意注释里面不能嵌套标签,否则会报错 #}{* zhangmen *}<br>{% for i = 1, #zhangmen do local z = zhangmen[i] %}{{# 且标签外不能添加大括号 #}{* z.gmt_create *},{* z.course_id *},{* z.id *},{* z.gmt_modified *},{* z.sort *},{* z.title *}}<br>{% end %}<br/>{(footer.html)}测试效果
我是真的牛皮
使用的sql
xxxxxxxxxxCREATE TABLE `edu_chapter` (`id` char(19) NOT NULL COMMENT '章节ID',`course_id` char(19) NOT NULL COMMENT '课程ID',`title` varchar(50) NOT NULL COMMENT '章节名称',`sort` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '显示排序',`gmt_create` datetime NOT NULL COMMENT '创建时间',`gmt_modified` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`),KEY `idx_course_id` (`course_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT COMMENT='课程';## Data for table "edu_chapter"#INSERTINTO `edu_chapter`VALUES('1','14','第一章:HTML',0,'2019-01-01 12:27:40','2019-01-01 12:55:30'),('1181729226915577857','18','第七章:I/O流',70,'2019-10-09 08:32:58','2019-10-09 08:33:20'),('1192252428399751169','1192252213659774977','第一章节',0,'2019-11-07 09:28:25','2019-11-07 09:28:25'),('15','18','第一章:Java入门',0,'2019-01-01 12:27:40','2019-10-09 09:13:19'),('3','14','第二章:CSS',0,'2019-01-01 12:55:35','2019-01-01 12:27:40'),('32','18','第二章:控制台输入和输出',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('44','18','第三章:控制流',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('48','18','第四章:类的定义',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('63','18','第五章:数组',0,'2019-01-01 12:27:40','2019-01-01 12:27:40'),('64','18','第六章:继承',61,'2019-01-01 12:27:40','2019-10-09 08:32:47');
附录
浏览器发送请求给nginx的时候还会默认请求页面的小图标,即favicon.ico,如果没有会生成错误日志error.log;建议弄个图片做favicon.ico,避免生成无关紧要的报错,每个站点目录都要放【这个报错只会显示在错误日志中】
在线画图软件:https://www.processon.com/diagrams,有很多计算机相关的图可以用
IE浏览器右键重加载符号选择不走缓存就可以实现完全不走缓存,chrome似乎没有该功能【chrome也可以,需要打开开发者选项才会拥有该功能,火狐据说不行;chrome有这个功能,但是似乎要浏览器有内存缓存才能使用该功能,不走缓存或者只有磁盘缓存似乎不能使用该功能】
在百度上可以输入ip查询公有ip的服务器物理地址
tomcat的8080本身的欢迎页放在目录
/usr/local/tomcat-9.0.62/webapps/ROOT下。默认的tomcat欢迎页是index.jsp,会优先使用index.htmlchrome的application选项卡下可以直接看浏览器缓存的cookie信息,还可以在该页面清除cookie
工具Spring Tool Suite 4,能够集成一些常用的java工具,如maven、SpringCloud等相关组件,可以学习一下
注意yum下载的nginx没有configure文件
关注一下前端图标的库:https://fontawesome.com/,里面有各种应用图标
浏览器搜索框输入ip就能显示本机Ip或者使用的正向代理服务器的IP
中间件分类
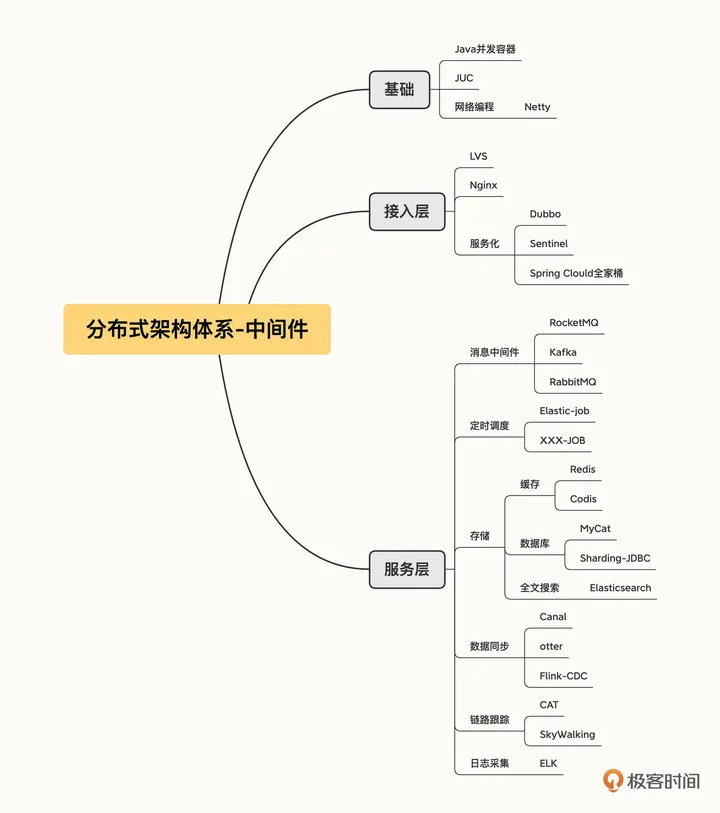
消息中间件
实现分布式系统中可靠的、高效的、实时的跨平台数据传输,是中间件中唯一不可缺少的,是需求量最大的中间件产品
交易中间件
缓存中间件
Web服务器中间件
安全中间件
中间件ChatGPT的回答
中间件有很多种类,主要根据其功能可以分为不同的类型,包括但不限于:
应用服务器中间件:用于提供应用程序运行环境和相关服务,如Tomcat、Jboss、WebSphere等。
消息中间件:用于处理应用程序之间的异步消息传递,如RabbitMQ、Kafka、ActiveMQ等。
数据库中间件:用于解决数据库访问的负载均衡、容错与故障转移等问题,如MySQL Proxy、Oracle Data Guard等。
缓存中间件:用于加快数据访问速度,如Redis、Memcached等。
代理中间件:用于代理网络请求,加强安全性、提高性能等,如Nginx、HAProxy等。
事务中间件:用于处理分布式事务,如TCC-Transaction、Seata等。
身份验证和授权中间件:用于处理用户身份验证和授权,如OAuth、JWT 等。
以上仅是一些常见的中间件类型,实际中还有很多其他类型的中间件,它们在软件系统中扮演着连接、转换或增强功能的重要角色。
带转义符号的sql语句无法被在线json格式化平台解析,但是能够被cjson.decode(res)【这是把json字符串解析成json对象,json字符串是带转义符号的,将json对象处理成json字符串用的是cjson.encode(res)方法】
有个layout经常看到,前端也经常出现,但是没讲,以后自己研究
 毁灭吧,我累了
毁灭吧,我累了